

The Swift Programming Language Documents를 참고해서 정리했습니다.
여러 가지 생각들이 버무러져 있습니다.
contents
️ Strings
String은 연속된 Character들의 모임입니다.
Swift에서는 이러한 문자열(String)을 String 타입으로 표시합니다. String 타입은 Text를 저장하고 조작하는 일을 합니다. C에서 사용하는 것과 유사한 String Literal를 사용하여 가볍고 읽기 편합니다.
String은 String interpolation를 사용해서 String에 상수, 변수, 리터럴, 식을 삽입합니다. 덕분에 display, storage, printing를 위한 커스텀 String 값을 쉽게 생성 가능합니다.
String은 연속된 Character들의 모임이기 때문에 Character 집합을 통해 접근할 수도 있고 그 외 다양한 방식으로 접근 가능합니다.
또한, Unicode와 호환 가능한 방법을 제공합니다. 모든 String은 encoding-independent Unicode Character로 구성되어 있습니다. 따라서, 다양한 Unicode Character에 액세스 가능합니다.
Foundation은 String Type를 extension하여 NSString에 정의된 메서드를 String에서 사용할 수 있도록 했습니다. 따라서, Foundation를 임포트하면 캐스팅할 필요없이 String 타입에서 NSString 메서드를 액세스할 수 있습니다.
Bridging Between String and NSString
String은 Value Type이기 때문에 String 값이 함수, 메서드, 상수, 변수에 들어가게 되면 값이 복사됩니다.
Original String이 아닌 기존 String 값의 새 복사본을 생성하여 할당하게 되는겁니다.
*Structure, Enumeration도 Value Type 입니다.
값으로 전달되기 때문에 전달된 String을 사용자가 직접 수정하지 않는 한 수정되지 않음을 확신할 수 있습니다.
Swift 컴파일러는 String 사용을 최적화하기 위해서 실제 복사가 절대적으로 필요한 경우에만 수행되도록 합니다. 따라서, String 타입을 Value Type으로 사용할 때 항상 우수한 성능을 얻을 수 있습니다.
️ String literals
String에서는 “”로 둘러싸인 문자를 String literal로 사용합니다.
아래의 someString 상수는 String literal를 초기값으로 사용했기에 String 타입으로 추론됩니다.
let someString = "Hello, World!"
Swift
복사
만약, 여러 줄짜리 문장을 저장해야 한다면, Single line으로 작성하기 힘들겁니다. 이런 경우에는 """ 기호를 사용해서 String를 둘러싸는 겁니다.
let multiLineString = """
The White Rabbit put on his spectacles. "Where shall I begin,
please your Majesty?" he asked.
"Begin at the beginning," the King said gravely, "and go on
till you come to the end; then stop."
"""
Swift
복사
""" 를 사용해서 여러 줄짜리 문장을 작성하면 줄바꿈도 포함되어서 나타납니다. 만약, 줄바꿈을 사용하고 싶지 않다면 해당 줄 끝에 \ 를 사용하면 됩니다.
let multiLineString = """
The White Rabbit put on his spectacles. "Where shall I begin, \
please your Majesty?" he asked.
"Begin at the beginning," the King said gravely, "and go on \
till you come to the end; then stop."
"""
Swift
복사
여러 줄의 문장은 종료 """ 에 맞춰서 들여쓰기가 적용됩니다. 따라서, 들여쓰기를 적용하고 싶다면 마지막 """ 의 위치에 맞춰서 들여쓰기를 적용하면 됩니다.
let multiLineString = """
The White Rabbit put on his spectacles. "Where shall I begin,
please your Majesty?" he asked.
"Begin at the beginning," the King said gravely, "and go on
till you come to the end; then stop."
"""
Swift
복사
위의 코드에서 실제로 들여쓰기 적용된 문장은 please your Majesty?" he asked. 일 겁니다. 다른 문장은 모두 마지막 """ 과 같은 줄에서 시작했는데 두 번째 문장은 해당 줄보다 뒤에서 시작되었기 때문입니다.
String literal에서는 Special Character도 포함할 수 있습니다.
