
“[우아한테크세미나] 190620 우아한 객체지향 by 우아한형제들 개발실장 조영호님” 영상을 바탕으로 정리를 진행했습니다. 영상을 보고 싶으신 분들은 하단 링크를 참고해주세요.


들어가며
설계에 대한 이야기를 하다보면 다양한 이야기가 나오지만 핵심은 의존성입니다.
의존성을 어떻게 잡는가에 따라서 설계의 모양이 굉장히 많이 바뀝니다. 하지만, 코드 리뷰 시에 의존성 얘기를 하는 경우는 극히 적습니다. 객체 지향에서 역할이나 책임에 대한 얘기를 많이 합니다. 하지만, 실질적으로 역할이나 책임이 필요한 건 의존성을 어떻게 관리하는가 입니다.
어떻게 의존성을 관리하는게 좋은 의존성이고, 의존성 관리하는 방법에 따라서 설계가 어떻게 바뀌는지 살펴보겠습니다.
의존성(Dependency)
설계는 코드를 어떻게 배치할 것인가에 대해 의사결정을 하는 겁니다.
“어떤 클래스에 어떤 코드를 넣을거고”, “어떤 패키지에 어떤 코드를 넣을거고”, “어떤 프로젝트에 어떤 코드를 넣느냐”에 따라서 설계의 모양이 굉장히 많이 바뀌게 됩니다.
그러면, 어디다가 어떤 코드를 넣어야 할까요?
변경에 초점을 맞춰야 합니다. 같이 변경되는 코드는 같이 넣어야 하고, 같이 변경되지 않는 코드는 따로 넣어야 합니다. 변경의 핵심은 의존성입니다.
의존성이 뭘까요?
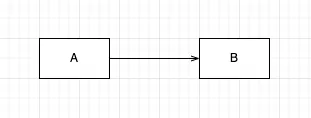
A가 B에 의존한다고 가정해보겠습니다. 그렇다면, B가 변경될 시에 A도 같이 변경될 수 있습니다.
어떤 게 변경될지는 모릅니다. 클래스 이름, 메소드 이름, 근원이 바뀔 수도 있습니다. 뭐가 되었던지 간에 B가 바뀌면 A도 바뀔 수 있는 가능성이 있다는게 의존성입니다. 의존성은 변경과 관련이 있습니다.
그럼 의존성이 있다면 무조건 바뀔까요?
그렇지 않습니다. 클래스 내부의 구현이 변경되더라도 A에 영향을 주지 않을 수도 있습니다.
어떻게 영향을 주지 않을 수 있나요?
설계를 잘하면 됩니다.
의존성은 “변경에 의해서 영향을 받을 수 있는 가능성”을 말합니다. 의존성은 클래스 사이나, 패키지 사이에서 발생할 수 있습니다.
⓵ 클래스 사이 의존성
1.
연관관계
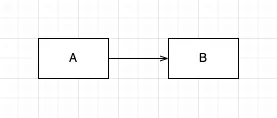
연관관계에 있으면 A에서 B로 이동할 수 있음을 뜻합니다. 아예 A에서 B로 영구적으로 갈 수 있는 경로가 존재하는 경우가 연관관계 입니다.
class A {
private let b = B()
}
Swift
복사
A클래스에 객체 참조로 존재하는 B클래스는 A에서 B로 영구적으로 갈 수 있는 경로입니다.
2.
의존관계
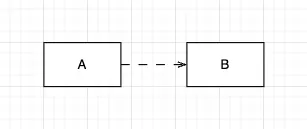
일시적으로 협력하는 어떤 시점에 관계를 맺고 헤어지는 관계입니다.
class A {
public func methodB(b: B) -> B {
return B()
}
}
Swift
복사
메서드의 파라미터나 반환 타입으로 해당 타입이 나오거나, 메서드 안에서 해당 타입의 인스턴스를 생성하는 경우에 해당 타입과 일시적으로 협력했다고 볼 수 있습니다.
3.
상속관계
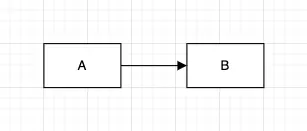
B를 A가 상속받게 되면, B의 구현을 A가 상속받는 뜻입니다. 따라서, B가 바뀌면 A도 같이 변경되게 됩니다.
class B { }
class A: B { }
Swift
복사
4.
실체화관계
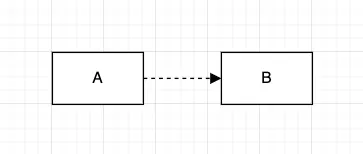
A가 B라는 인터페이스를 implement하는 관계입니다.
protocol B { }
class A: B { }
Swift
복사
상속과 실체화 관계는 차이가 존재합니다. 상속관계는 구현이 바뀌면 영향을 받습니다. B의 구현이 바뀌면 B를 상속받고 있는 A의 구현도 변경될 가능성이 존재합니다.
실체화관계는 인터페이스의 Operation 시그니처가 바뀌었을 때만 영향을 받습니다. 즉, B라는 인터페이스 내부에 있는 메서드나 속성의 이름, 타입 등이 바뀌었을 때만 영향을 받게 됩니다.
⓶ 패키지 사이 의존성
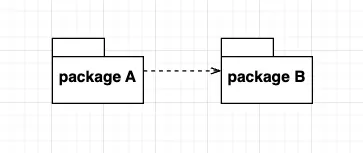
패키지 A가 패키지 B에 의존한다는 건 패키지 B에 있는 클래스가 변경될 때, 패키지 A안에 있는 클래스가 바뀔 수 있다는 걸 의미합니다. 어떤 패키지 안의 클래스가 다른 패키지 안의 클래스에 의존성이 있으면 해당 클래스를 가지고 있는 두 패키지 간의 의존성이 있다고 봅니다.
그럼, 두 패키지가 의존하고 있는지 어떻게 확인할 수 있나요?
클래스를 열었을 때, import에 다른 패키지의 이름이 있다면 dependency가 있는겁니다.
의존성 관리 방법
우리는 의존성을 어떻게 관리할 수 있을까요? 설계 시에 좋은 의존성을 관리하는 몇 가지 규칙이 있습니다.
1.
양방향 의존성을 피해야 합니다.
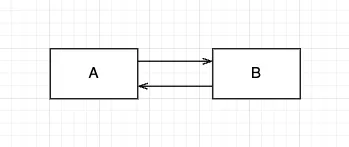
의존성 정의에 의하면 B가 바뀔 때, A도 바뀌고, A가 바뀔때, B도 바뀌어야 합니다. 즉, 하나의 클래스라고 봐도 무방한걸 어거지로 찢어놓는 것과 마찬가지 입니다.
class B {
private var a = A()
func setA(_ a: A) {
self.a = a
}
}
class A {
private var b = B()
func setA(_ b: B) {
self.b = b
self.b.setA(self)
}
}
Swift
복사
self.b.setA(self)에서 항상 a와 b 사이의 관계를 동기화해주어야 합니다. 그 이외에도 신경써야 하는 부분들이 굉장히 많아지게 됩니다. 성능 이슈나 동기화 버그가 발생할 수도 있습니다.
그렇기 때문에, 가급적이면 양방향 의존성을 피할 수 있으면 단방향으로 바꿔야 합니다.
2.
다중성이 적은 방향을 선택해야 합니다.
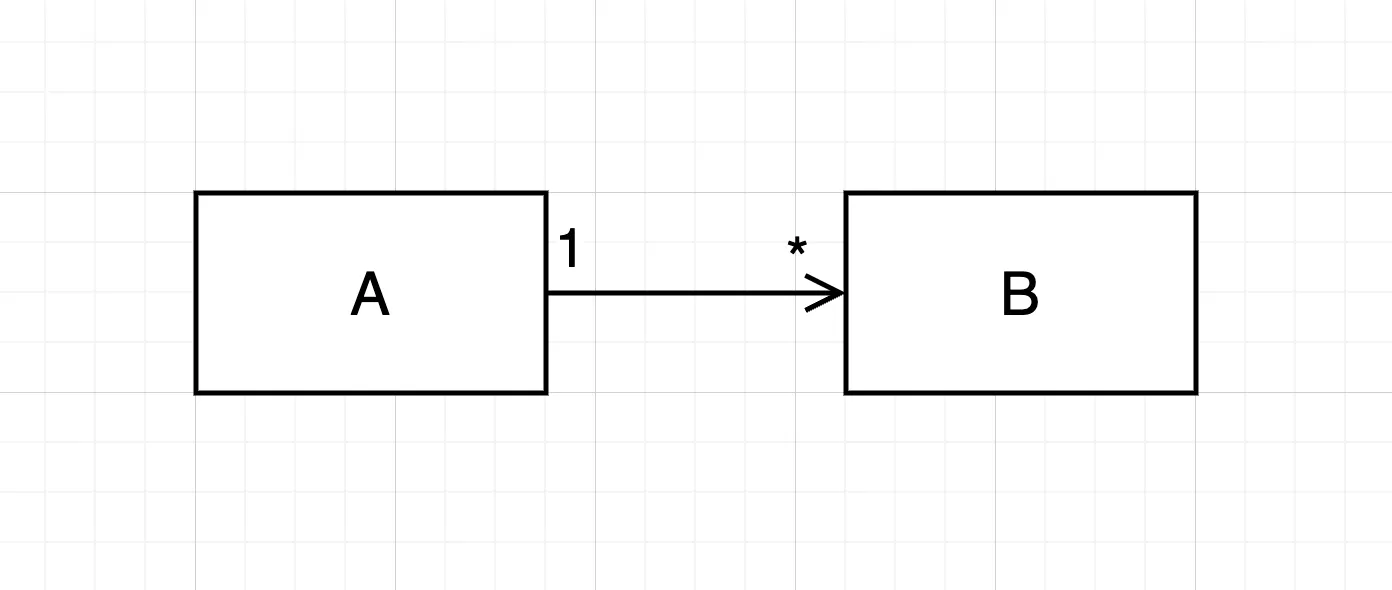
A에서 B타입의 콜렉션에 의존성을 가지는 것보다는 반대 방향의 의존성을 가지도록 코드를 작성하는게 좋습니다.
class A {
private let bs: [B] = []
}
Swift
복사
List, Collection, Set같은 걸 변수로 가지게 되면 굉장히 다양한 이슈가 발생하게 됩니다. 성능 이슈가 발생하게 되며, 그 객체들의 관계를 유지하기 위해서 많은 노력을 해야 합니다.
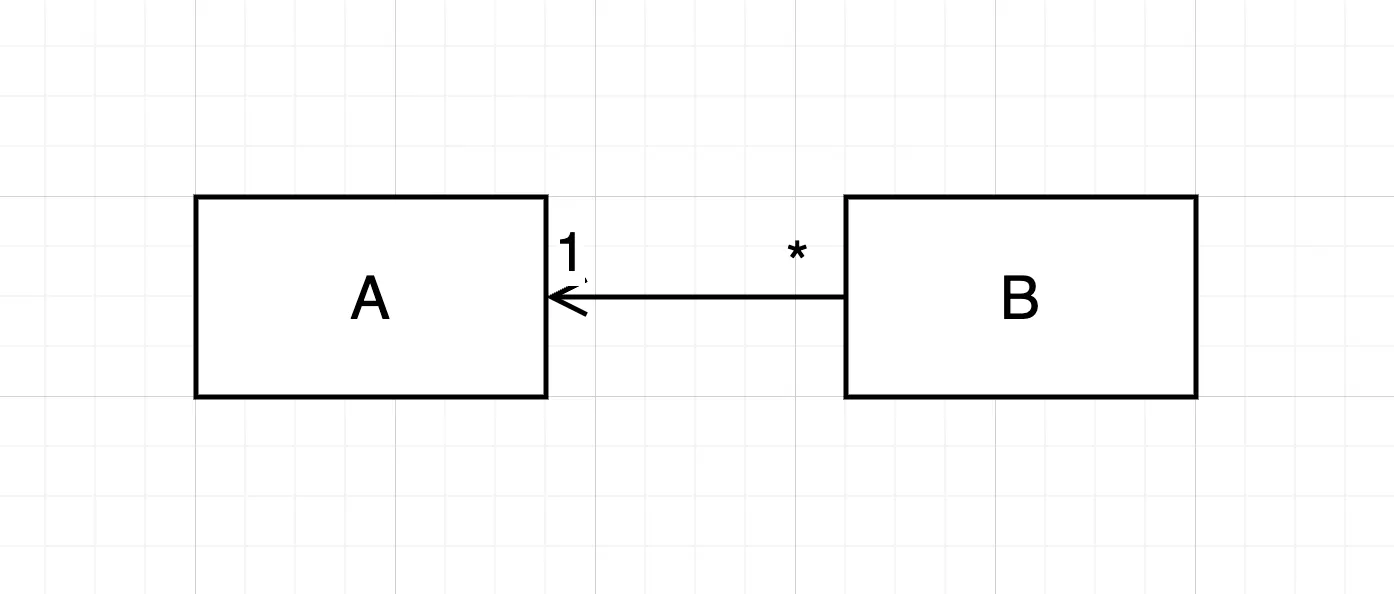
따라서, 가급적이면 A가 B의 리스트를 가지게 하는 것보다는 B가 A의 단방향 참조를 하나 가지는 것이 가장 좋습니다. 즉, 다중성이 적은 의존성 방향을 선택하는 것이 좋습니다.
class B {
private let a = A()
}
Swift
복사
3.
의존성이 필요없다면 제거해야 합니다.
A와 B 사이에 존재하는 의존성이 불필요하다면, 제거하는게 가장 좋습니다.
4.
패키지 사이의 의존성 사이클은 제거해야 합니다.
패키지 사이에는 양방향 의존성이 있으면 안됩니다.
예를 들어서, 패키지가 3개 있다고 해봅시다. 해당 패키지들 사이의 의존성을 따라갔을 때, A가 B에 의존하고 B가 C에 의존하고 C가 A에 의존한다고 할게요. 그렇다면, 해당 패키지들은 이런 모양의 의존성을 가지게 됩니다.
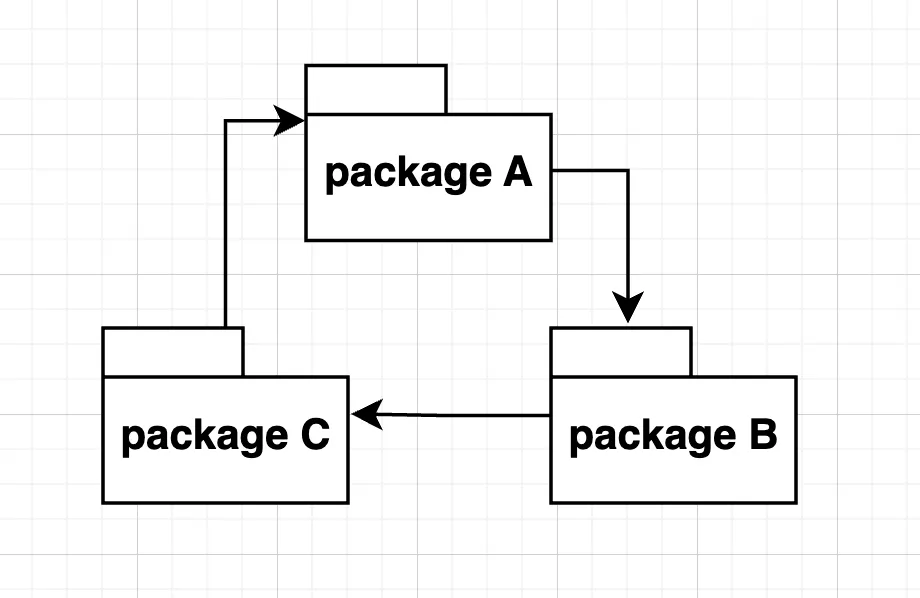
이런 의존성이 만들어 진다면, 피해야 합니다. 이건 3개의 패키지가 하나의 패키지라는 뜻입니다. 즉, 하나가 바뀌면 3개의 패키지가 함께 바뀌게 된다는 뜻이죠.
설계에서 가장 중요한 것은 “내가 코드 배치를 하는데 얘네가 어떻게 바뀔거야”에 포커스를 맞추는 것입니다.
위에서 설명한 4가지를 기본적인 가이드로 잡고 예제를 함께 보도록 합시다.
배달앱 예제
배달앱 내부에 있는 주문 플로우를 Domain Model로 나타내보겠습니다. 평범한 주문 플로우입니다. ⓵가게를 선택하고 ⓶메뉴를 선택한 다음 ⓷장바구니에 담고 ⓸주문을 완료하는 과정입니다.