Special Character 앞에 \ 기호를 추가하여 String literal에 넣어주면 됩니다.
let specialCharacters = "\0 \\ \t \n \r \" \'"
print(specialCharacters)
Swift
복사
Unicode도 \u{n} 형식으로 써주면 String 값으로 사용할 수 있습니다.
*n에 들어가는 값은 1~8 digit hexadecimal number 입니다.
let sparklingHeart = "\u{1F496}"
print(sparklingHeart)
Swift
복사

만약, \u{1F496} 를 String Literal로 출력해야 하는 상황이 있다면 어떻게 해야 할까요?
이럴 때는 extended delimiter 내에 String literal를 배치하면 됩니다. “”를 # 기호로 둘러싸는 겁니다.
이렇게 하면 특수 효과가 적용되지 않습니다.
let sparklingHeartUnicode = #"\u{1F496}"#
print(sparklingHeartUnicode)
Swift
복사

하지만, # 기호로 둘러싸인 String literal 내부에서도 특수 기호가 적용되어야 하는 상황이 있을겁니다. 이런 상황에서는 해당 기호의 백슬래시(\)와 특수 기호 사이에 # 기호를 삽입해주면 됩니다.
*#은 여러 개 사용할 수 있기 때문에 숫자를 꼭 맞춰서 사용해주어야 합니다.
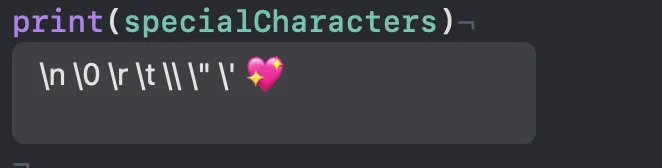
let specialCharacters = ##"\n \0 \r \t \\ \" \' \##u{1F496}"##
print(specialCharacters)
Swift
복사
## 기호를 넣어준 Unicode 부분만 특수 기호로 나온 걸 볼 수가 있죠. (๑ᵒ ᗜ ᵒ)و ̑✧
️ Handling the String
Initializing an Empty String
Empty String를 만드는 방법은 2가지가 있습니다.
var emptyString = "" // empty string literal
var anotherEmptyString = String() // initializer syntax
Swift
복사
String Type은 isEmpty 속성으로 해당 타입 값이 비었는지 확인할 수 있습니다.
if emptyString.isEmpty {
print("Nothing to see here")
}
// Prints "Nothing to see here"
Swift
복사
Accessing and Modifying a String
String은 변수에 값을 할당하여 이후 수정할 수 있도록 할 수 있습니다. 상수에 String 값을 할당했을 경우에는 이후에 수정하고 싶어도 수정 불가능합니다. 컴파일 에러를 발생시킵니다.
Swift에서 사용하는 String은 NSString, NSMutableString 중에 선택하여 문자열 변환을 할 수 있는지 확인하는 Objective-C, Cocoa 문자열 변환 방식과는 다릅니다.
String은 method, property, subscript를 사용하여 String에 접근하고 수정할 수 있습니다.
String Indices
String 값에는 String 내 Character 위치를 나타내는 String.Index 타입이 있습니다.
Character 마다 저장하고 있는 메모리 양이 다를 수 있기 때문에 특정 위치에 있는 Character 확인하려면 해당 String 시작, 끝에서 Unicode Scalar를 반복해야 합니다.
이러한 이유로 String를 정수 값으로 인덱싱할 수 없습니다.
정수 값으로 인덱싱할 수 없다구요?
String 타입의 값을 Int로 접근하려고 하면 이런 에러를 만날 수 있습니다.
error: 'subscript(_:)' is unavailable: cannot subscript String with an Int, use a String.Index instead.
String 타입의 값을 접근하려면 Int 타입이 아닌 String.Index 타입으로 접근해야 합니다. 그 이유는 위에서 말한 Character 마다 저장하고 있는 메모리 양이 다른 문제 때문입니다. 메모리 양이 다른 이유는 String literal에 들어가는 Character에 일반적인 Character도 있지만 특수 기호도 존재하기 때문입니다. 그런 기호들은 일반 Character들보다 더 많은 메모리를 요구할 수도 있습니다.
String 맨 앞에 위치한 Character 값에 접근하기 위해서는 startIndex 속성을 사용하면 됩니다. 반대로 맨 뒤에 위치한 Character 값에 접근하기 위해서는 endIndex 속성을 사용하면 됩니다.
let greeting = "Guten Tag!"
greeting[greeting.startIndex] // G
greeting[greeting.endIndex] // error
Swift
복사
위의 코드에서 endIndex를 사용한 부분은 에러를 발생시킵니다.
why?
String은 subscript 를 사용해서 특정 Index에 있는 Character에 접근할 수 있는데, String의 범위 밖이나 범위 밖에 있는 Character를 접근하려고 하면 runtime error를 발생시킵니다.
endIndex 는 String의 마지막 문자 뒤에 위치합니다. 따라서, greeting[greeting.endIndex] 은 유효하지 않은 값을 나타냅니다.
그렇다면, endIndex를 나타내고 싶다면 어떻게 해야 할까요?
String은 index 메서드를 제공합니다.index(before:), index(after:) 메서드를 사용해서 전후 index에 접근할 수 있습니다. 따라서, index(before:) 메서드를 사용하면 endIndex에 접근할 수 있습니다.
greeting[greeting.index(before: greeting.endIndex)] // !
Swift
복사
또한, 멀리 떨어진 index는 index(_:offsetBy:) 메서드를 사용해서 접근할 수 있습니다.
let index = greeting.index(greeting.startIndex, offsetBy: 7)
greeting[index] // a
Swift
복사
String에는 indices 속성이 있습니다. 해당 속성을 사용해서 String에 포함된 Character에 접근할 수 있습니다. indices의 Element인 index 는 Index 타입이기 때문에 subscript 안에 넣을 수 있습니다.
for index in greeting.indices {
print("\(greeting[index]) ", terminator: "")
}
Swift
복사
String Type은 Collection 프로토콜을 준수합니다. 그렇기 때문에 Collection 프로토콜에서 제공하는 startIndex, endIndex, index 메서드를 사용할 수 있는겁니다.
Collection 프로토콜을 준수하는 타입들은 해당 속성과 메서드를 필수적으로 구현해야 하기 때문에 그렇습니다.
즉, Collection 프로토콜을 준수하는 Array, Dictionary, Set도 동일하게 해당 속성과 메서드를 사용할 수 있습니다.
Inserting and Removing
Character 타입의 값을 String 안에다가 넣고 싶다면 insert(at:) 메서드를 사용하면 됩니다. 반대로 제거하고 싶다면 remove(at:) 메서드를 사용하면 됩니다.
var welcome = "hello"
welcome.insert("!", at: welcome.endIndex) // hello!
welcome.remove(at: welcome.index(before: welcome.endIndex)) // hello
Swift
복사
*endIndex는 String의 마지막 문자 뒤에 위치하기 때문에 o 뒤에 ! 가 위치할 수 있는겁니다.
String 타입의 값을 String 안에다가 넣고 싶다면 insert(contentsOf:at:) 메서드를 사용하면 됩니다. 반대로 제거하고 싶다면 removeSubrange(_:) 메서드를 사용하면 됩니다.
var welcome = "hello"
welcome.insert(contentsOf: " there", at: welcome.endIndex) // hello there
let range = welcome.index(welcome.endIndex, offsetBy: -6)..<welcome.endIndex
welcome.removeSubrange(range) // hello
Swift
복사
String Type은 RangeReplaceableCollection 프로토콜을 준수합니다. 그렇기 때문에 RangeReplaceableCollection 프로토콜에서 제공하는 insert, remove, removeSubrange 메서드를 사용할 수 있는겁니다.
즉, RangeReplaceableCollection 프로토콜을 준수하는 Array도 동일하게 해당 속성과 메서드를 사용할 수 있습니다.

*String and Character Document에는 Array 말고도 Set, Dictionary도 사용 가능하다고 했으나 Set, Dictionary는 RangeReplaceableCollection 프로토콜을 준수하지 않습니다. 따라서, insert, remove, removeSubrange 메서드를 사용할 수 없습니다. 왜 Document에는 준수한다고 작성되어 있는걸까요..