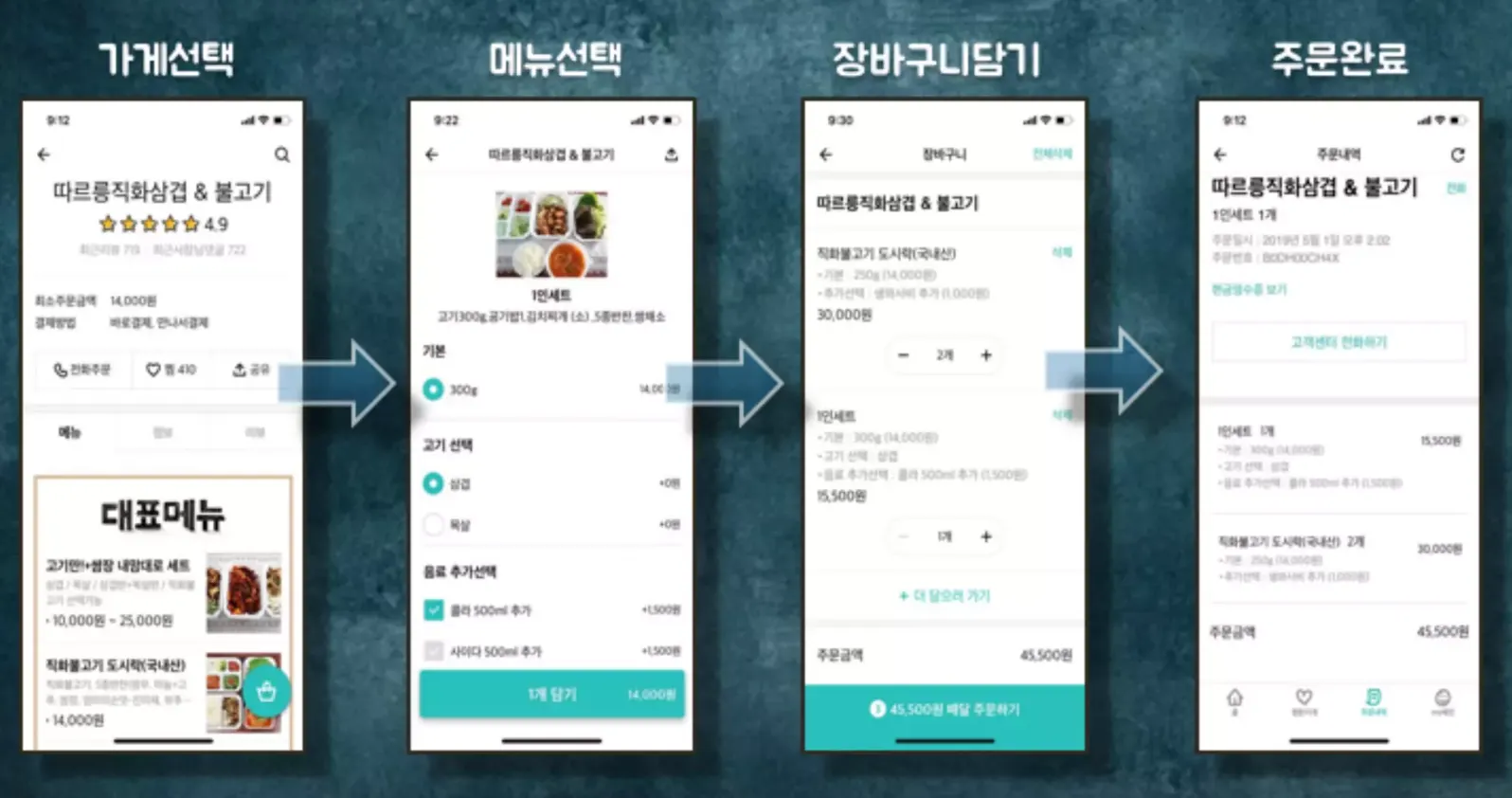
가게를 중심으로 해서 메뉴와 주문 객체 간의 관계가 엮이게 됩니다.
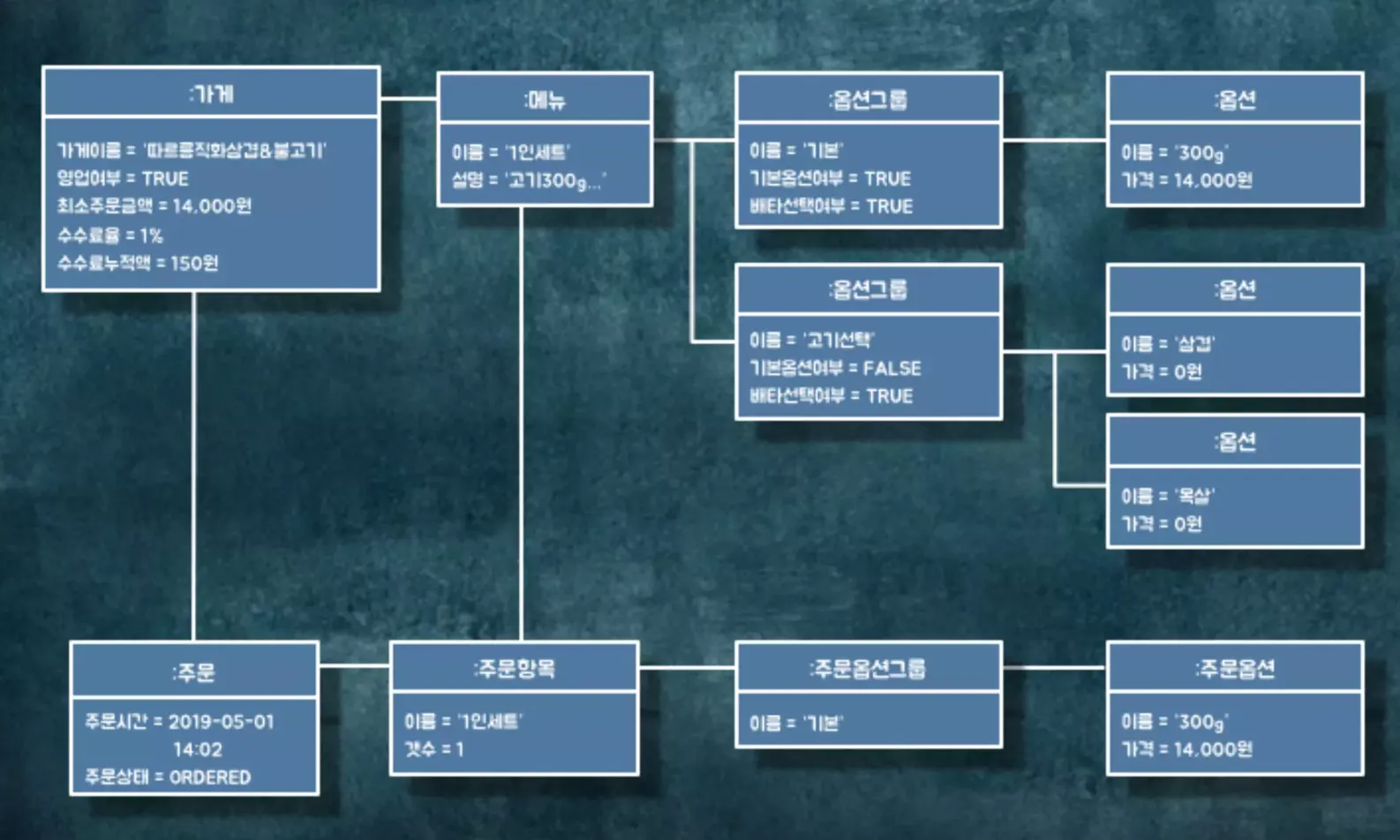
하지만, 메뉴를 선택해서 주문을 진행하는 플로우에는 문제가 있습니다.
메뉴를 선택하고 이를 장바구니에 담을 때 발생합니다. 앱에서는 장바구니에 메뉴를 담을 시에 핸드폰 로컬에 해당 정보를 저장하게 됩니다. 서버에는 해당 정보가 담기지 않습니다. 가게 사장님이 중간에 메뉴 이름과 함께 가격을 바꾸게 된다면 핸드폰 내부에 저장된 메뉴와 실제 메뉴의 불일치가 발생하게 됩니다.
즉, 주문 시 메뉴 불일치가 발생합니다.
우리는 주문이 발생할 때마다 실제로 주문으로 전송되는 데이터와 사장님이 등록한 데이터가 일치하는지 검증해야 합니다. 그렇다면, 어떤 항목들을 검증해야 하는지 살펴봅시다.
1.
메뉴의 이름과 주문항목의 이름 비교
2.
옵션그룹의 이름과 주문옵션그룹의 이름 비교
•
8000원짜리 짜장면을 시켰는데, 사장님이 8000원짜리 짬뽕으로 메뉴를 변경했을 경우, 가격은 같은데 실제로 배달되는 음식이 달라질 수 있습니다. 따라서, 이름이 바뀌는 것까지 일일이 검증해줘야 합니다.
3.
옵션의 이름과 주문옵션의 이름 비교
4.
옵션의 가격과 주문옵션의 가격 비교
5.
가게가 영업중인지 확인
•
장바구니에 넣어뒀다가 한참 뒤에 주문하는 경우, 가게가 영업 종료 상태일수도 있기 때문에 검증해줘야 합니다.
6.
주문금액이 최소주문금액 이상인지 확인
해당 6개의 품목을 체크한다고 가정합시다. 그리고 해당 품목들을 Validataion하는 로직의 협력을 설계해보겠습니다. 협력을 설계할 때에는 이 개념들 사이에서 어떤 플로우를 통해서 주문이 일어나는지에 대한 동적 플로우를 봅니다.
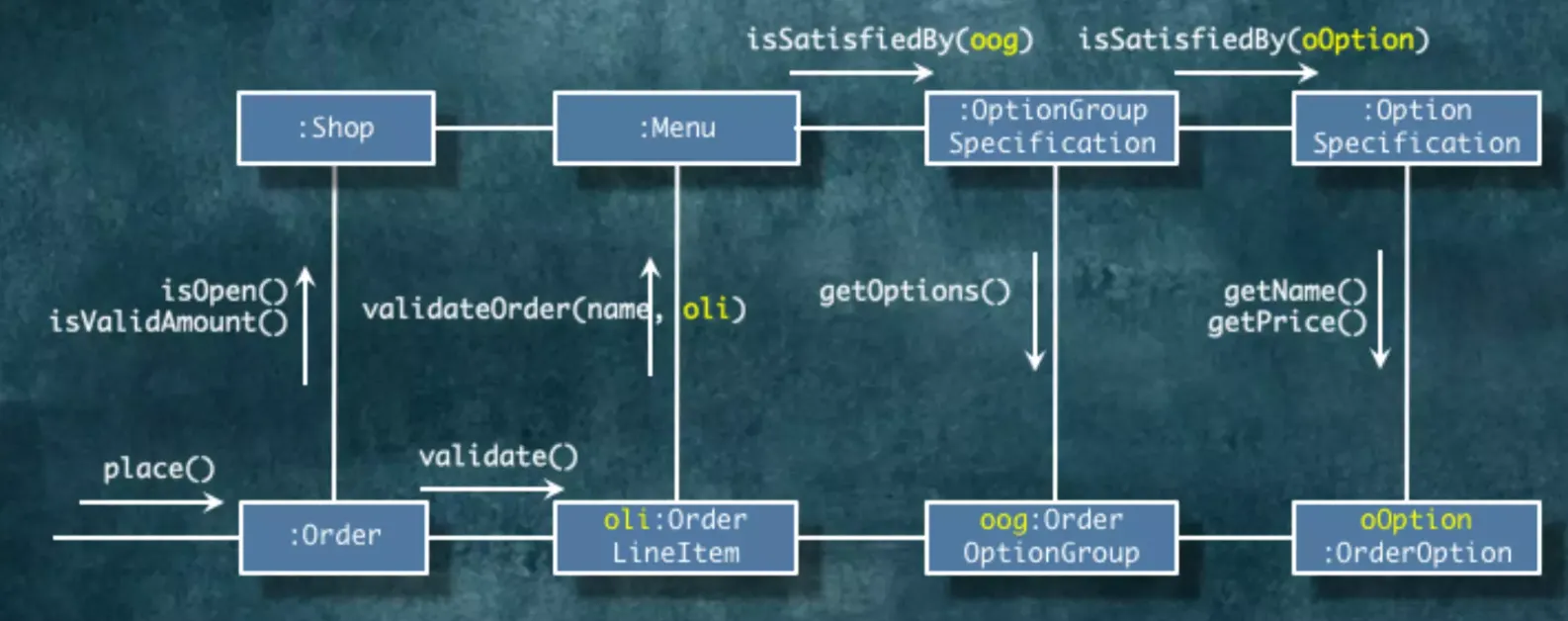
먼저, ⓵주문하기()가 발생합니다. 즉, 주문하기라는 메시지가 전송됩니다.
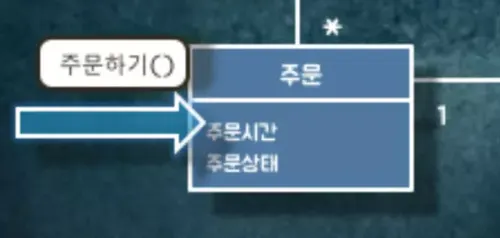
이제 주문이 들어왔으니 해당 주문을 가게 사장님에게 통지해도 되는지 확인해야 합니다.
우리는 현재 가게가 영업중인지 확인하고 주문금액이 최소 주문금액 이상인지 확인해야 합니다. 확인을 위해서 가게에 ⓶영업여부확인하기(), ⓶최소주문금액이상확인하기() 메시지를 보냅니다.
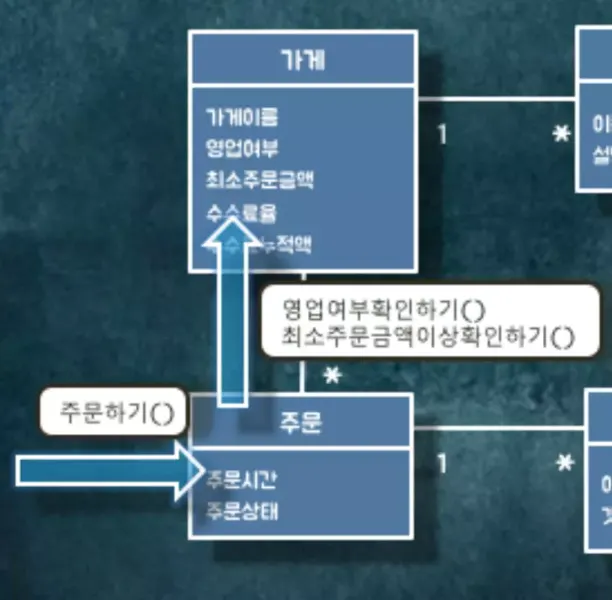
가게가 영업중이고 최소 주문 금액 이상이라면 메뉴의 이름과 주문항목의 이름을 비교해줍시다.
주문항목에 ⓷검증하기() 메시지를 보냅니다. 주문항목은 해당 메시지를 받고 메뉴에 주문항목과 메뉴의 이름이 동일한지 비교할 수 있는 ⓸검증하기(주문항목) 메시지를 보냅니다.
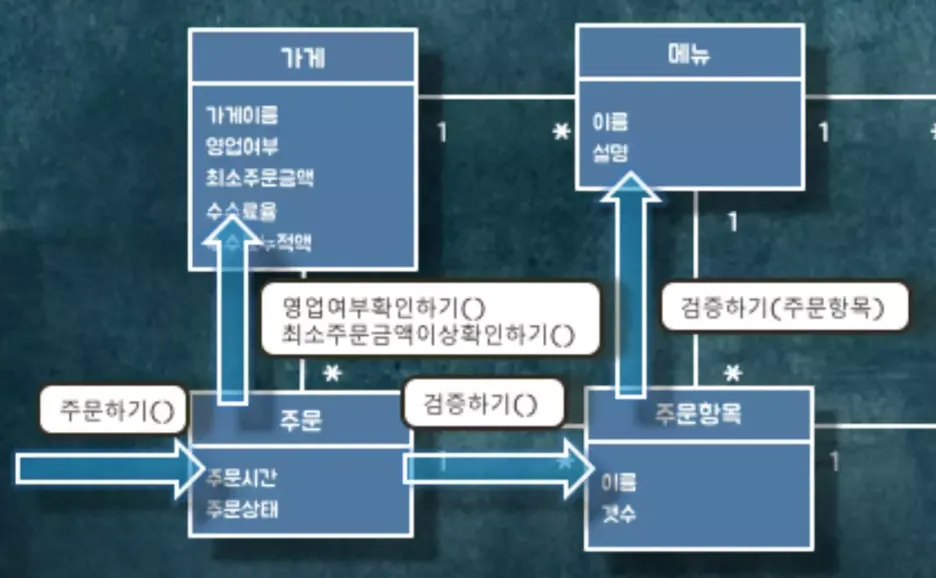
메뉴에서는 옵션그룹의 이름과 주문옵션그룹의 이름이 동일한지 비교하기 위해서 옵션그룹으로 이름이 동일한지 확인하는 ⓹만족여부확인하기(주문옵션그룹) 메세지를 보냅니다. 해당 메시지를 받은 옵션그룹은 주문옵션그룹으로 ⓺이름가져오기() 메시지를 보냅니다.
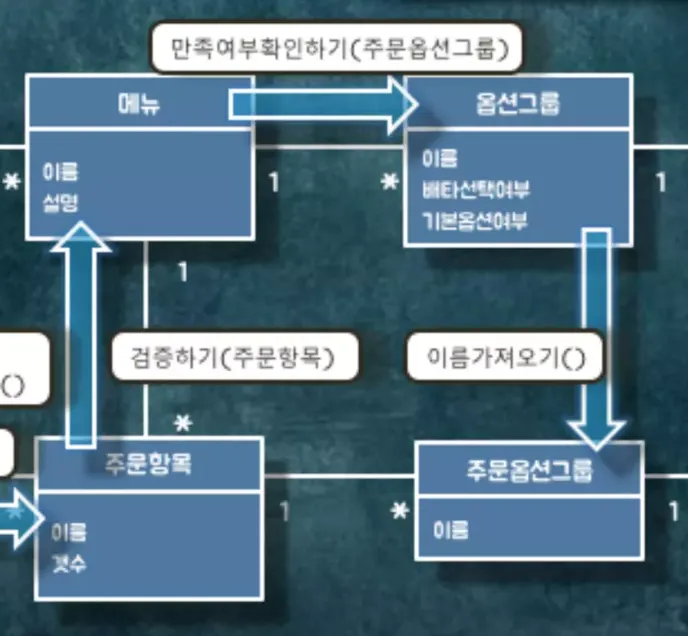
마지막으로 옵션의 이름과 가격이 주문 옵션의 이름과 가격과 같은지 비교합니다. 옵션그룹에서 옵션으로 주문 옵션을 만족하는지 ⓻만족여부확인하기(주문옵션) 메시지를 보냅니다. 해당 메시지를 받은 옵션은 주문옵션과의 비교를 위해서 ⓼이름/가격가져오기() 메시지를 주문옵션으로 보냅니다.
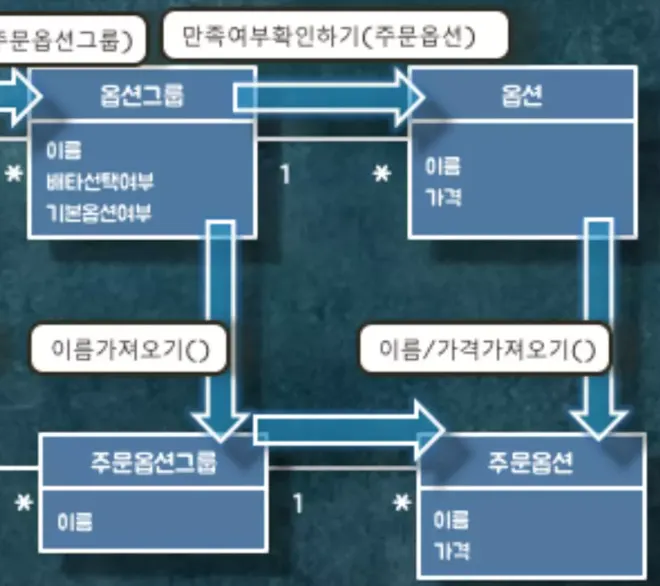
해당 로직을 다 통과하면 주문이 완료되었다고 가정합시다. 위의 플로우로 주문 검증을 하는 플로우가 진행된다고 생각할게요. 이제 이 플로우대로 의존성에 대해서 살펴볼겁니다.