왜 Document에는 준수한다고 작성되어 있는걸까요..
stackoverFlow에 같은 질문으로 궁금해하는 분을 봤는데, 아무래도 복붙 오류 같다는 의견이네요..
Substring
String으로부터 Substring를 가져오면 Substring 인스턴스가 됩니다.
let greeting = "Hello, world!"
let index = greeting.firstIndex(of: ",") ?? greeting.endIndex
let beginning = greeting[..<index] // Hello
Swift
복사
위 코드에서 beginning 상수가 Substring 타입입니다.
하지만, String 처럼 긴 시간동안 사용할 순 없습니다. 짧게 사용해야만 합니다.
만약, 긴 시간동안 Substring의 값을 사용하고 싶다면 String으로 변환 후 String 타입의 값으로 저장하여 사용해야 합니다.
왜 String으로 변환해야 하나요?
성능 최적화 문제 때문입니다.
Substring도 문자가 저장되는 메모리 영역이 존재합니다. Substring은 원래 String이 저장되는 메모리 일부나 다른 Substring를 저장했던 메모리 일부를 재사용합니다.
즉, Substring은 원래 String이 저장되는 메모리를 차지하고 있기 때문에 Substring이 사용되는 동안은 전체 원본 String를 메모리에 저장해야 합니다.
위의 코드에 Substring를 String 타입으로 변환한 값을 저장한 newString 상수를 만들겠습니다.
let greeting = "Hello, world!"
let index = greeting.firstIndex(of: ",") ?? greeting.endIndex
let beginning = greeting[..<index]
let newString = String(beginning)
Swift
복사
greeting 상수를 구성하는 문자는 메모리 영역에 있습니다. beginning이라는 greeting의 Substring 타입이 생기면서 greeting의 메모리 영역을 재사용하게 됩니다.
beginning를 String 타입으로 변환하여 newString 상수의 값으로 할당했습니다. newString은 String 타입이기 때문에 자체 저장소를 가지고 있습니다. 따라서, Substring를 포함하는 원래 String에 구애받지 않고 자체 저장소에 넣어서 사용할 수 있습니다.

️ String Interpolation
String literal 내에 상수, 변수, 리터럴, 식 값을 포함해서 새로운 문자열 값을 구성할 수 있는 방법이 있습니다.
바로, \() 의 괄호 안에 해당 값을 넣어주는 겁니다.
let multiplier = 3
let message = "\(multiplier) times 2.5 is \(Double(multiplier) * 2.5)"
// 3 times 2.5 is 7.5
Swift
복사
위의 코드처럼 \() 안에 상수, 변수, 리터럴, 식을 넣어주면 실제 String이 생성될 시에 실제 값으로 대체시켜줍니다.
print(#"Write an interpolated string in Swift using \(multiplier)."#)
Swift
복사
물론, String literal에서와 동일하게 \ 뒤에 # 기호를 넣어주면 extended delimiter 안에서도 값을 대체시켜서 사용할 수 있습니다.
print(#"6 times 7 is \#(6 * 7)."#)
// 6 times 7 is 42.
Swift
복사
\() 괄호 안에서도 사용하지 못하는 것들이 있는데 unescaped \, \r(carriage return), \n(line feed) 입니다.
️ Working with Characters
String 타입을 for-in loop 안에 넣어서 각각의 Character 타입에 접근할 수 있습니다.
for character in "Dog!🐶" {
print(character)
}
// D
// o
// g
// !
// 🐶
Swift
복사
단일 Character literal를 사용해서 Character 타입의 변수나 상수를 만들 수도 있습니다.
let exclamationMark: Character = "!"
Swift
복사
String 섹션에서 말한 것처럼 Character 배열을 String 이니셜라이저의 인수로 넣어서 String 타입을 생성할 수도 있습니다.
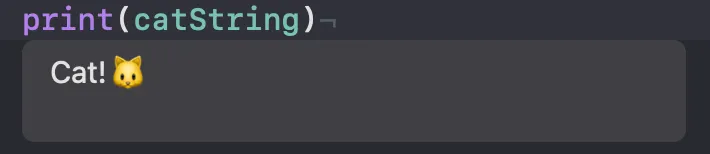
let catCharacters: [Character] = ["C", "a", "t", "!", "🐱"]
let catString = String(catCharacters)
print(catString)
Swift
복사
귀여운 고양이가 나왔네요. ₍ᐢ. ̫.ᐢ₎
Concatenating Strings and Characters
String은 + 기호를 사용해서 두 String를 합칠 수 있습니다. addition assignment operator(+=)를 사용해서 같은 기능을 하게 만들 수도 있죠.
let string1 = "hello"
let string2 = " there"
var welcome = string1 + string2 // hello there
var instruction = "look over"
instruction += string2 // look over there
Swift
복사
Character 타입은 append() 메서드를 사용해서 String 변수 끝에 넣을 수도 있습니다.
let exclamationMark: Character = "!"
welcome.append(exclamationMark) // hello there!
Swift
복사
반면에, Character 타입에는 단일 Character 타입의 값만 포함되어야 하기 때문에 String, Character를 추가할 수 없습니다. 애초에 Character 타입에서는 String 타입에 있는 append, insert 같은 삽입 메서드가 없습니다.
여러 줄의 String 값을 사용한다고 하면 앞에 연결할 String의 마지막 줄이나 뒤에 연결할 String의 첫 번째 줄이 줄 바꿈(\n)으로 끝나야 합니다.
let goodStart = """
one
two
"""
let end = """
three
"""
print(goodStart + end)
// one
// two
// three
Swift
복사
Unicode
Unicode는 서로 다른 Writing System에서 Text Encoding, Representing, Processing하기 위한 국제 표준 입니다. 모든 언어의 거의 모든 문자를 표준화된 형태로 표현할 수 있고 Text 파일, 웹 페이지 같은 외부 소스에서 해당 문서를 읽고 쓰기 가능하게 해줍니다.
String, Character 타입은 Unicode와 호환됩니다.
Unicode Scalar Values
Swift 기본 String 타입은 Unicode Scalar Value로 작성되었습니다.
Unicode Scalar Value는 Charactert, Modifier에 대한 Unique한 21-bit 숫자 입니다.
따라서, “a”는 U+0061로 나타낼 수 있고, “”는 U+1F425로 나타낼 수 있습니다.
”는 U+1F425로 나타낼 수 있습니다.하지만, 모든 Unicode Scalar 값이 문자에 할당되지 않습니다. 아직 할당되지 않은 문자 중에 할당되기 위해서 예약되어 있는 상태입니다. 위에 있는 “a”나 “”는 Unicode Scalar Value로 할당되어 있기에 21-bit로 나타낼 수 있는 거겠죠?
”는 Unicode Scalar Value로 할당되어 있기에 21-bit로 나타낼 수 있는 거겠죠?Extended Grapheme Clusters
Swift의 Character 타입 인스턴스는 단일 Extended grapheme cluster로 나타냅니다.
Extended grapheme cluster는 하나 이상의 Unicode Scalar Value로, 결합된 경우 사람이 읽을 수 있는 단일 문자가 생성됩니다.
예를 들어서, é 라는 문자가 있을 때, Single Unicode Scalar로 é 를 나타낼 수 있습니다. 또한, e와 악센트 문자를 합쳐서 Two Unicode Scalars로 é 를 나타낼 수 있습니다.
let eAcute: Character = "\u{E9}" // é
let combinedEAcute: Character = "\u{65}\u{301}" // e followed by ́
Swift
복사
e와 악센트 문자를 합친 경우에는 Unicode-aware text-rendering system에 의해서 렌더링될 때 é 가 됩니다. 두 경우 모두 결론적으로 é 라는 single Character로 나타납니다.
Extended Grapheme Cluster는 복잡한 스크립트 문자를 single Character로 표시할 수 있는 방법입니다.
예를 들어서, 한글을 사용하는 경우가 있습니다.
한 이라는 Character는 한 이라는 Single Unicode Scalar로 나타낼 수도 있지만, ㅎ, ㅏ, ㄴ 이라는 Unicode Scalars를 결합하여 만들 수도 있습니다. 두 경우 모두 결론적으로 한 이라는 single Character를 만듭니다.