위에서 객체 사이의 협력과 의사결정을 완료했습니다. 이제 의존성 관점에서 설계를 살펴볼 차례입니다.
왜 개발이 어려운지 아시나요?
주문이라는 플로우는 동적인 구조를 가집니다. 동적인 구조는 시간을 가지고 있습니다. 시간을 가지고 있기 때문에 굉장히 변화 무쌍합니다. 개발자는 변화무쌍한 가능성을 다 정적인 코드로 담아내야 합니다.
모든 가능성들을 메소드, 로직같은 움직이지 않는걸로 만들어줘야 합니다. 그러기 위해선, 우리는 정적인 무언가를 찾아내야 합니다. 그 중에 관계가 있습니다.
관계는 의존성입니다. 어떤 객체가 어떤식으로 의존할거라는 걸 코드상에 정적인 부분으로 그려내야 합니다.
관계는 런타임에 그 클래스 인스턴스가 다른 클래스 인스턴스와 어떤 식으로 협력이 이루어지는지에 대한 암시를 합니다. 인스턴스 변수를 넣거나, 어떤 메서드에 파라미터를 넣으면 이 타입의 객체가 다른 타입의 객체와 런타임에 협력할 거라는걸 우리는 알 수 있습니다.
우리는 협력을 정적인 코드로 표현해야 합니다. 그 중에서도 관계(의존성)에 포커스를 맞춰보겠습니다.
객체에서 관계는 방향성이 필요합니다. 의존성이라는 것은 “어떤 애가 어떤 애한테 의존함”을 나타내는 것이기에 Source와 Target이 필요합니다. 그리고 의존성이 어떤 방향으로 흐를건지 결정해주어야 합니다.
객체는 실제로 방향성이 잡히면 어떤 방식으로든 구현해줘야 합니다. 즉, 방향성 결정이 굉장히 중요합니다.
그렇기 때문에, 관계를 그냥 막 결정하면 안됩니다. 런타임에 객체들이 어떤 방향으로 협력하는지를 바탕으로 해서 관계를 설정해주어야 합니다. 물론, 다른 방식으로 관계를 잡아야 하는 경우도 존재합니다. 데이터적으로 이런 관계가 필요해하는 부분들이 존재하기 때문입니다. 하지만, 기본적으로 객체와 객체 사이가 어떤 식으로 협력하는지, 어떤 객체가 어떤 객체에게 메시지를 보내야 하는지를 바탕으로 관계의 방향을 잡아주는 것이 좋습니다.
그게 결국은 의존성의 방향이기 때문입니다.
관계의 방향은 협력의 방향이고, 의존성의 방향입니다. 협력의 방향에 따라서 어떤식으로든 관계가 형성되어야 한다고 결정하면 됩니다. 런타임 협력 관계를 가지고 의존성의 방향을 잡으면 이렇게 됩니다.
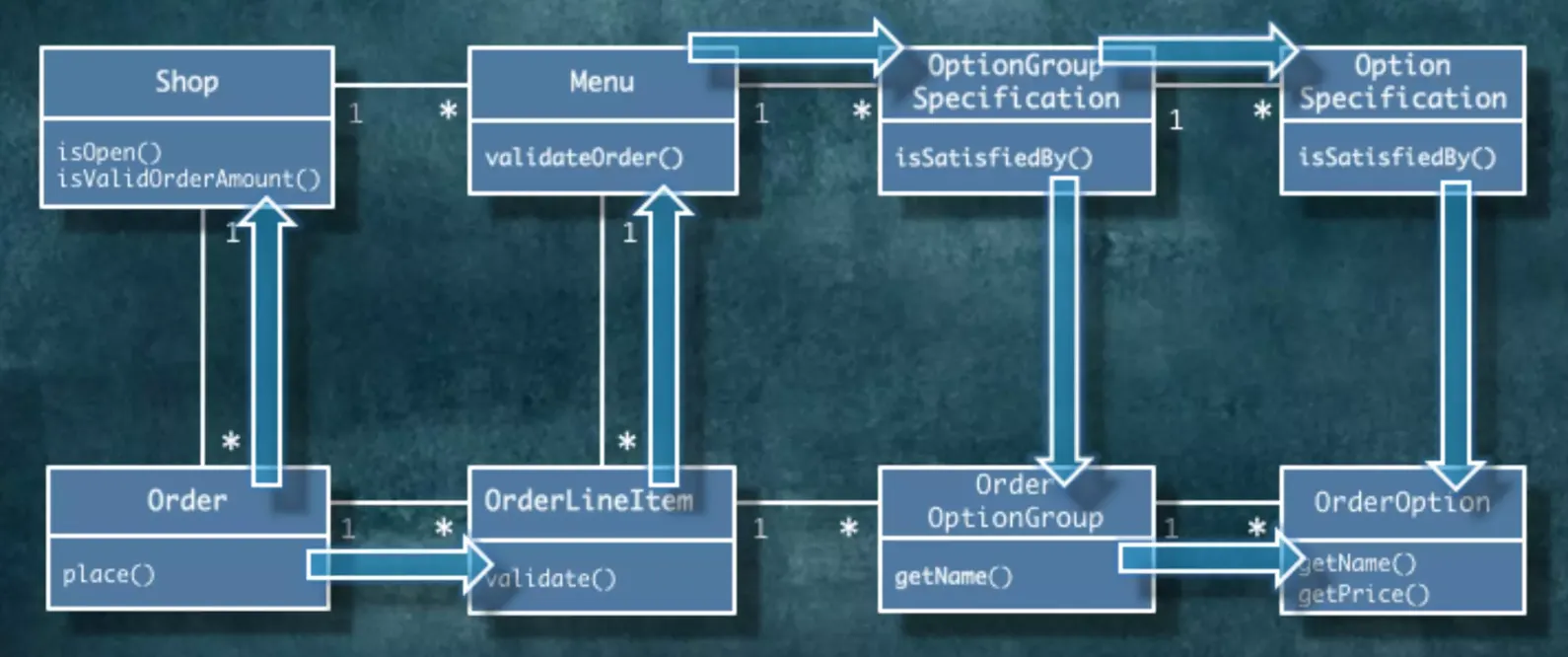
이전에 클래스 사이의 의존성에서 관계에 대해서 살펴봤습니다. 상속과 실체화는 관계가 너무 명확합니다. JAVA로 작성된 코드에 extends가 있으면 상속이고, implement가 있으면 실체화였습니다.
그렇다면, 연관과 의존관계는 어떻게 결정할 수 있나요?
1.
연관관계
연관관계는 협력을 위해 필요한 영구적인 탐색 구조입니다.
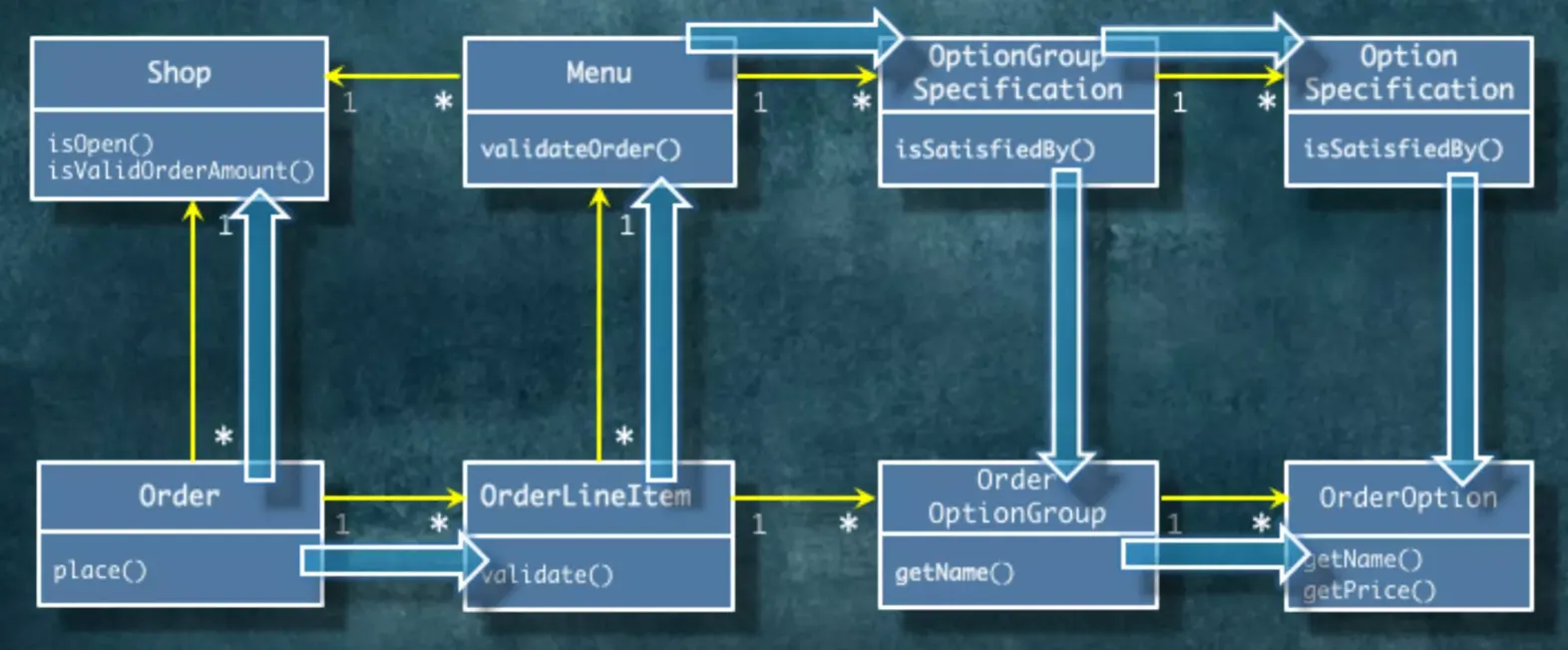
실제로 개발을 하다보면 데이터 구조의 영향을 받습니다. 데이터의 흐름을 따라가게 되는겁니다.
데이터의 영향을 받긴하지만 “어떻게 관계를 잡을거냐”라는건 런타임의 개체들이 “어떻게 협력할거냐”를 기반으로 정해져야 합니다. 그 경로에서 계속 협력을 해야하고 “그 관계를 차라리 인스턴스 변수로 잡아 놓는 것이 낫겠다”라는 생각이 들면 연관 관계입니다.
연관관계는 어떤 객체에서 어떤 객체로 빈번하게 가야하기 때문에 이 경로를 영구적으로 잡아두는겁니다.
2.
의존관계
협력을 위해 일시적으로 필요한 의존성입니다.
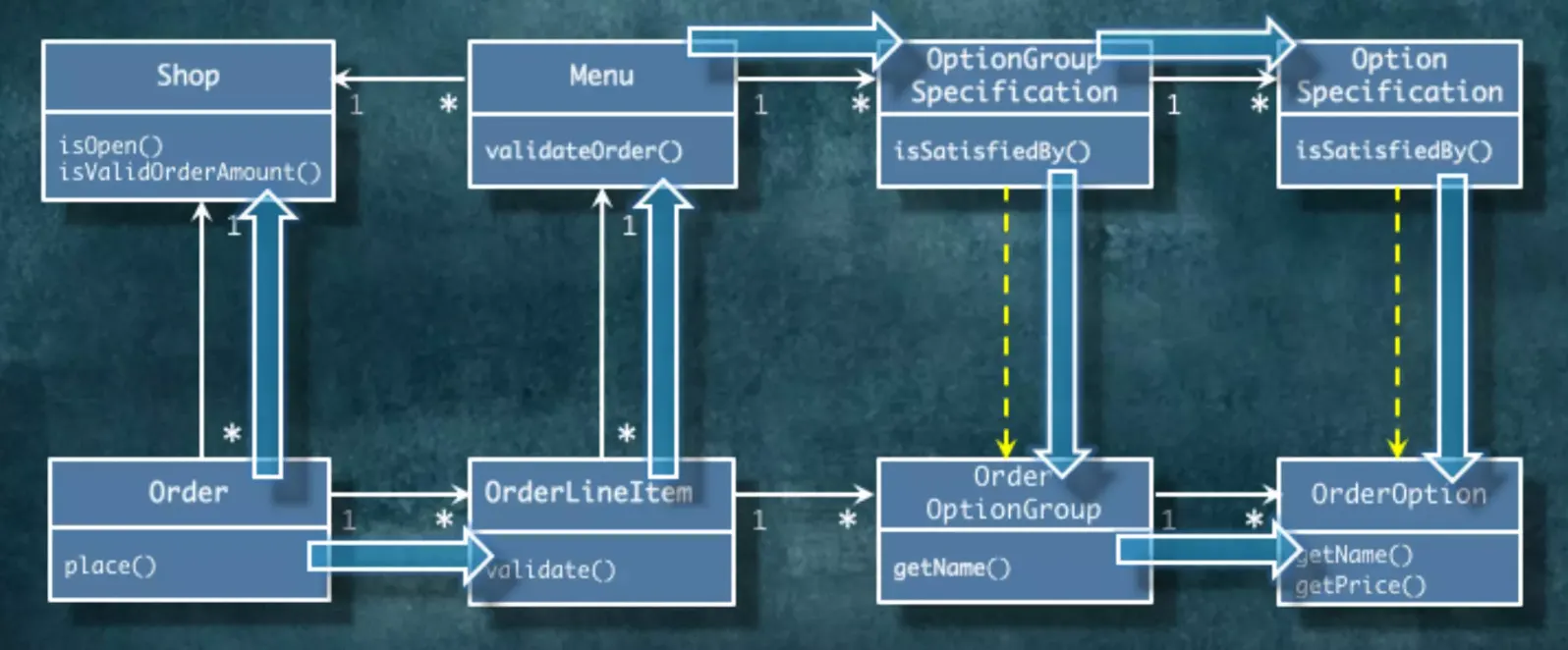
일시적이기 때문에 그 개체로 가는 경로가 항상 필요한게 아닙니다. 일시적으로 파라미터로 받고 끝나는 관계입니다.
코드 상에서 매핑이 되면 어떤 관계로 가야되는지 결정이 됩니다. 하지만, 이런 관계를 결정하는 것보다는 방향성이 더 중요하다는걸 명심해야 합니다.
내가 뭔가를 참조한다고 할 때에는 이유가 필요합니다. 연관관계, 의존관계로 넣는 이유가 필요하다는 소리입니다. 하지만, 이건 런타임에 객체가 어떻게 협력하는지에 따라서 달라집니다.
연관관계의 정의는 탐색가능성(Navigability)입니다.
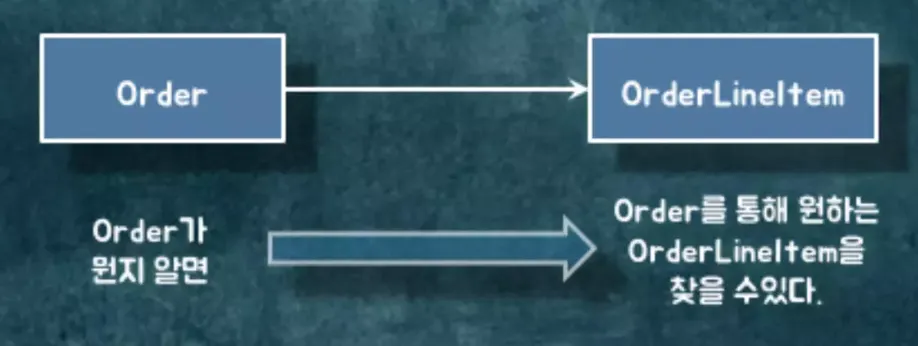
Order와 OrderLineItem를 연관 관계로 설정했다는건 Order를 통해서 내가 원하는 OrderLineItem으로 어떤 방식으로든 찾아갈 수 있다는걸 의미합니다. 어떤 객체를 알면 해당 객체를 통해서 내가 원하는 다른 객체에 찾아갈 수 있다는거죠.
연관관계로 잡기 위해서는 두 객체 간의 통로가 굉장히 영구적으로 유지되어야 한다는 판단 근거가 필요합니다.
일반적으로 연관 관계 구현 방식은 “객체 참조”를 사용하는 겁니다.
class Order {
private var orderLineItems: [OrderLineItem] = []
private func validate() {
orderLineItems.forEach { orderLineItem in
orderLineItem.validate()
}
}
}
Swift
복사
배달앱 예제 구현
이제 위의 다이어그램을 코드로 매핑해보겠습니다.
Order는 place() 메서드가 호출되면서 검증을 시작합니다.
public class Order {
public func place() {
validate()
ordered()
}
private func validate() { }
private func ordered() { }
}
Swift
복사
어떤 객체가 어떤 메시지를 받는다는 것은 해당 객체에 해당 메시지가 public 메서드로 구현된다는 것을 의미합니다. 메서드를 만드는 이유는 메시지를 받기 때문입니다. 메서드를 만들어서 메세지를 받는 것이 아닙니다. 메세지가 결정된 다음에 메서드를 만드는 순서로 진행해야 합니다.
우리는 Order 객체가 place()라는 메시지를 받는 걸로 결정했습니다. 따라서, place 메서드를 만들었습니다. 해당 메서드에서는 두 가지 메서드를 호출합니다.
⓵주문이 올바른지 검증하는 메서드와 ⓶주문의 상태를 바꾸는 메서드입니다.
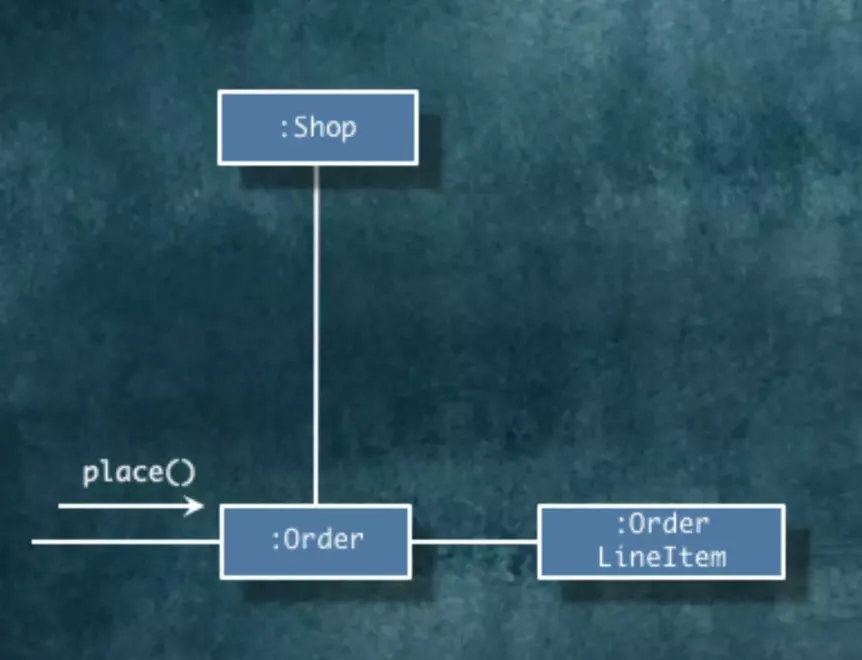
Order라는 객체는 Shop과 OrderLineItem으로 이동할 수 있어야 합니다. 즉, Order가 해당 객체쪽으로 메시지를 보낼 수 있어야 합니다.
왜 메시지를 보낼 수 있어야 하나요?
가게가 영업중인지 검증하고 주문 금액이 최소 주문 금액보다 많은지 검증하기 위해서는 해당 객체로 메세지를 보내야 합니다. 객체 사이의 협력, 경로가 필요하게 됩니다.
주문은 항상 어떤 가게의 주문이고, 항상 주문 항목을 가집니다. 따라서, Shop, OrderLineItem과 강력한 관계를 맺고 있다고 볼 수 있습니다. 해당 경로가 굉장히 영구적인 관계라고 판단을 해서 연관관계로 설정하고 물리적인 통로가 필요하기 때문에 객체 참조를 사용합니다.
public class Order {
private let shop = Shop()
private var orderLineItems: [OrderLineItem] = []
public func place() {
validate()
ordered()
}
private func validate() { }
private func ordered() { }
}
Swift
복사
위의 코드를 다이어그램으로 나타내면 이런 모습이겠네요.
이번엔 Order 객체 안에 있는 validate() 메서드를 구현해보겠습니다.
해당 메서드에서는 가게 영업중, 최소 주문 금액을 확인합니다. 이걸 확인하기 위해서는 Shop으로 메세지를 전송해야 합니다.
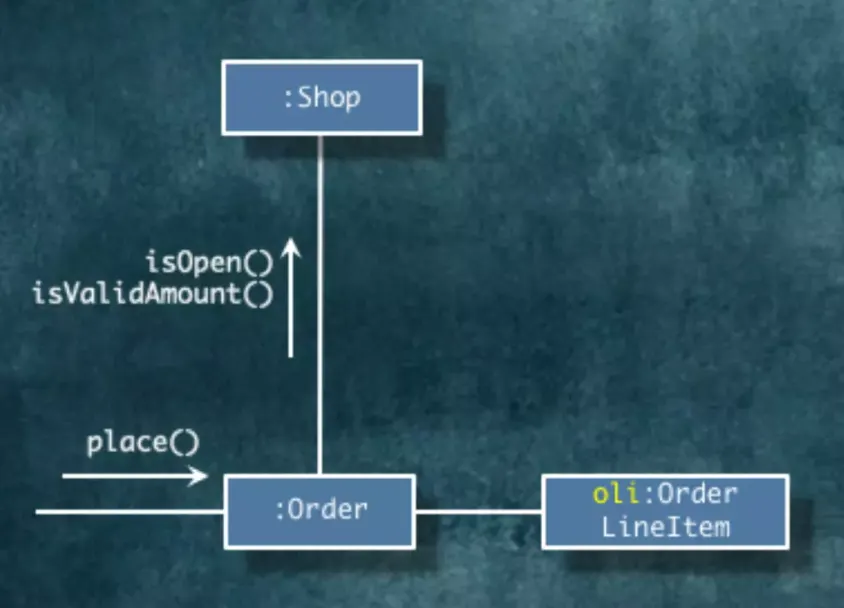
우리는 Shop으로 메시지를 보내서 결과값을 가져온 다음에 주문이 통과 가능한지 검증합니다.
public class Order {
public func place() {
do {
try validate()
ordered()
} catch(let error) {
print(error)
}
}
private func validate() throws {
if orderLineItems.isEmpty {
throw NSError(domain: "주문 항목이 비어 있습니다.", code: 404)
}
if !shop.isOpen {
throw NSError(domain: "가게가 영업중이 아닙니다.", code: 404)
}
if !shop.isValidOrderAmount(calculateTotalPrice()) {
let minOrderAmount = shop.minOrderAmount
throw NSError(domain: "최소 주문 금액 \(minOrderAmount) 이상을 주문해주세요.", code: 404)
}
}
}
public class Shop {
public var isOpen: Bool {
return self.open
}
public func isValidOrderAmount(_ price: Int) {
return amount.isGreaterThanOrEqual(to: minOrderAmount)
}
}
Swift
복사
그러고나서 각각의 주문 항목들이 매칭되는지 확인합니다. OrderLineItem에 Validate() 메시지를 전송합니다.
public class Order {
private func validate() throws {
// ...
if !shop.isValidOrderAmount(calculateTotalPrice()) {
let minOrderAmount = shop.minOrderAmount
throw NSError(domain: "최소 주문 금액 \(minOrderAmount) 이상을 주문해주세요.", code: 404)
}
orderLineItems.forEach { orderLineItem in
orderLineItem.validate()
}
}
}
public class OrderLineItem {
public func validate() {
menu.validateOrder(name, self.orderOptionGroups)
}
}
Swift
복사
지금까지 객체들이 협력하는 모습을 그린다면 이런 모습이겠군요.
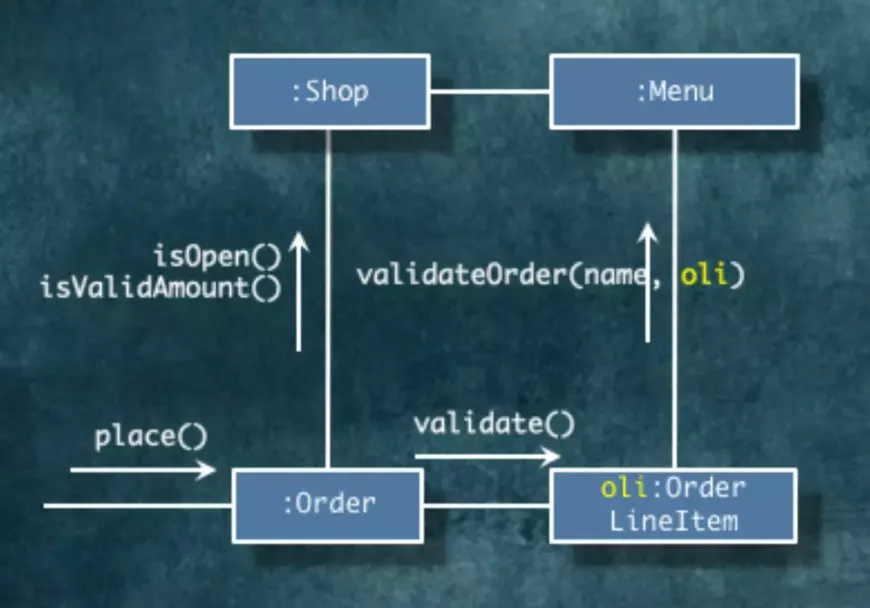
이제 Menu에서 메뉴 이름과 주문 항목을 비교해야 합니다. OptionGroupSpecs안에서는 OrderOptionGroup과의 비교가 진행됩니다.
public class Menu {
public func validateOrder(_ menuName: String, groups: [OrderOptionGroup]) throws {
if !self.name.equals(menuName) {
throw NSError(domain: "기본 상품이 변경됐습니다.", code: 404)
}
if !isSatisfiedBy(groups) {
throw NSError(domain: "메뉴가 변경됐습니다.", code: 404)
}
}
private func isSatisfiedBy(_ groups: [OrderOptionGroup]) -> Bool {
return groups.map { self.isSatisfiedBy($0) }.contains(true)
}
private func isSatisfiedBy(_ group: OrderOptionGroup) -> Bool {
return optionGroupSpecs.isSatisfiedBy(group)
}
}
Swift
복사
그리고 OptionSpecs안에서는 OrderOption의 이름, 가격과 동일한지 비교하는 로직이 실행될 겁니다. 객체들의 전체적인 협력을 보면 이런 모습이겠네요.
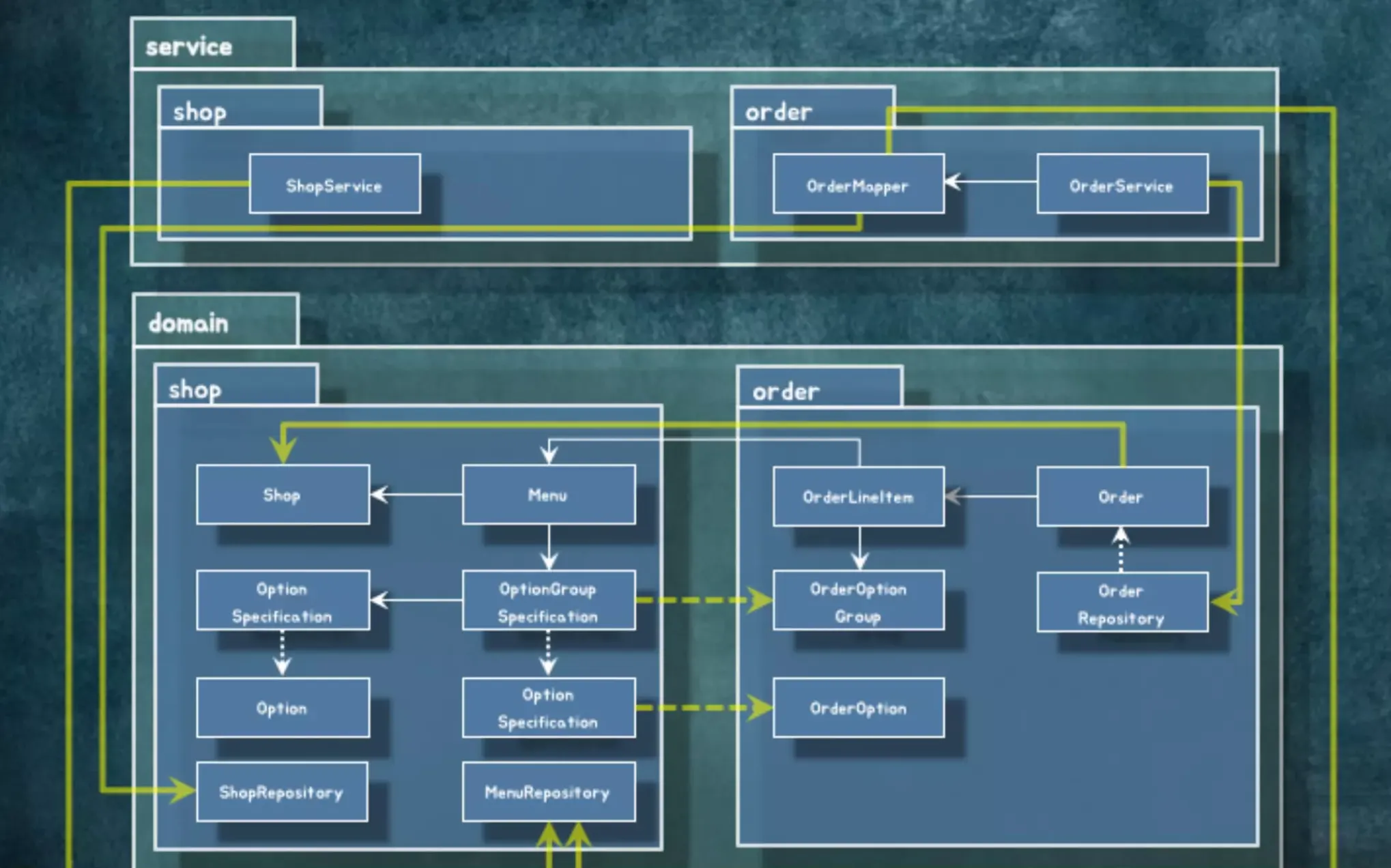
이 설계에서 개체 간의 관계는 레이어 아키텍처에서 Domain 구조에 들어간다고 보면 됩니다.
Domain를 구성하는 개체들 사이에 어떤 식으로 협력이 일어나야 하는지 관계를 잡은겁니다. 실제로 코드를 구현하려고 하면 도메인 영역을 벗어난 영역의 개체들까지도 구현해줘야 합니다. 여기서는 Service와 Infra 구조까지만 구현하겠습니다.
코드를 의존성 관점에서 뜯어보기(설계 개선)
설계를 제대로 했는가를 보려면 dependency를 그려보면 됩니다. dependency를 그리고 나서 뭔가 이상한게 있다면 그 코드는 이상한 부분들이 많습니다. 의존성을 보면서 개선을 하면 원하는 구조로 가는 경우가 많습니다.
의존성을 그리면 “내 코드에 의존성이 어떤 모양을 가지고 있지?”, “사이클은 도나?”, “넣으면 안되는걸 넣었나?” 라는 게 그림에서 보이는 경우가 굉장히 많습니다. 그 중에서도 2가지만 말해 보겠습니다.
1.
객체 참조가 가져오는 문제점
2.
패키지 의존성에서 사이클이 발생할 때의 문제점
이 두가지를 어떻게 해결하면 좋을지에 대한 관점에서 설명을 진행하겠습니다.
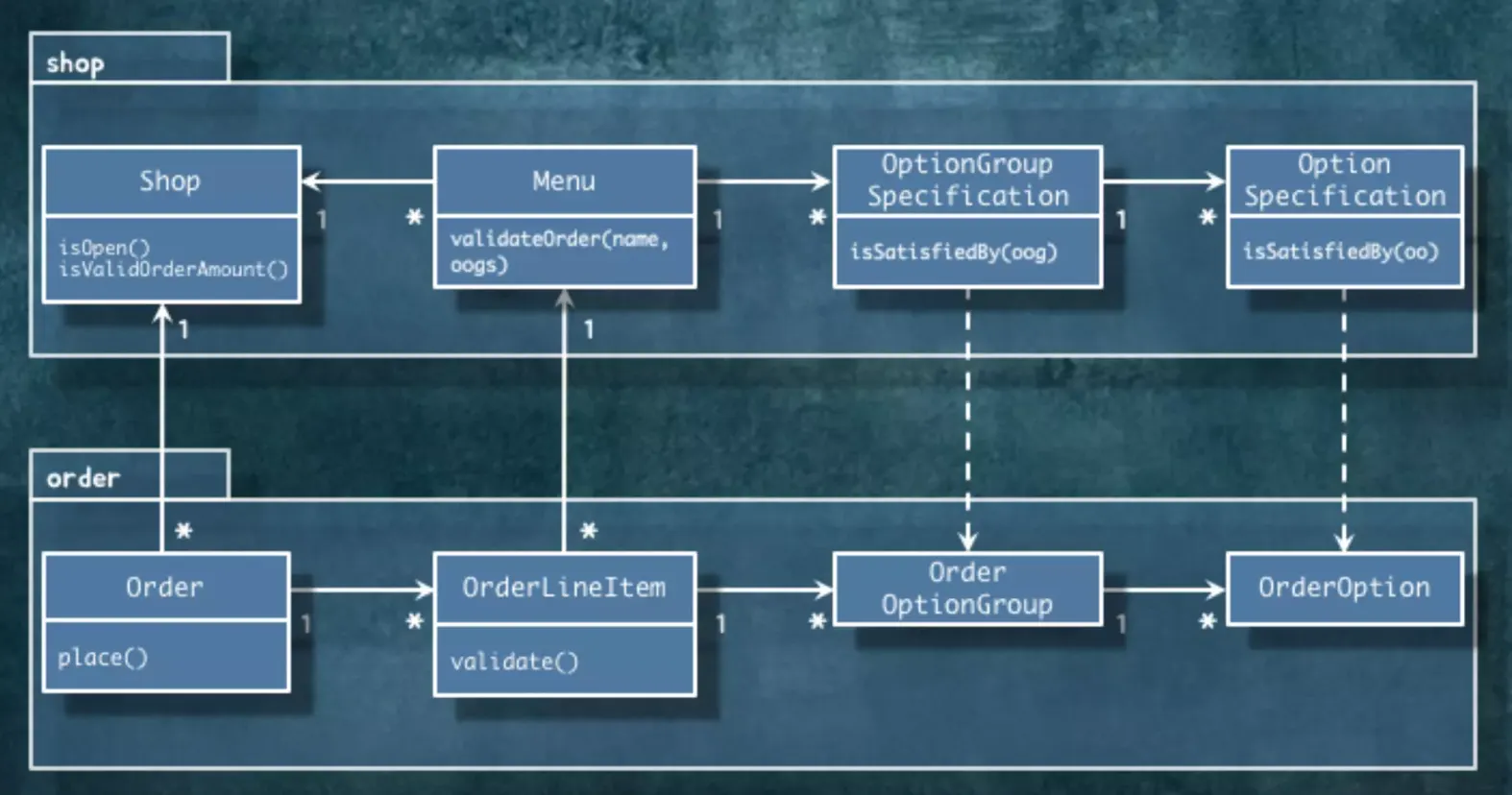
지금까지의 코드의 의존성을 보면 이런 모습입니다.
의존성을 살펴봤더니 사이클이 돌고 있습니다. Domain layer 안에서 Shop과 Order 사이에서 사이클이 발생합니다.
어디서 사이클이 발생하는걸까요?
1.
Order 객체
Order는 Shop으로 의존 관계를 가지고 있습니다.
public class Order {
private let shop = Shop()
private var orderLineItems: [OrderLineItem] = []
public func place() {
validate()
ordered()
}
}
Swift
복사
메시지를 보내야 하기 때문에 Shop에게 의존할 수 밖에 없습니다. 관계 중에서도 강한 연관 관계로 묶여있습니다.
2.
OptionGroup, OrderOptionGroup
OptionGroup과 OrderOptionGroup은 서로 데이터를 가지고 와서 이름과 가격을 비교해야 합니다. 따라서, 양방향 연관관계가 생길 수 밖에 없습니다.
Shop를 고치면 Order도 고쳐야 합니다. OrderOption를 고치면 OptionGroup도 고쳐야 합니다. 양쪽 Package를 같이 고쳐야 하는겁니다. 이는 Package가 잘못 분리됐기 때문에 의존성의 방향이 잘못되었다고 볼 수 있습니다.