Counting Characters
String를 구성하는 Character의 갯수를 알고 싶을 때는 count 속성을 사용합니다.
let unusualMenagerie = "Koala 🐨, Snail 🐌, Penguin 🐧, Dromedary 🐪"
print("unusualMenagerie has \(unusualMenagerie.count) characters")
// unusualMenagerie has 40 characters
Swift
복사
위에서 Extended Grapheme Cluster는 여러 Unicode Scalar를 합쳐서 만들 수 있다고 했습니다.
e와 악센트 문자를 합친 é 는 2개의 Character가 합쳐져서 생긴 것일 수도 있습니다.
그렇다면, count가 2로 측정될까요?
아닙니다. Extended grapheme cluster를 사용한다고 해서 count에 영향을 끼치지 않습니다.
예를 들어서, cafe라는 단어에 악센트 문자를 붙여서 café로 만든다고 해봅시다.
var word = "cafe"
print("the number of characters in \(word) is \(word.count)")
// the number of characters in cafe is 4
word += "\u{301}" // COMBINING ACUTE ACCENT, U+0301
print("the number of characters in \(word) is \(word.count)")
// the number of characters in café is 4
Swift
복사
cafe, café 모두 4글자로 카운팅됩니다. 악센트 기호는 count에 영향을 끼치지 않기 때문이겠죠.
보시다시피, single Character지만 여러 Unicode Scalar Value가 합쳐진 Character일 수가 있습니다. 그 말은즉슨, Swift의 Character는 String 내에서 모두 같은 메모리를 차지하지 않고 있다는 뜻입니다.
그렇기 때문에, 정수값으로 인덱싱할 수 없는 겁니다.
String의 Character 수는 반복문 안에서 extended grapheme cluster의 경계를 결정하지 않고서는 계산이 불가능합니다.
또한, NSString와 String에 같은 Text가 포함되어 있다고 해도 Count 수가 다를 수 있습니다.
NSString의 길이는 Unicode extended grapheme cluster의 수가 아니라 16-bit code unit 수를 기준으로 하기 때문에 그렇습니다.
Comparing
Swift에서는 String&Character equality, Prefix equality, Suffix equality 세가지 텍스트 비교 방법을 제공합니다.
String and Character equality
Swift의 비교 연산자(==, !=)를 사용해서 동일한지 체크할 수 있습니다.
extended grapheme clusters가 동일하다면 같은 값으로 간주합니다. 뒤에 다른 Unicode Scalar Value가 와도 언어적 의미나 모양이 같다면 동일하게 취급합니다.
// Voulez-vous un café?
let eAcuteQuestion = "Voulez-vous un caf\u{E9}?"
// Voulez-vous un café?
let combinedEAcuteQuestion = "Voulez-vous un caf\u{65}\u{301}?"
if eAcuteQuestion == combinedEAcuteQuestion {
print("These two strings are considered equal")
}
// These two strings are considered equal
Swift
복사
위의 코드에선 é 와 e + 악센트 기호 의 모양이 같고 동일한 언어적 의미를 지니기 때문에 같은 값으로 간주됩니다. 하지만, 같은 모양에 다른 언어적 의미를 지닌 A 라는 Character를 볼게요.
let latinCapitalLetterA: Character = "\u{41}"
let cyrillicCapitalLetterA: Character = "\u{0410}"
if latinCapitalLetterA != cyrillicCapitalLetterA {
print("These two characters aren't equivalent.")
}
// Prints "These two characters aren't equivalent."
Swift
복사
둘 다 모양은 “A”지만 언어적 의미가 다릅니다. 따라서, 다른 값으로 간주됩니다.
*Swift에서의 String, Character는 locale-sensitive하지 않습니다.
Prefix, Suffix equality
Swift는 특정 문자열 Prefix, Suffix를 확인할 수 있는 메서드가 있습니다.
hasPrefix(), hasSuffix() 입니다.
두 메서드 모두 Boolean 값을 반환합니다. 해당 메서드들도 extended grapheme cluster가 같은지 비교하여 Boolean 값을 반환합니다.