이런 양방향 연관관계를 해결하는 방식은 다 다릅니다.
1.
중간 객체를 이용해서 의존성 사이클을 끊습니다.
OptionGroupSpecification과 OrderOptionGroup 사이에 중간 객체를 만듭니다.
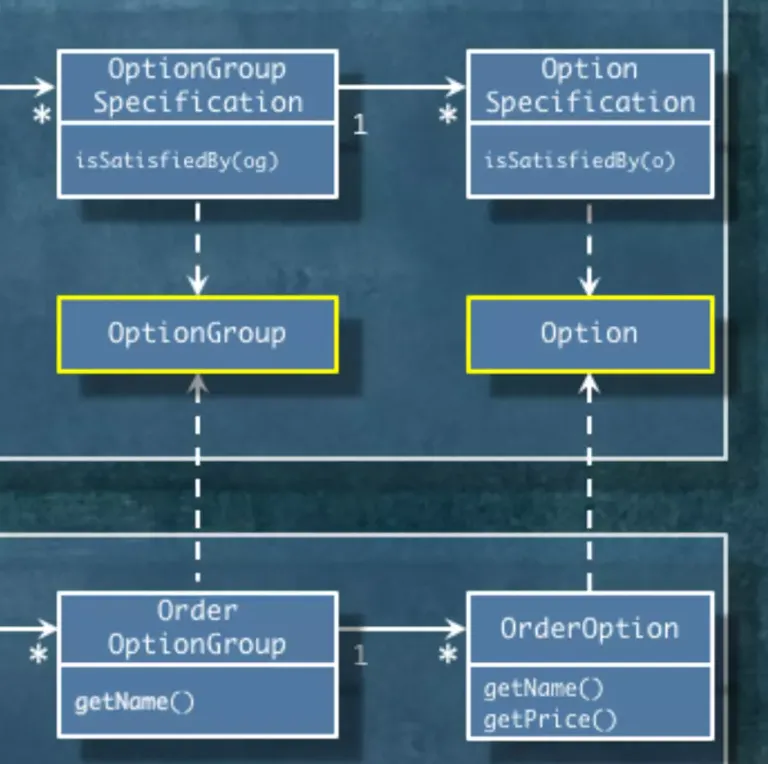
OrderOptionGroup에서는 OptionGroup을 이용해서 OrderOptionGroup을 변환합니다. OptionGroupSpecification은 OptionGroup를 파라미터로 받습니다.
이렇게 만들면 의존성이 단방향으로 흐르게 됩니다. Order에서 Shop으로만 흐르기 때문에 의존성 사이클이 끊기게 됩니다.
뒤에서 의존성 역전 원칙에 대해서 얘기가 나옵니다. 이 원칙은 클래스가 구체적인 것에 의존하지 말고 추상적인 것에 의존하라는 원칙입니다. 이 원칙을 사용해서 패키지의 사이클을 끊을 수 있습니다.
하지만, 해당 원칙에서 말하는 추상화가 추상 클래스나 인터페이스여야 한다는 선입견이 존재합니다.
실제적으로 추상화는 잘 변하지 않는걸 얘기합니다. 어떤 것이 어떤 거에 비해서 잘 변하지 않는다면 추상적인겁니다. OptionGroup은 위아래에 있는 OptionGroupSpecification, OrderOptionGroup과는 다르게 필요한 것만 들고 있습니다. 즉, 두 클래스보다 추상적입니다.
중간 객체를 사용하는 방식은 재사용성이 증가한다는 장점이 있습니다.
동일한 Validation 로직을 주문에서 사용해도, 장바구니에서 사용해도 적용 가능합니다. OptionGroup으로 변환하기만하면 OptionGroupSpecification에서 사용할 수 있기 때문이죠.
2.
연관관계 다시 살펴보기
아까 우리가 연관관계는 탐색가능성이라고 했습니다. 즉, Order를 알면 OrderLineItem를 얻을 수 있다는 거죠. Order가 OrderLineItem과 연관관계이기 때문에 탐색 경로를 제공해줍니다.
하지만, 객체 참조로 구현한 연관 관계는 문제점이 있습니다.
두 객체 사이의 결합도가 높아진다는 겁니다.
결합도가 높아지면 큰 문제가 발생하나요?
⓵ 성능 문제 - 어디까지 조회할 것인가?
개체들이 다 연결되어 있기 때문에 객체들을 어디든 탐색할 수 있게 됩니다.
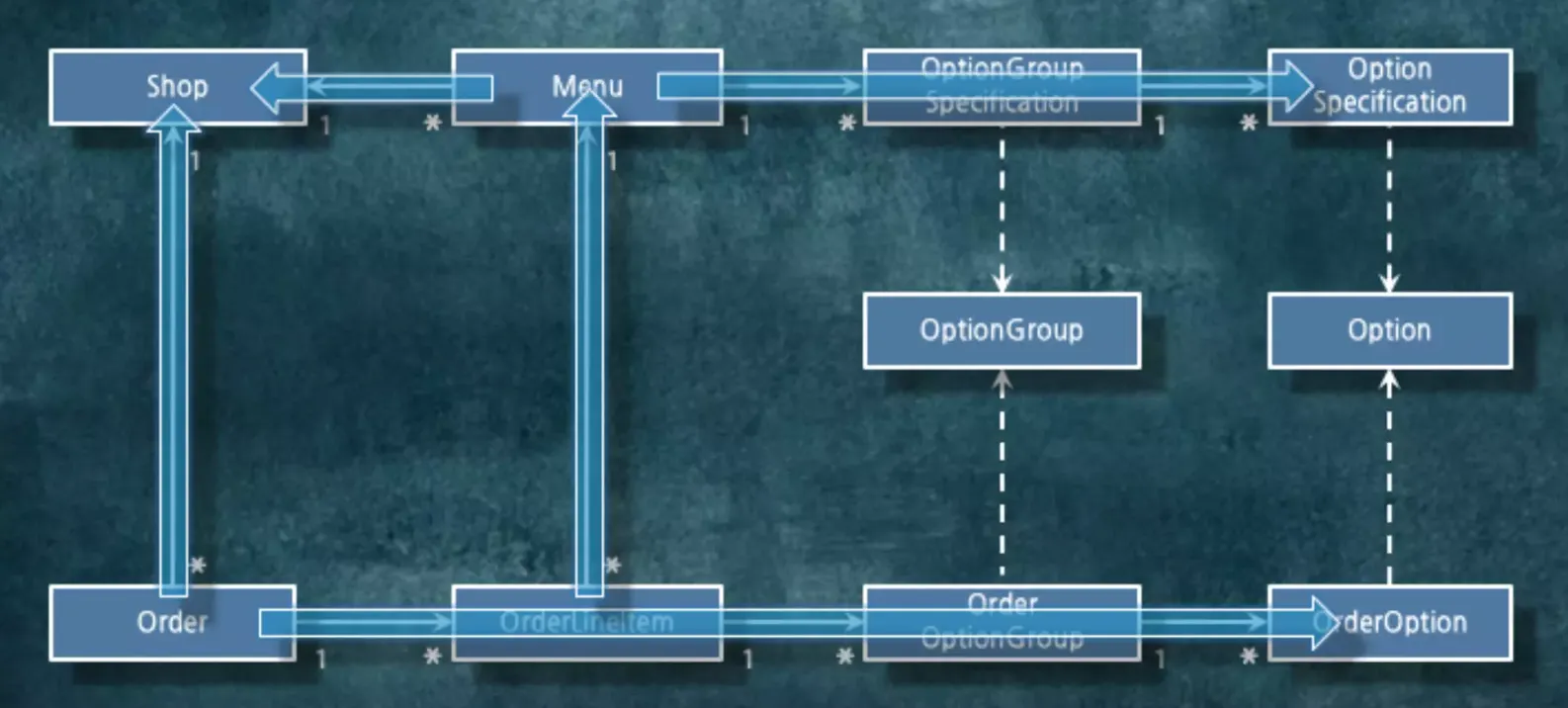
Order에서 Shop, OrderOption까지 갈 수 있게 됩니다. 이게 메모리 상에 있을 때는 큰 이슈가 아닐 수 있는데, DB로 직접 매핑하거나 하게 되면 연관 관계가 있을 시에 헬 게이트가 열릴 수 있습니다. 어디든지 해당 객체를 통해서 갈 수 있기 때문에 이슈가 발생할 수 밖에 없습니다.
또한, 객체 그룹의 조회 경계가 모호해집니다. 어디까지 읽어야 하고 어디까지는 읽지 말아야 하는지에 대한 가이드가 없습니다.
⓶ 수정시 도메인 규칙을 함께 적용할 경계는?
Order 객체가 수정되면 Shop 객체도 수정해야 하고 OrderOption까지 수정이 되어야 합니다.
그렇다면, 우리는 Order 객체에 들어가서 연관관계를 다 뒤지고 다니면서 모든 관계들을 세팅해주어야 합니다. 세팅을 하면 끝이라고 생각하겠지만, 이 모든게 long 트랜잭션으로 물려버립니다.
트랜잭션 경계는 어디까지인가?
객체 참조를 통해서 수정하는 모든 것들이 트랙잭션 안에서 하나의 트랜잭션으로 가버립니다.
트랜잭션의 경계가 모호해진겁니다. 그렇기 때문에, 성능 이슈가 발생할 수 밖에 없고 객체 참조는 그런 이슈를 생각하지 못하게 만들어 버립니다. 이슈를 놓치게끔 하는거죠.
그러면서, 트랜잭션이 점점 길어지게 됩니다.
비즈니스 로직이 추가될수록 상태를 바꿔줘야 하는 객체들이 늘어갑니다. 요구사항이 바뀌고 요구사항이 추가될수록 트랜잭션이 길어지게 됩니다.
결제 완료 로직에서는 “결제 해주세요”라는 요청이 들어오면 Service 객체가 요청을 받아서 매핑합니다.
class OrderService {
private let orderRepository = OrderRepository()
private let deliveryRepository = DeliveryRepository()
func payOrder(_ orderId: String) {
let order = orderRepository.findById(orderId)
order.payed()
let delivery = Delivery.started(order)
deliveryRepository.save(delivery)
}
}
Swift
복사
orderId를 매개변수로 받아서 Order 객체를 가져온 다음, payed() 메서드를 호출합니다. 그리고 배송 정보를 생성한 다음 배송 정보를 저장합니다.
payOrder 메서드 내부에서는 Order, Delivery 그리고 Order 객체에서 호출한 Shop 객체까지 해서 총 3개의 객체가 호출됩니다.
하나의 트랜잭션 안에서 업데이트가 진행되게 됩니다. 다른 로직들이 추가되다보면 3개의 객체가 변경되는 주기가 다 다르다는걸 알 수 있습니다.
예를 들어서, Shop은 가게 사장님이 영업중으로 바꾼다는 요청이 와서 갱신하는 주기가 존재합니다. Order은 사용자가 취소한다는 요청이 와서 상태가 바뀌는 주기가 존재합니다. Delivery도 상태가 바뀌는 주기가 따로 존재합니다.
long 트랜잭션으로 묶인 이 객체들에 새로운 요구사항이 추가될수록 트랜잭션이 몰리는 주기가 달라지게 됩니다.
어떤 문제가 발생하나요?
아무 생각없이 객체들을 쫓아가면서 수정하다보면 트랜잭션 경합 때문에 성능 저하, 응답성이 굉장히 떨어지는 경우가 빈번하게 발생했습니다.
객체 참조가 꼭 필요할까요? 아니면 언제 필요한건가요? 불필요한가요?
객체 참조의 문제점은 모든 것을 다 연결시킨다는 겁니다.
그렇기 때문에, 객체 참조를 쫓아가면 뭐든지 다 할 수 있을 거 같다는 욕망이 생기고 결국 모든 객체를 다 연결하게 됩니다. 어딜가든 다 접근 가능하고, 어디라도 내맘대로 수정할 수 있게 됩니다.
실제로 객체 참조는 모든 결합 중에서 가장 높은 의존성을 가집니다. 이 객체와 이 객체를 영구적으로 묶기 때문이죠. 영구적으로 묶었기 때문에 해당 객체는 항상 그 객체와 같이 있어야 하고 결국 굉장히 결합도 높은 의존성이 생기게 됩니다.
그렇기 때문에, 필요한 경우에는 객체 참조를 끊어야 합니다.
연관관계를 구현하는 방식 중에 하나가 객체 참조였습니다.
그렇다면, 결합도를 낮추면서 연관관계를 어떻게 구현할 수 있나요?
Repository를 사용하는 방법입니다.
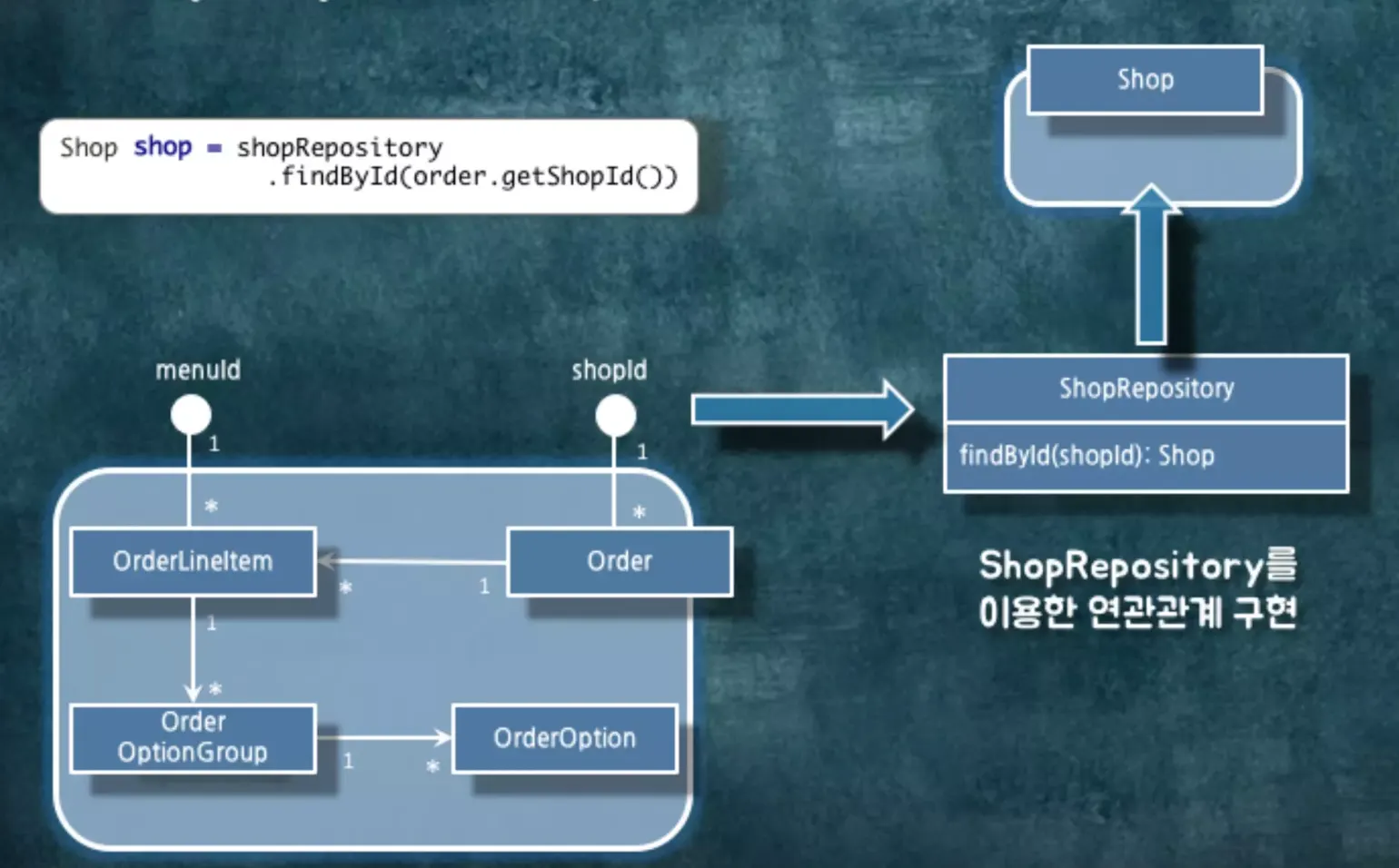
Order는 Order안에 shopId를 가지고 있습니다. 이걸로 Shop 객체를 알 수 있습니다. shopId를 Repository에 보내면 Shop를 얻을 수 있게 됩니다.
Repository에 들어갈 interface는 연관 관계를 구현할 수 있는 Operation들이 들어가야 합니다. 무조건 중구난방으로 객체를 찾아서는 안됩니다. 파라미터로 받은 타입을 가지고서 이 객체를 찾을 수 있어야 합니다.
“연관 관계를 어떤 관점에서 구현할거야”라는 Operation들이 들어가야 합니다.
그렇지 않으면, 연관관계가 덕지덕지 생기게 됩니다. 조회 로직, admin 로직이 점점 추가될수록 양방향이 늘어나게 되는거죠.
따라서, Repository에 들어가는 메서드는 다 연관관계를 구현할 수 있어야 합니다.
하지만, 어떤 객체들은 Repository를 사용하지 않고 객체 참조를 사용해도 되는 경우가 있습니다. 본질적으로 결합도가 굉장히 높은 객체들은 같이 묶어도 됩니다. 이걸 구분할 때 가장 중요한건 도메인 룰입니다.
도메인에서 “어떤 개념, 어떤 데이터들을 어떤 식으로 처리하는지”, “같이 처리되는지, 따로 처리되는지“와 같은 도메인적인 관점에서 그룹을 묶어줘야 합니다.
그럼, 우리는 트랜잭션 안에 어떤 걸 넣어야 할까요?
같이 변경되는 것들을 함께 넣어줍시다.
어떤 것들이 같이 변경되어야 할까요?
비즈니스와 관련된 것들이 같이 변경되어야 합니다. 즉, 도메인 관점으로 그룹을 묶어야 합니다.
어떤 객체들을 묶고 어떤 객체들을 분리할지에 대한 간단한 규칙이 존재합니다.
1.
함께 생성되고 함께 삭제되는 객체들을 함께 묶어라
함께 생성되고 삭제되는 객체들은 같이 움직이기에 결합도가 높습니다. 따라서, 객체들을 객체 참조로 묶어버리면 됩니다. 하지만, 그렇지 않은 경우는 끊어버리는게 좋습니다.
2.
도메인 제약사항을 공유하는 객체들을 함께 묶어라
예를 들어서, 장바구니와 장바구니 항목을 묶어야 하나 고민한다고 가정해보겠습니다.
생각해보면 장바구니와 장바구니 항목이 생성되는 시점은 다릅니다. 즉, 라이프 사이클이 완전히 다릅니다. 일반적인 이커머스에서는 장바구니와 장바구니 항목 사이에서 공유되는 제약이 별로 없습니다.
이 항목을 넣고, 저 항목을 넣을 때에 제약사항이 없다면 도메인 Constraint를 공유하지 않는다고 볼 수 있습니다. 그렇기 때문에 이런 상황에서는 장바구니와 장바구니 항목을 찢어야 합니다.
하지만, 배달앱에서는 장바구니에 동일한 업소의 메뉴만 넣을 수 있다는 제약이 존재합니다. 그러면, 장바구니와 장바구니 항목을 하나의 객체 그룹으로 만들어야 합니다.
객체를 어떻게 묶는지에 대해서는 룰이 존재하지 않습니다. 이 시스템과 저 시스템이 객체를 어떻게 묶는가는 다를 수 있습니다. 이는 비즈니스 룰에 따라서 결정되기 때문입니다.
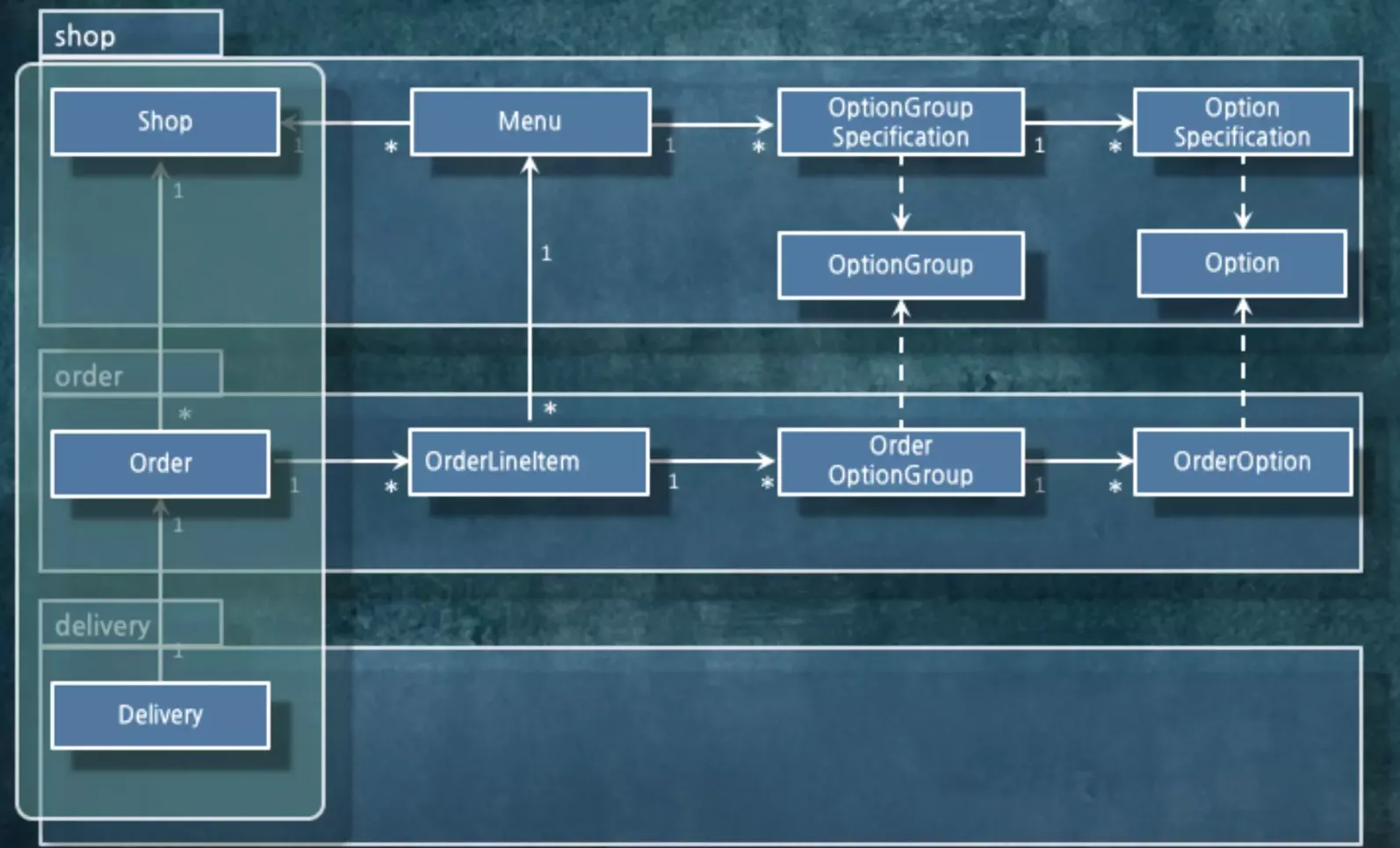
그럼, 아까 우리가 만들었던 객체들을 묶어 보겠습니다.
가게(Shop)가 생겼다고 해서 메뉴가 바로 생기는게 아닙니다. 따라서, 두 객체는 독립적이어야겠군요. 하지만, 메뉴 옵션은 메뉴와 함께 생기기 때문에 같은 경계 안에 들어가야 합니다.
경계 안에 함께 들어가는 객체들은 연관관계로 묶는게 좋습니다. 안 묶을 수도 있지만 묶는게 편합니다.
연관관계가 가장 강하기 때문에 찢는게 좋다고 하지 않았나요?
연관된 정보들을 같이 읽어야 하고, 같이 생성, 삭제, 수정되어야 하기 때문에 Cascade룰을 줄 수가 있습니다.
그럼, 객체 그룹끼리는 어떻게 소통하나요?
id를 참조해서 소통합니다. id를 사용해서 Repository를 통해 탐색이 가능합니다.
모든 것들은 객체 참조로 묶어도 안되고 모든 것들을 id로 떨어뜨려놔도 안됩니다. 우리 비즈니스가 어떻게 돌아가느냐에 따라서 이 객체의 그룹을 잘 찢어서 설계해주어야 합니다.
일단, 그룹 간에 객체 참조를 통한 연관관계를 제거해주셔야 합니다.
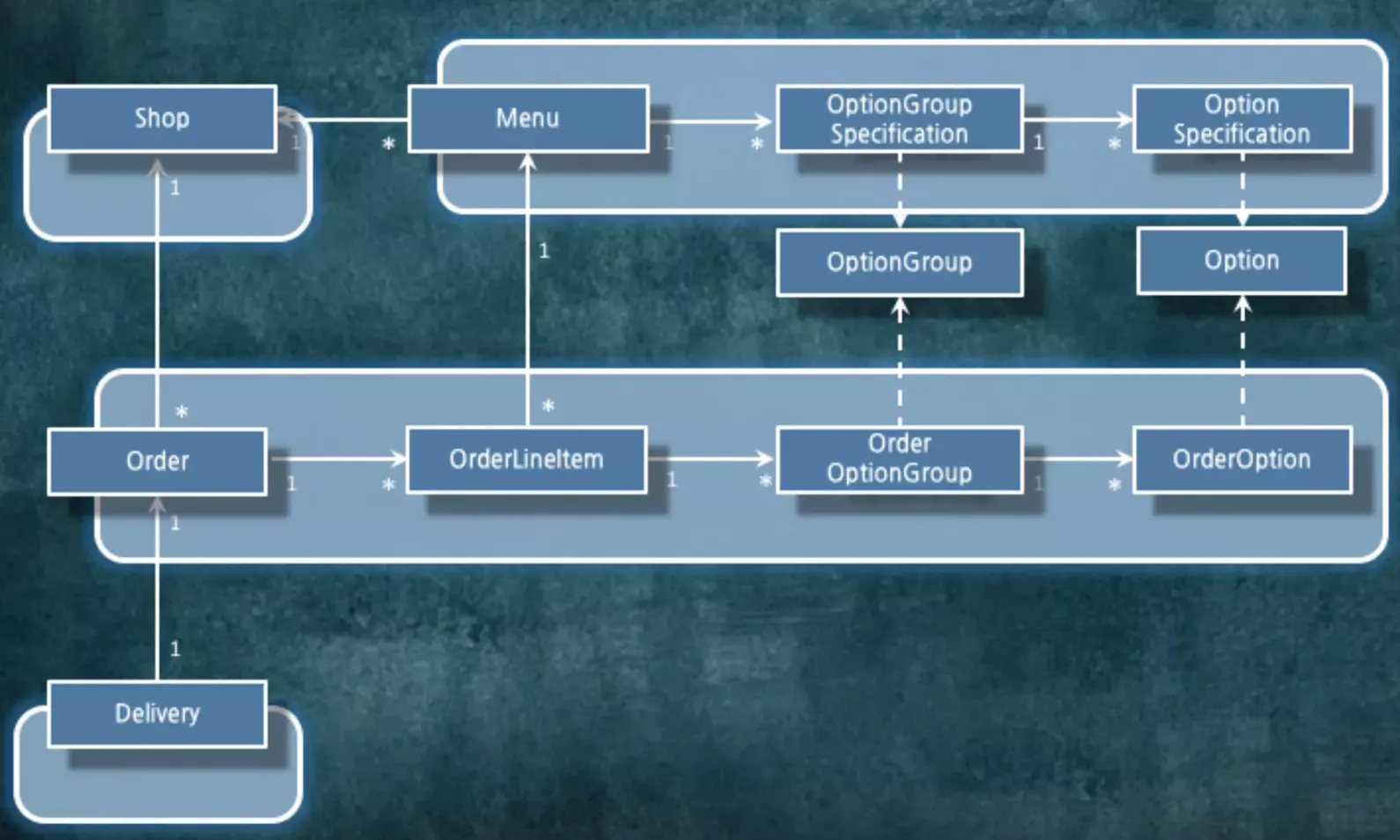
그룹 간에는 id를 통해서만 노출해주는게 좋습니다. Order에서 Shop를 찾고 싶다면 Order를 일단 가져온 다음 Order에 있는 shopId를 가지고서 Repository에서 Shop를 읽어오면 됩니다.
연관 관계를 끊고나면 객체 단위로 트랜잭션을 관리해주면 됩니다. 같이 변경되는 단위이기 때문에 트랜잭션 단위로 묶으면 어디서부터 어디까지 가져와야 하는지 판단이 섭니다.
일단, 참조없는 객체 그룹으로 나누고 나면 그룹 단위의 영속성 저장소를 변경할 수 있습니다.
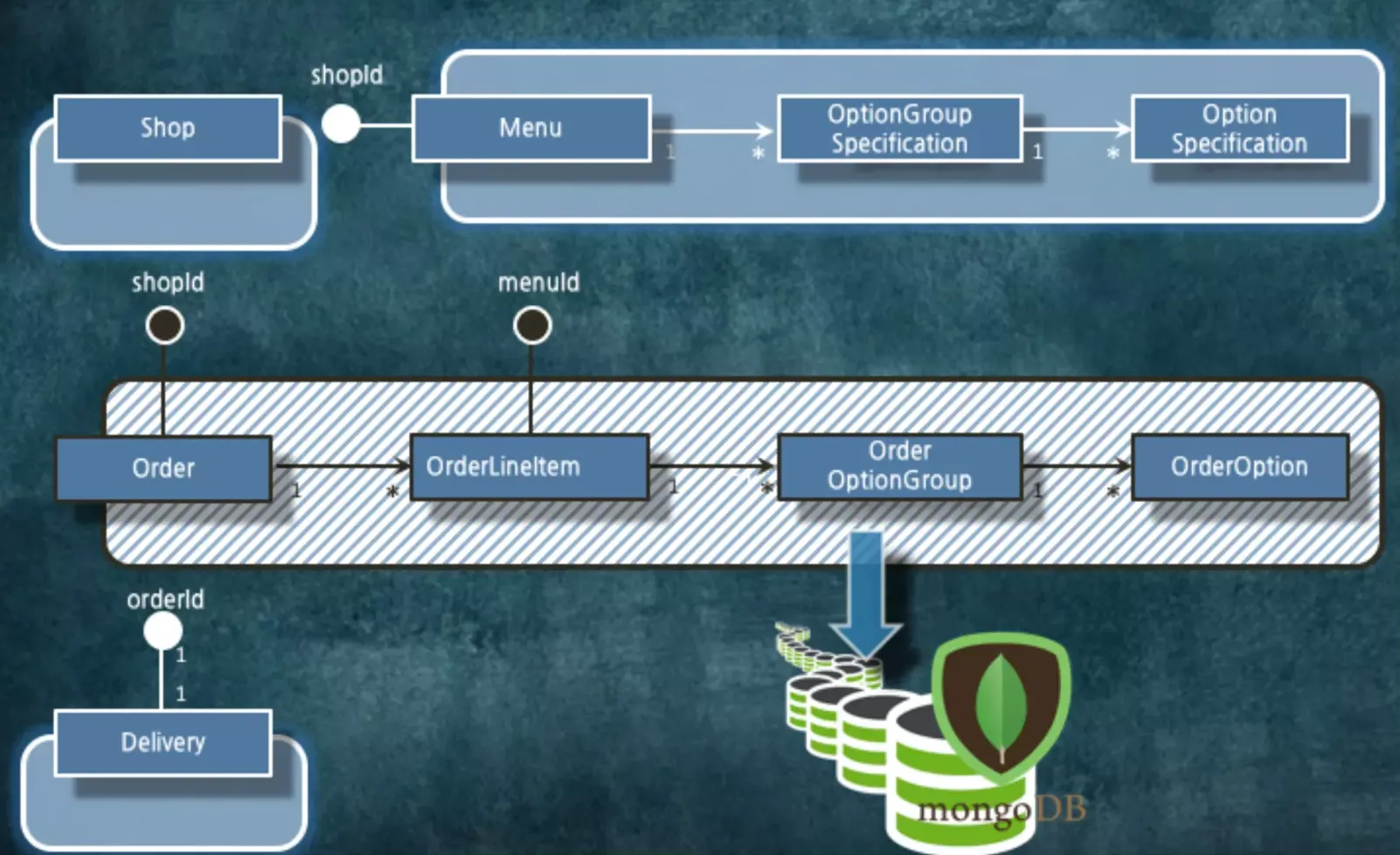
우리는 해당 객체 단위로 저장하면 됩니다. 어차피 해당 객체 단위로 한 번에 가져올거고 나머지 객체는 참조를 통해서 가져올 것이기 때문에 저 정보를 한방에 읽는 것이 좋습니다.
즉, 객체의 단위가 조회의 단위가 됩니다. 고민할 필요없이 해당 경계까지 데이터를 가지고 오게 됩니다. 그리고 DB의 트랜잭션의 단위가 됩니다.
이제 이전에 만든 코드를 수정하려고 하면 컴파일 에러가 발생합니다.
이전에는 “객체 참조가 있다” 생각하고 로직을 짰는데, 이제는 객체 참조없이 shopId를 통해서 Shop 객체를 참조해야 하기 때문입니다. 그러면, 객체를 직접 참조하는 로직을 다른 객체로 옮겨봅시다.
새로운 객체 OrderValidator를 만들어서 Validation Logic를 모읍시다.

이제 Order에서는 주문 검증을 하기 위해서 OrderValidator에 Order를 파라미터로 넘기면 됩니다.
class Order {
func place(orderValidator: OrderValidator) {
orderValidator.validate(self)
ordered()
}
}
Swift
복사
이렇게 하는게 좋은 설계일까요?
좋다고 생각합니다.
객체 지향은 여러 객체를 오가면서 로직을 파악해야 합니다. 따라서, Validation 로직을 탐색하는게 상당히 어렵습니다. 여러 객체에 해당 로직이 찢어져 있기 때문이죠. 하지만, 한군데에 모으면 한 눈에 보기가 쉬워집니다.
또한, Order 쪽에 해당 로직이 들어있었을 때는 Order의 응집도가 낮았습니다.
왜 Order의 응집도가 낮았나요?
Validation 로직과 주문 처리 로직이 함께 있기 때문입니다.
Validation 로직과 주문 처리 로직이 바뀔 때 변경의 주기가 다릅니다. validate() 메서드는 Validation 로직이 바뀔 때 수정됩니다. 주문처리 메서드는 주문 처리 로직이 바뀔 때 변경됩니다.
주기가 다른 것들이 한 군데에 섞이게 된겁니다. 저걸 들어내면 주문 처리만 Order 객체에 남게 됩니다.
즉, Order가 높은 응집도의 객체가 됩니다.
때로는, 절차지향이 객체지향보다 좋은 경우가 존재합니다. 그냥 전체 플로우를 한눈에 보는게 더 좋을수도 있습니다. 우리는 validate를 객체 안에 넣어야 한다는 강박 관념 지니고 있습니다. 하지만, 그렇지 않습니다.
객체 안에 상태를 조금 체크해야하는거라면 객체 안에 들어있는게 맞겠지만, 그 객체의 상태를 validate하기 위해서 여러 객체가 협력하면 객체의 응집도를 낮추게 됩니다.
따라서, 해당 로직을 찢어내는 것이 맞습니다. 그게 객체의 결합도를 높이면서도 응집도를 낮추는 방법입니다.
주문 검증뿐만 아니라 배달 완료 부분에서도 컴파일 에러가 발생합니다.