Scene에 대한 String를 저장한 배열이 있다고 할 때,
let romeoAndJuliet = [
"Act 1 Scene 1: Verona, A public place",
"Act 1 Scene 2: Capulet's mansion",
"Act 2 Scene 1: Outside Capulet's mansion",
"Act 2 Scene 2: Capulet's orchard",
"Act 2 Scene 3: Outside Friar Lawrence's cell",
]
Swift
복사
Act 1 이 얼마나 나왔는지 확인하면, hasPrefix 를 사용해서 카운팅할 수 있습니다.
var act1SceneCount = 0
for scene in romeoAndJuliet {
if scene.hasPrefix("Act 1 ") {
act1SceneCount += 1
}
}
print("There are \(act1SceneCount) scenes in Act 1")
// There are 2 scenes in Act 1
Swift
복사
Capulet's mansion 와 Friar Lawrence's cell 문자열이 얼마나 나왔는지도 hasSuffix 를 사용해서 카운팅할 수 있습니다.
var mansionCount = 0
var cellCount = 0
for scene in romeoAndJuliet {
if scene.hasSuffix("Capulet's mansion") {
mansionCount += 1
} else if scene.hasSuffix("Friar Lawrence's cell") {
cellCount += 1
}
}
print("\(mansionCount) mansion scenes; \(cellCount) cell scenes")
// 2 mansion scenes; 1 cell scenes
Swift
복사
️ Unicode Representations of Strings
Unicode는 Unicode 부분에서 얘기했듯 서로 다른 Writing System에서 Text Encoding, Representing, Processing하기 위한 국제 표준 입니다.
Unicode String은 텍스트 파일이나 저장소에 쓸 때에 여러 Unicode 인코딩 형식 중 하나로 인코딩 됩니다.
UTF-8, UTF-16, UTF-32 형식으로 말이죠.
String의 Unicode 표현에 접근하는 몇 가지 방법을 제공해드리겠습니다.
세 가지 Unicode 호환 형식 중 하나의 값으로 액세스할 수 있습니다.
UTF-8
utf8 속성을 반복하여 String의 UTF-8 표현에 접근할 수 있습니다.
해당 속성은 String.UTF8View 타입입니다. 해당 타입은 UInt8 값의 집합으로 나타냅니다.
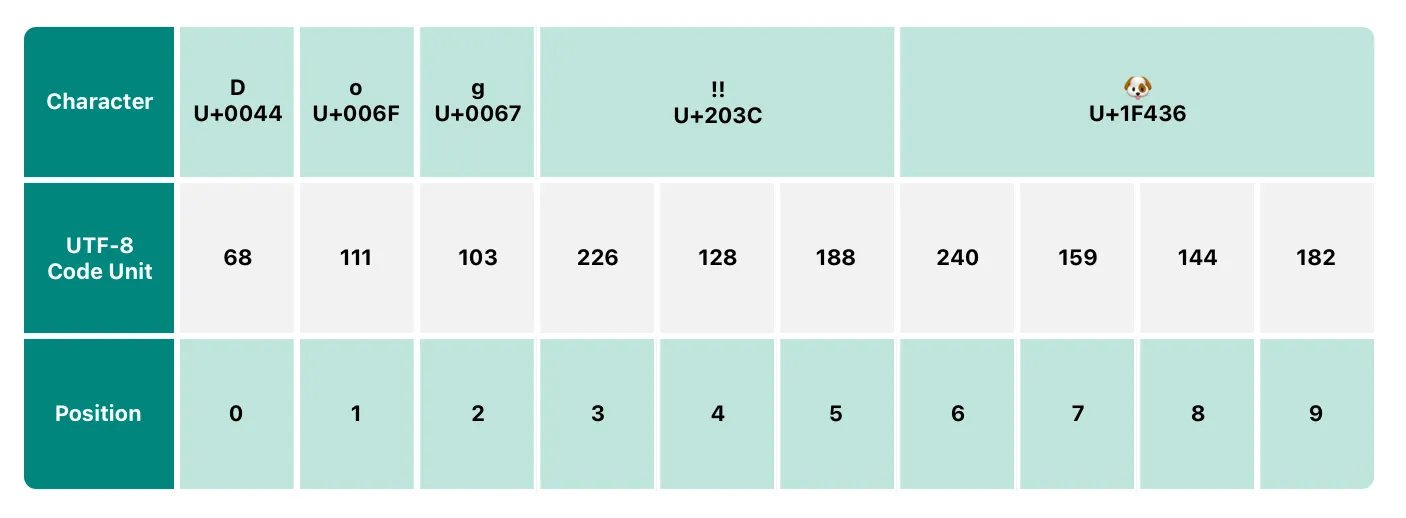
let dogString = "Dog‼🐶"
for codeUnit in dogString.utf8 {
print("\(codeUnit) ", terminator: "")
}
print("")
// 68 111 103 226 128 188 240 159 144 182
Swift
복사
각각의 Character를 UTF-8 표현으로 나타낸 겁니다.