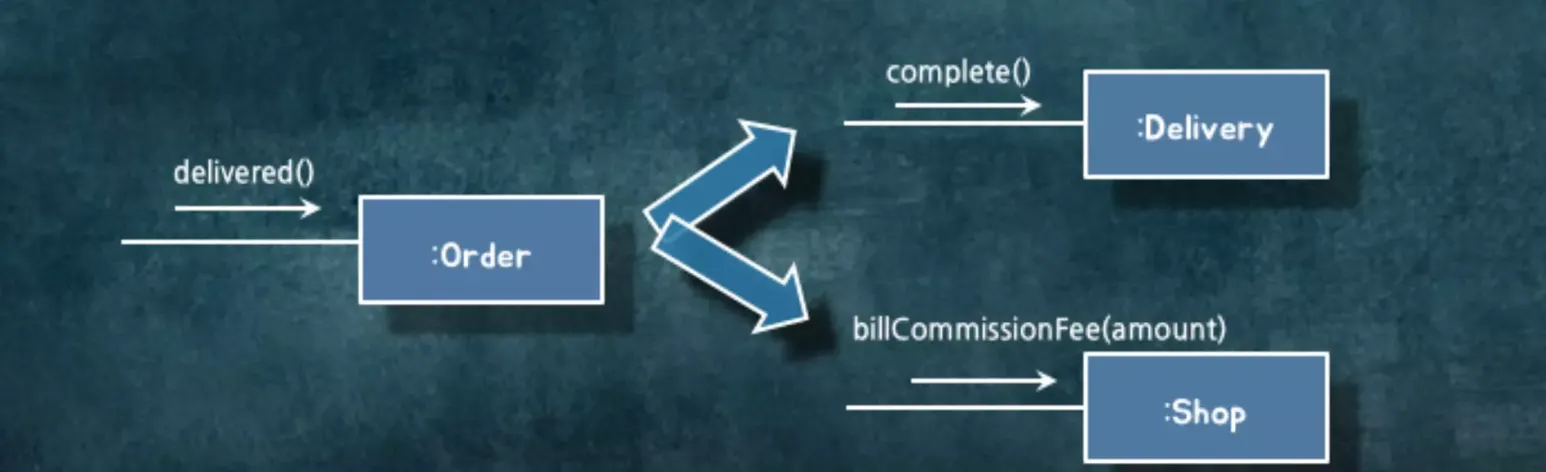
이 부분은 도메인 로직이 순차적으로 실행되기에 문제가 발생하게 됩니다. A로직이 실행되었을 시에 다른 것도 실행되어야 한다는 도메인 제약사항에 의해서 문제가 발생하는 겁니다. 어떤 객체가 바뀔 때, 그 결과로 어떤 객체가 바뀌어야 한다는 변경의 순서 즉, 전후관계가 있기 때문에 문제가 발생합니다.
그럼 어떻게 해결할 수 있을까요?
1.
절차지향 로직 사용
이전처럼 OrderDeliveredService를 추가합니다. 그리고 배달 완료 로직을 다 끌어다 넣습니다. 이렇게 되면 절차지향적인 코드가 완성됩니다.
이전에는 주문 완료 시 클래스가 쪼개져 있었기 때문에 Order도 상태를 바꾸고 Shop도 상태를 바꿔야 했습니다. 즉, 비즈니스 플로우가 한 눈에 보이지 않았습니다. 하지만, 이젠 플로우를 묶었기 때문에 한 눈에 보이게 됩니다. 주문 완료 시에 어떤 작업이 실행되어야 하는지 한눈에 보입니다.
하지만, 정말 잘 된 설계일까요?
우리는 꼭 의존성을 그려봐야 합니다.
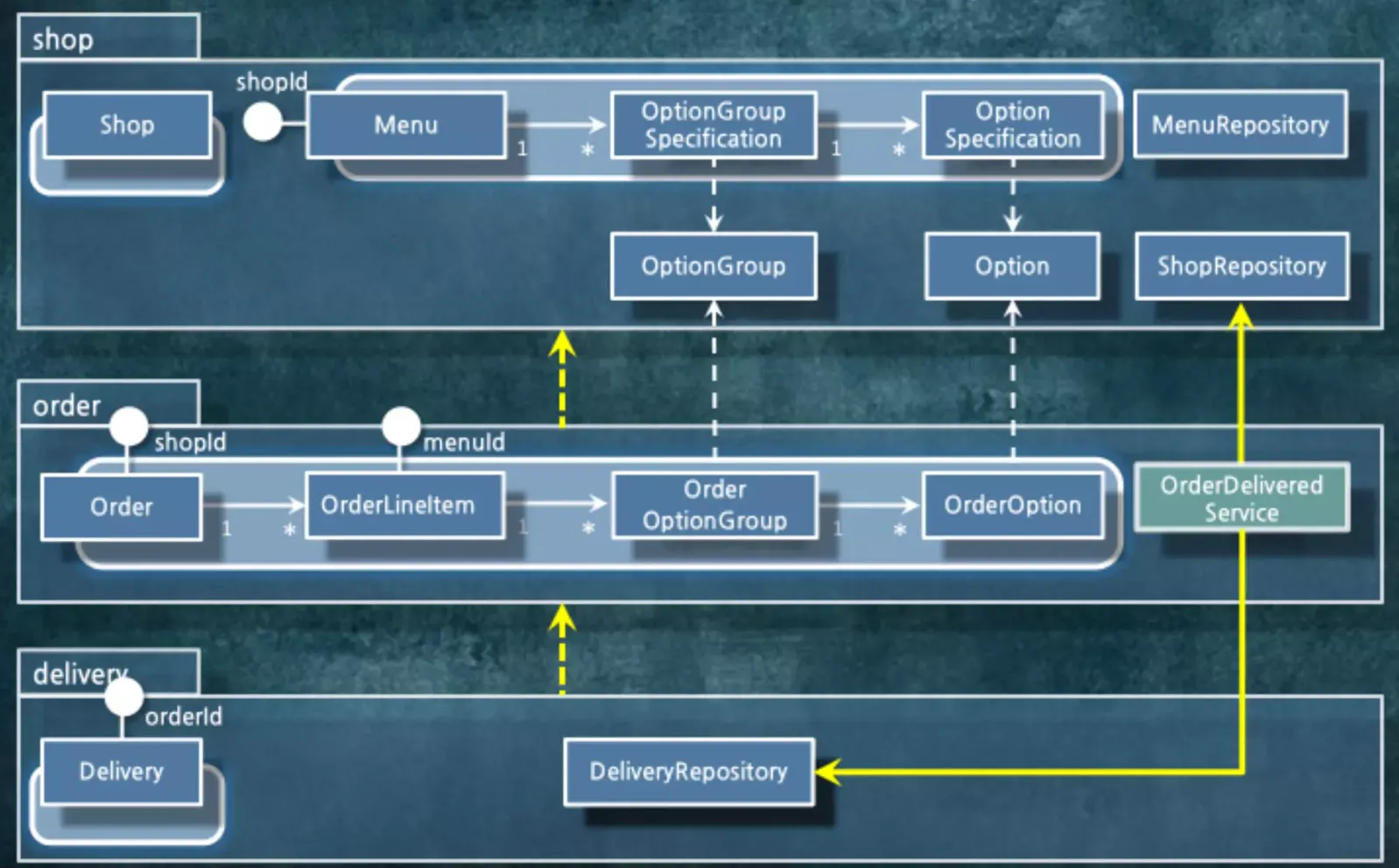
OrderDeliveredService가 Shop, Delivery, Order를 가져오면서 Dependency가 저렇게 생겼습니다. 의존성 사이클이 생겨버린겁니다.
이 경우에는 인터페이스를 이용해서 의존성을 역전시켜야 합니다. 의존성 역전 원리를 적용하는 겁니다.
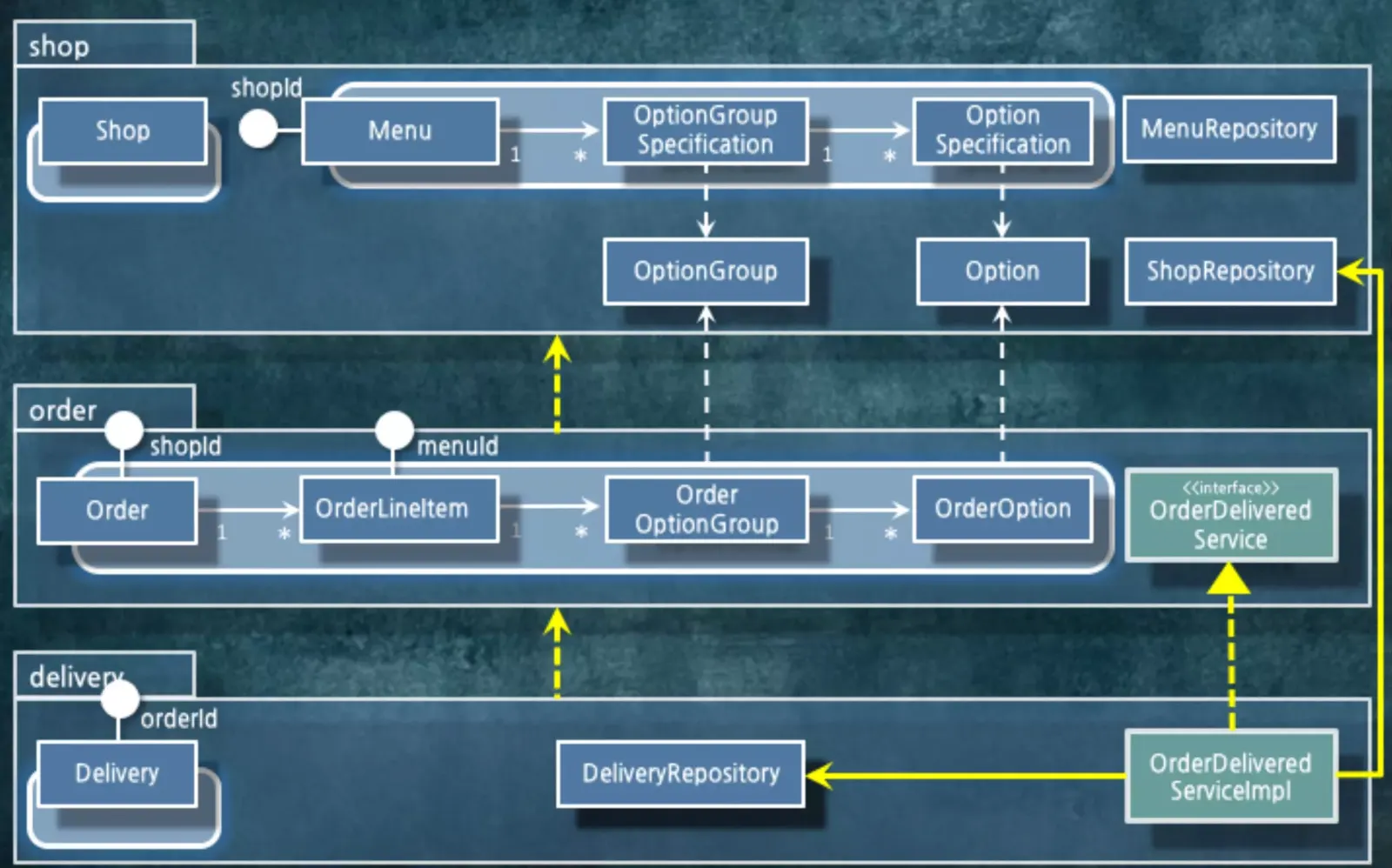
인터페이스를 만들고 구현부를 Delivery 쪽으로 밀어 넣었습니다. 실제로 주문이 완료된 인터페이스는 Order 쪽에 있고 그걸 실제로 실행하는 쪽은 Delivery에 있습니다. 이렇게 의존성을 역전시키게 해주는 겁니다.
의존성이 한 방향으로 흐르게 되는겁니다.
2.
도메인 이벤트 퍼블리싱
위에서 발생한 문제점은 Order가 바뀌었을 때, Delivery, Shop도 바뀌어야 하는 문제였습니다.
1번 방식을 사용해서 Service를 하나로 뭉쳐서 한눈에 보기 쉽게 할 수 있습니다. Service로 묶는 방식은 객체 참조로 결합되어 있는 것들을 로직안에 한군데 모아서 객체 간의 결합도는 낮지만 로직간의 결합도는 명확하게 보여줄 수 있습니다.
하지만, 이번에는 도메인 이벤트를 사용해서 잘게 찢을 겁니다. A가 끝나면 B, C가 실행하면 좋겠는데 이 순서를 느슨하게 만들고 싶다면 도메인 이벤트를 사용하면 됩니다.
Order의 상태가 바뀌면 OrderDeliveredEvent를 발행하는 겁니다. Shop과 Delivery는 이벤트를 받아서 상태를 바꿉니다. 이는 메세징과 상관이 없습니다. 메모리 상에서 돌아간다고 보면 됩니다.
⓵ Order에 delivered()라는 메세지가 도착합니다.
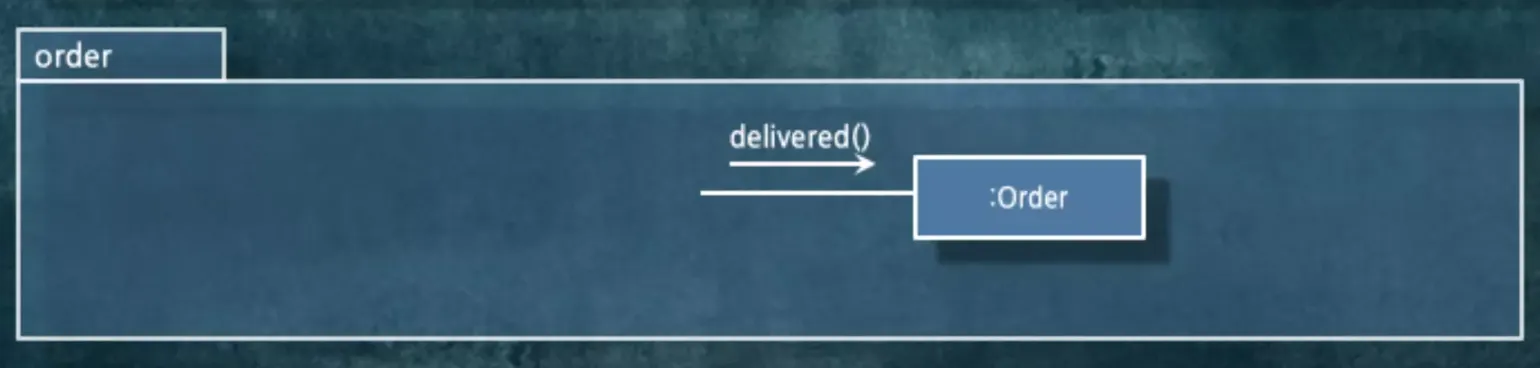
⓶ Order에서는 이벤트를 발행합니다.
누가 해당 이벤트를 받을지 생각하지 않고 발행합니다. 각 event handler에서 이벤트를 받아서 메서드를 콜하게 됩니다.
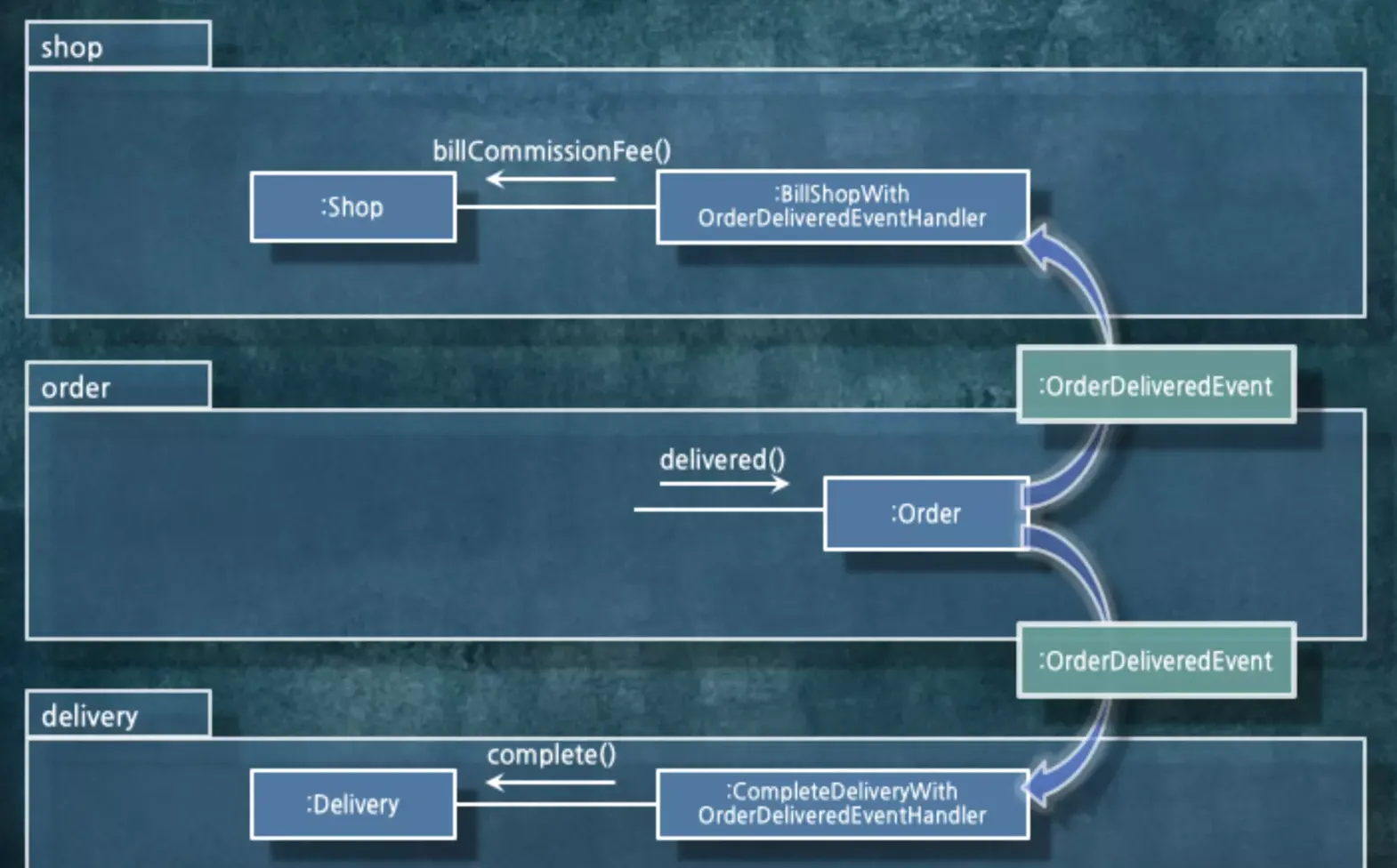
Order가 Shop를 직접 호출하던 로직은 도메인 이벤트를 발행하도록 수정됩니다. 이렇게 되면 의존성이 끊어지게 됩니다.
그러면 다시 의존성이 어떻게 되는지 봅시다.
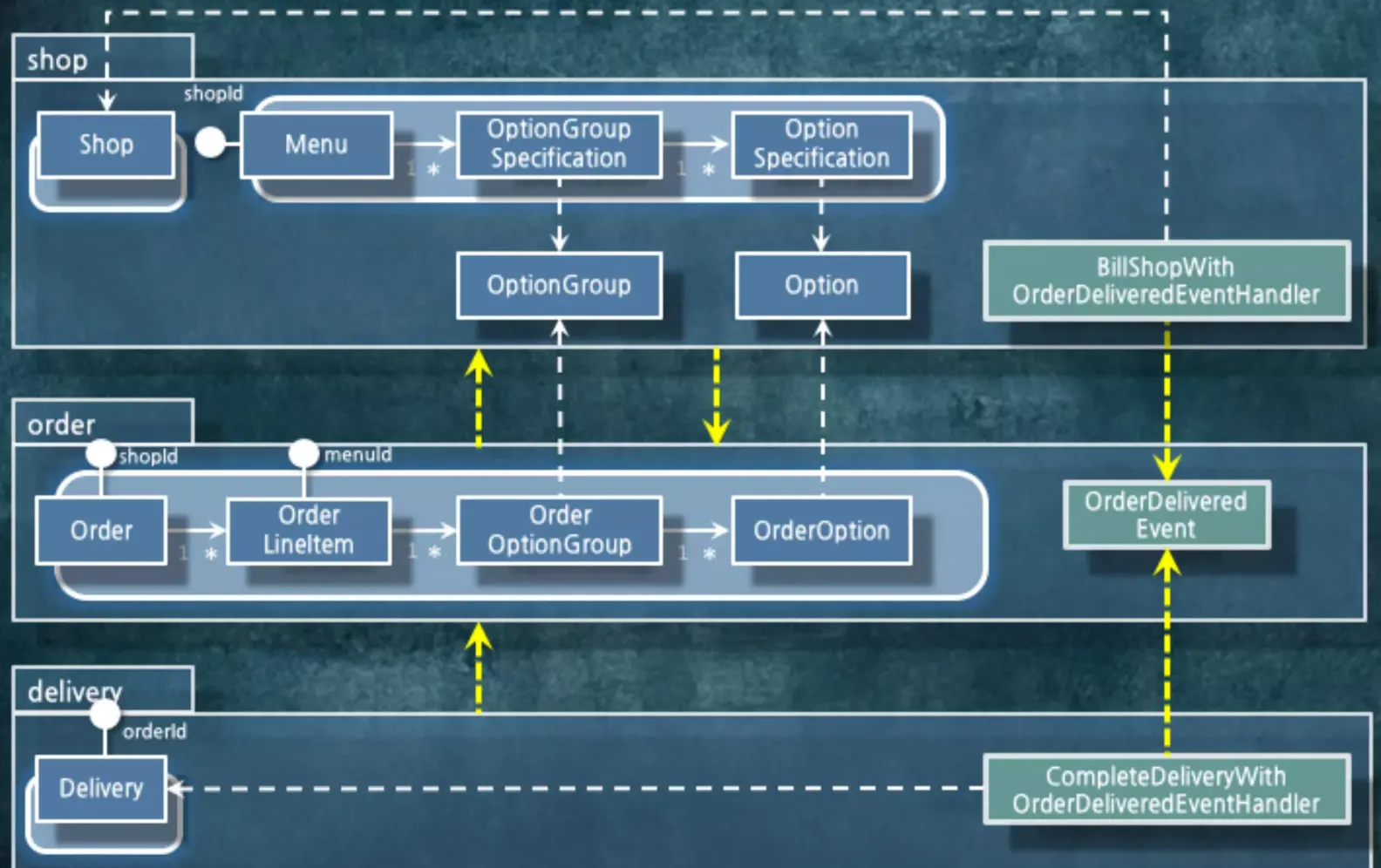
의존성 사이클이 존재하네요. ( •̀ o •́ )
왜 의존성 사이클이 존재하는걸까요?
파라미터를 통해서 이벤트를 받고 있습니다. 일시적으로 파라미터를 받는 의존 관계가 생기게 됩니다. 그래서 패키지에서 사이클이 돌게 됩니다. 이벤트 핸들러가 Shop 패키지에 있기에 생기는 문제입니다.
그래서 패키지를 분리해버렸습니다.
이벤트 핸들러가 의존하는 코드를 Shop에서 분리했습니다. 원래 Shop이 가진 로직과 정산 로직을 분리했습니다.
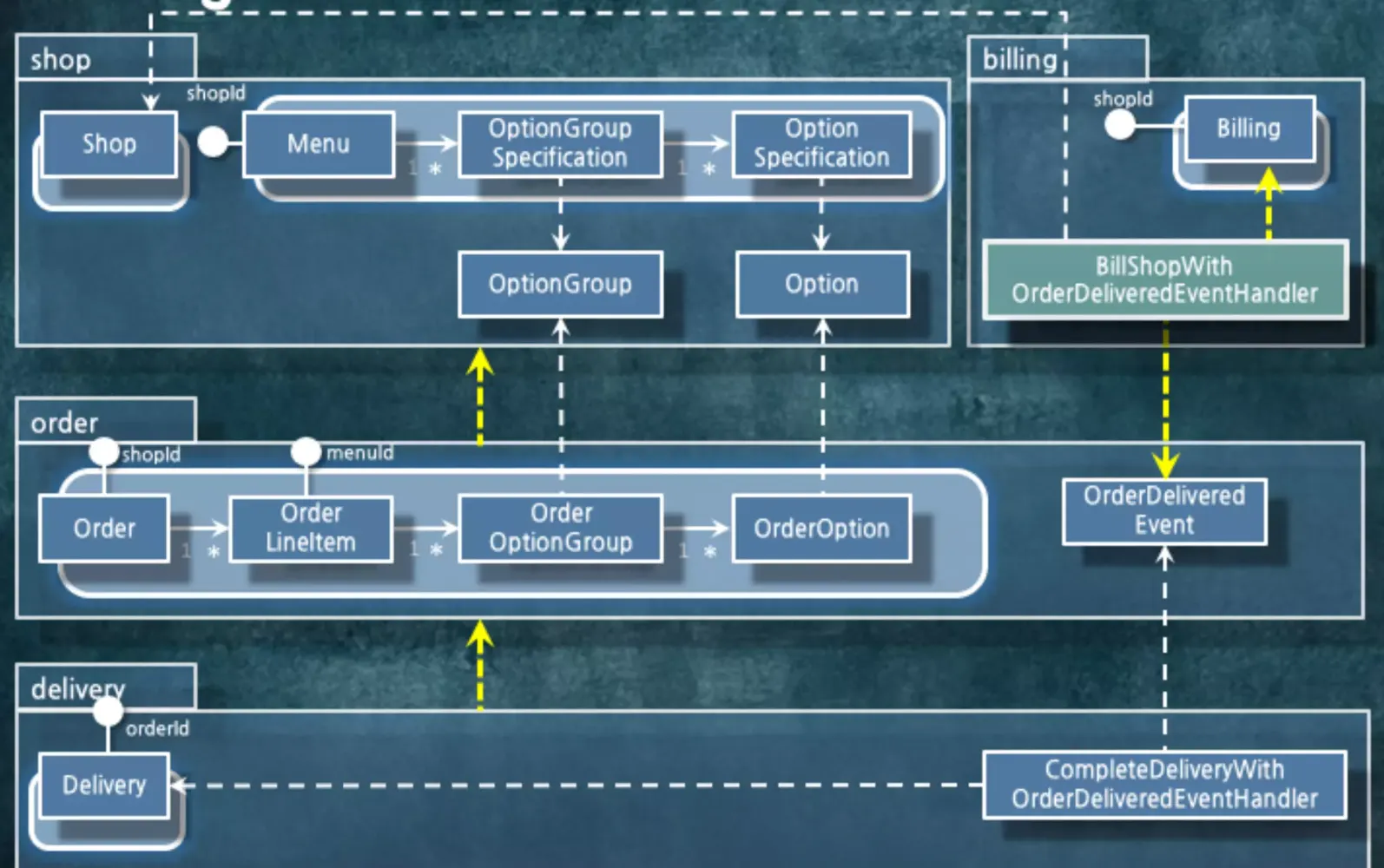
그러면 의존성 사이클이 제거됩니다.
패키지를 찢어야지 도메인 개념이 명확해지는 경우가 있습니다. Shop 안에 정산 로직이 있었는데, 해당 로직을 Shop이 가지고 있는게 이상합니다. 하지만, 해당 로직을 Shop이 계속 가지고 있었기 때문에 사이클이 발생할 수 밖에 없었습니다.
따라서, 패키지를 찢을 때는 도메인적으로 명확한 새로운 개념이 필요해서 찢어내자는 의사 결정에 의해서 찢어내야 합니다. 의존성을 쫓아가다보면 도메인 개념, 관점이 바뀔 때가 많습니다.
패키지 간에 사이클이 생성됐을 때는,
어떤 방식을 사용할지는 판단에 따라 달라집니다.
의존성을 관리하면 시스템을 쉽게 분리할 수 있게 됩니다. 의존성 관리가 안된 상태에서 도메인 단위로 패키지를 나누면 의존성이 장난아니게 됩니다. 의존성이 돌고 돌아버립니다.
대부분의 Dependency를 관리하지 않는 경우는 패키지 안으로 모든 걸 집어넣고 그 안에서 의존성을 관리하면 됩니다.
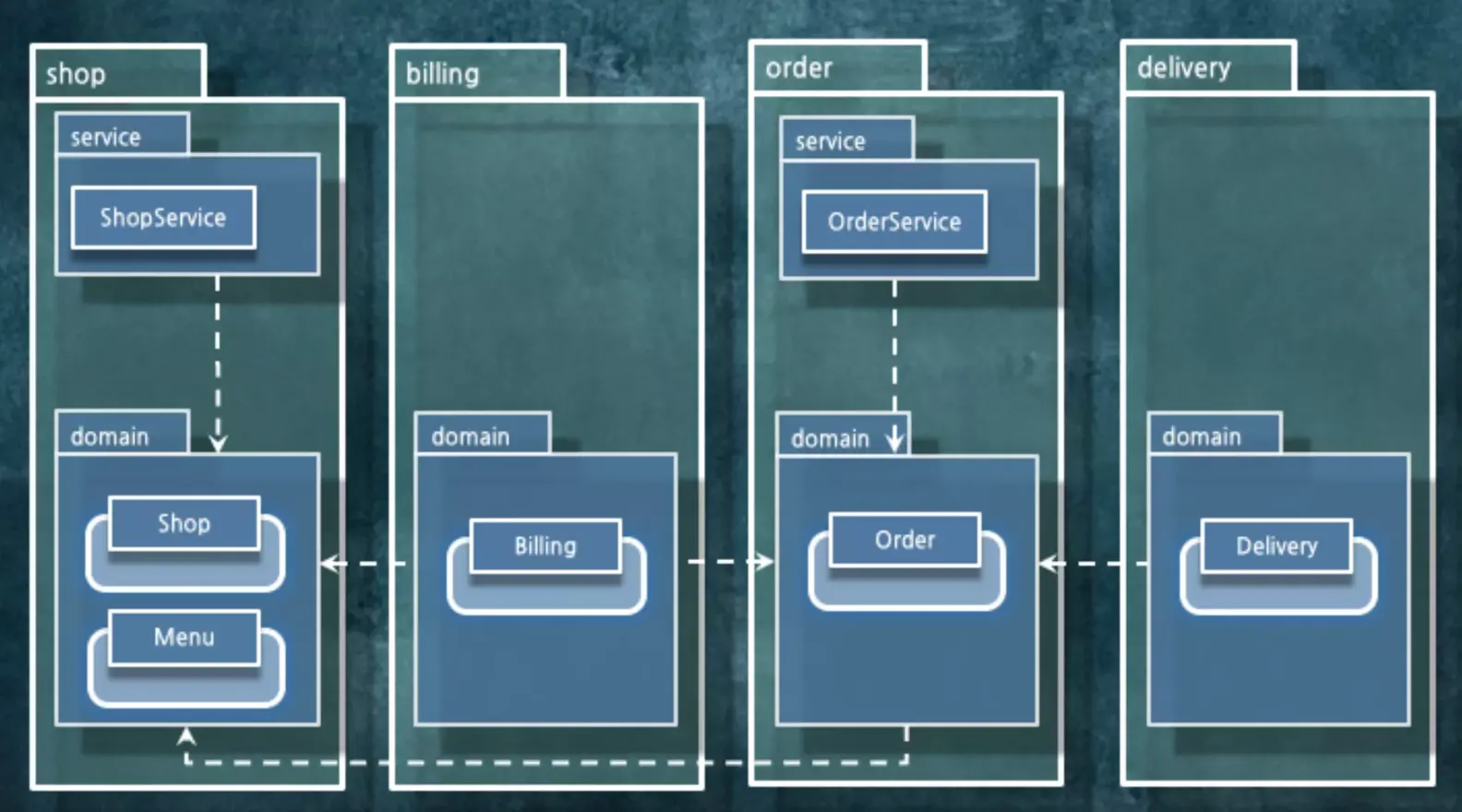
하지만, 의존성 관리를 잘하고 의존성 컨트롤이 가능해지면 패키지를 도메인 단위로 모듈화할 수 있게 됩니다. 도메인이 앞으로 나오고 그 안에 레이어를 배치하게 되는거죠. 대신 각각은 도메인 이벤트를 통해서 협력을 하게 됩니다. 이렇게 하면 시스템을 분리하기 좋아집니다.
시스템을 분리하기 위해서는 노력이 더 들어가겠지만 의존성을 관리하지 않을때보다는 훨씬 더 시스템을 찢어내기가 편해집니다. Shop, Biling, Order, Delivery는 비즈니스적으로 하나로 돌아가는 단위가 됩니다.
Order와 관련된 건 Order 안에 다 들어있고, 이걸 뜯어냈을 때 의존성이 딸려오겠지만 무질서하게 섞여 있었을 때보다는 최대한 찢어내기가 편해졌습니다. 시스템적으로도, 물리적으로도 찢어내기가 편해진겁니다.
도메인 이벤트로 발행했던 것들은 시스템 내부에서는 객체 참조로 넘어가도 됩니다. 시스템 외부로 가는 건 internal를 external로 바꿔서 시스템간의 통신을 하면 됩니다.
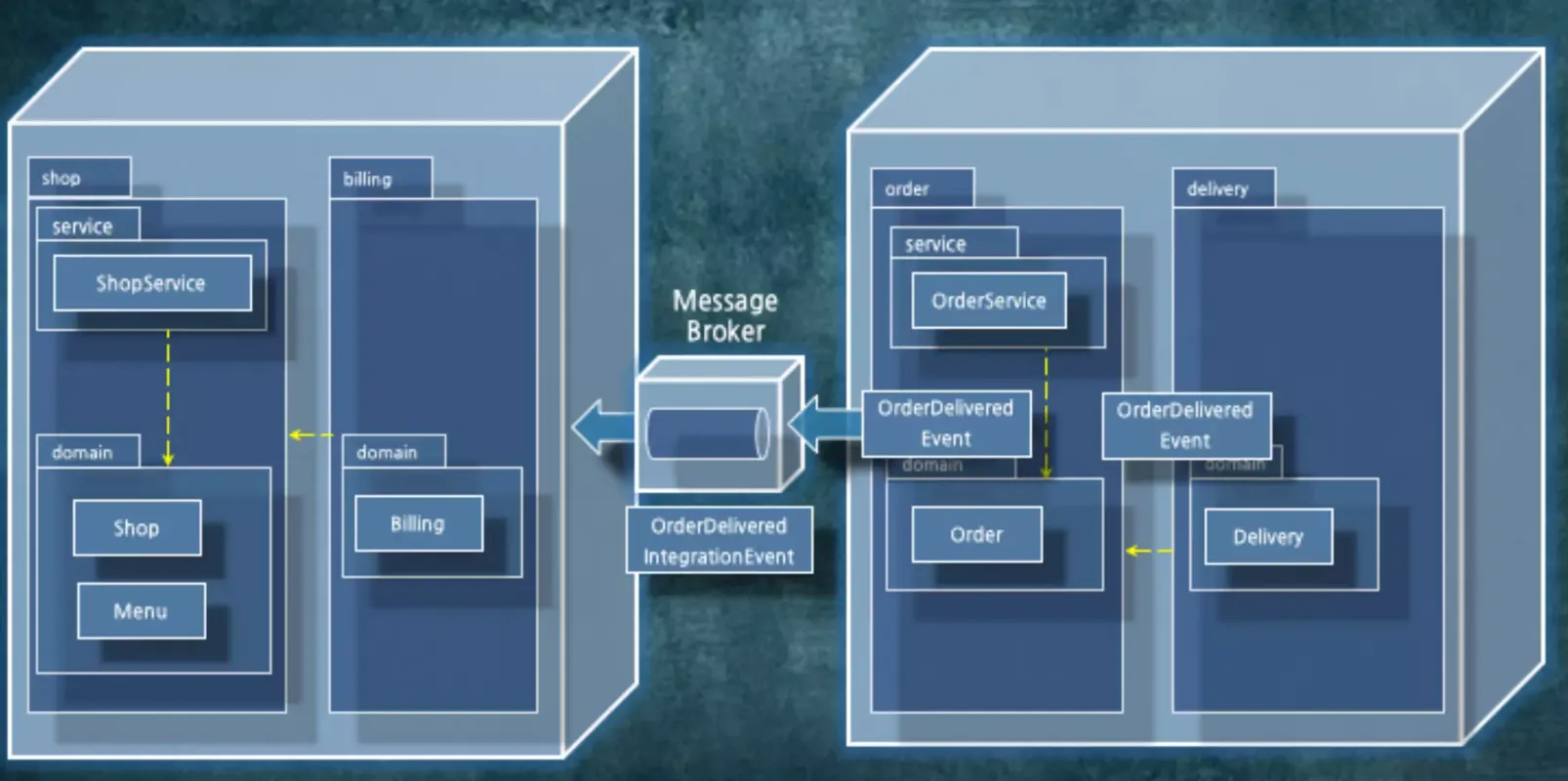
주문 완료가 되었을 때, OrderDeliveredEvent를 발행합니다. 내부 이벤트는 IntegrationEvent로 바뀌어서 Message 큐로 들어갑니다. 그리고 Shop쪽으로 발행됩니다. Shop에서는 알아서 해당 메시지를 처리하게 됩니다.
한 통으로 들어가도 dependency 관리는 해줘야 합니다.
시스템을 찢고 싶을 때, 의존성이 너무 큰데 대책없이 찢게 되면 힘들어 집니다. 하나를 바꾸면 다른 하나가 우루루 딸려오기 때문이죠. 시스템 관리 시에 의존성 관점에서 보고 어떤 타이밍에 어디서 끊어야하는지 명확하게 판단해야 합니다.
시스템을 볼 때에는 의존성을 보고 의존성에 따라서 진화를 시키면 됩니다.