UTF-16
utf16 속성을 반복하여 String의 UTF-16 표현에 접근할 수 있습니다.
해당 속성은 String.UTF16View 타입입니다. 해당 타입은 UInt16 값의 집합으로 나타냅니다.
for codeUnit in dogString.utf16 {
print("\(codeUnit) ", terminator: "")
}
print("")
// 68 111 103 8252 55357 56374
Swift
복사
각각의 Character를 UTF-16 표현으로 나타낸 겁니다.

UTF-32(Unicode Scalar Representation)
unicodeScalars 속성을 반복하여 String의 UnicodeScalar 표현에 접근할 수 있습니다.
해당 속성은 UnicodeScalarView 타입입니다. 해당 타입은 UnicodeScalar 값의 집합으로 나타냅니다.
각 UnicodeScalar는 UInt32 값 내에 표시되는 scalar의 21-bit value를 반환하는 value 속성을 가집니다.
for scalar in dogString.unicodeScalars {
print("\(scalar.value) ", terminator: "")
}
print("")
// 68 111 103 8252 128054
Swift
복사
각각의 Character를 UTF-32, 즉 Unicode Scalar 표현으로 나타낸 겁니다.

value 속성을 대신하여 UnicodeScalar 값을 사용해 값을 나타낼 수도 있습니다.
for scalar in dogString.unicodeScalars {
print("\(scalar) ", terminator: "")
}
// D o g ‼ 🐶
Swift
복사
️ Performance Optimizations
Swift에 있는 String은 Value semantic 입니다. 즉, Value Type이기에 값을 복사하는 식으로 사용하게 됩니다. 그렇기 때문에 복사 받은 변수에 영향을 받지 않습니다.
하지만, String은 Copy-On-Write 전략을 사용해서 데이터를 버퍼에 저장합니다.
Copy-On-Write 전략은 리소스 관리 기법 중 하나 입니다. Copy-On-Write를 사용하게 되면 값을 복사했을 때 복사본이 수정되지 않으면 새 리소스를 만들 필요없이 복사본과 원본이 같은 리소스를 공유하게 됩니다. 만약, 복사본이 수정되게 된다면 새 리소스를 만들게 되죠.
그렇기 때문에 String이 버퍼를 다른 복사본과 공유하게 됩니다.
둘 이상의 String 인스턴스가 동일한 버퍼를 사용하게 되면, String data를 변환하게 될 시에 느리게 복사됩니다.
따라서, mutating operation Sequence에서 O(n)의 시간, 공간 복잡도가 소요됩니다.
String의 연속 저장소는 저장소가 다 채워지면 새로운 버퍼를 할당하고 새로운 저장소로 데이터를 이동해야 합니다. String 버퍼는 지수 성장 전략(exponential growth strategy)을 사용합니다. 그렇기 때문에 일정한 시간에 String를 추가로 만들어주어 많은 추가 작업의 성능을 평균화해줍니다.
Array도 연속 저장소를 사용하는데 저장소가 다 채워지면 더 큰 메모리 영역을 재할당하고 새 저장소로 복사한다고 합니다. 이 때, String과 동일하게 exponential growth 정책을 사용한다고 하네요.