

contents
들어가며
물리적인 메모리의 주소변환은 운영체제가 관여하지 않습니다.
 가상 메모리 기법은 전적으로 운영체제가 관리하고 있습니다.
가상 메모리 기법은 전적으로 운영체제가 관리하고 있습니다.가상 메모리 : 실제로는 그렇게 큰 메모리가 있지 않지만 사용자로 하여금 무한정의 큰 메모리가 있게끔 느껴지게 하는 메모리 시스템
주소가 실제 메모리에 있는 주소와 달라서, 메모리상의 주소로 변환이 필요할 때 하는 것이 사상(mapping)
•
프로그램에서 참조하는 주소 = 가상 주소(Virtual Address)
•
실제 메모리상의 주소 = 실주소(Real Address)
왜 주소를 서로 다르게 지정할까?
프로세스와 페이지 테이블
mapping에 걸리는 시간을 최소화하자(with 하드웨어)
가상 메모리 관리를 위한 다양한 기법들
Demand Paging
페이징 기법을 기본으로 하여, 요청이 있으면 그 페이지를 메모리에 올리겠다는 기법
•
대부분의 시스템은 페이징 기법을 사용합니다.
◦
Paging : 프로그램이 실행될 때, 프로세스를 구성하는 주소 공간에 페이지를 한꺼번에 올림.
◦
Demand Paging : 그 페이지가 요청이 됐을 때, 그 때 그 페이지를 메모리에 올려둠.
•
무슨 효과가 있나요??
1.
I/O 양이 상당히 감소합니다.
빈번히 사용되는 부분이 지극히 제한적, 좋은 소프트웨어 일수록 방어적으로 소프트웨어를 만들기 때문에 이상한 사용자가 이상한 짓을 하더라도 문제가 생기지 않도록 하는 방어적인 코드가 대부분을 차지합니다(보안 코드).
그런 코드는 대부분의 경우 사용이 안되는데, 그 페이지들을 한꺼번에 메모리에 올려둔다면? “메모리가 낭비가 된다.”
Demand Paging를 사용하면 필요한 페이지만 올려두기 때문에 I/O 양이 상당히 감소하게 된다.2.
물리적 메모리 사용량이 감소합니다.
현대 프로그램처럼 멀티 프로그래밍 환경(프로그램 여러개가 동시에 메모리에 올라가게 되는 그런 환경)에서는 더 많은 프로그램, 더 많은 사용자가 동시에 메모리에 올라갈 수 있어서 훨씬 효과적
3.
빠른 응답 시간을 기대할 수 있게 됩니다.
물론 빠른 응답 시간은 생각하는 관점에 따라서 좀 다를수도 있을 거 같습니다.
: “프로그램이 시작될 때 통째로 메모리에 올려놓으면 그 다음부터는 응답 시간이 안 필요한거 아님? 디스크에 갔다 올 필요가 없는데?”
: 그렇지만 여기서 빠른 응답 시간이라는 건 시스템 와이드하게 생각하자면 한정된 메모리 공간에 여러 프로그램이 동시에 실행이 되고 그러면 메모리에 더 빈번하게 사용될, 의미있는 정보를 올려두려는 노력인 거 같습니다. 따라서 “Demand Paging를 사용하는 게 맞다."는 것이죠.
한정된 메모리 공간을 더 잘 사용해서 디스크에 I/O가 줄어들고 메모리에서 직접 서비스하는 비율이 높아져서 응답 시간이 더 좋아진다.Memory에 없는 Page의 Page Table
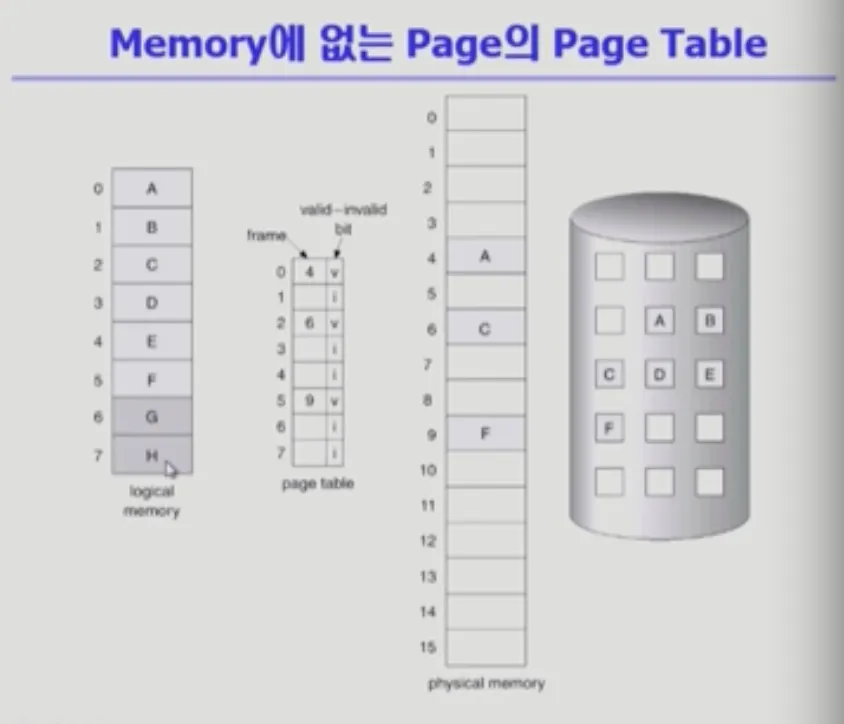
왼쪽부터 - 논리적 메모리, 페이지 테이블(주소 변환 정보), 물리적 메모리, 디스크
이 프로그램을 구성하는 페이지 중에서
•
당장 필요한 페이지 : 물리적인 메모리(physical memory)
•
당장 필요하지 않은 페이지 : 디스크(패킹 스토어, Swap area)
•
페이지 테이블 entry마다 valid/invalid bit이 존재합니다.
◦
Invalid의 의미
1.
물리적인 메모리에 없는 경우
•
사용하지 않아서 패킹 스토어에 내려가 있는 경우
2.
사용되지 않는 주소 영역인 경우
•
페이지 테이블 entry는 주소 공간의 크기만큼 만들어지기 때문에 사용되지 않는 주소 영역 존재
Example
프로그램을 구성하는 페이지 : A-F
사용이 안되는 페이지 : G,H
•
주소 공간에서 0~7까지의 주소 영역을 지원해주기 때문에 페이지 테이블에는 entry가 만들어지고 사용이 안되는 페이지에 대해서 invalid bit로 표시한다.
•
1, 3, 4는 사용이 되지만 물리적인 메모리에 올라가있지 않고 패킹 스토어에 있기 때문에 주소 변환을 통해서 물리적인 프레임 번호를 얻을 수 있는 경우에만 valid bit로 표시된다.
•
Demand paging을 쓰기 때문에 프로그램을 최초로 실행시키면 invalid로 되어 있다가 페이지가 올라가면 valid로 바뀌면서 해당하는 페이지 프레임 번호가 적힌다.
•
page fault trap
1. cpu가 logical address를 주고 메모리 몇 번지를 보겠다고 함 |
2. 주소 변환을 하러 감 |
3. invalid라면 일단 그 페이지를 디스크에서 메모리로 올림(I/O작업, 사용자 프로세스가 못하는 일) → page fault |
4. page fault(요청한 페이지가 메모리에 없는 경우)가 나면 cpu는 자동적으로 OS한테 넘어감 → page fault trap |
5. OS가 cpu를 가지고 fault나는 페이지를 메모리에 올리는 작업 진행함(소프트웨어 interrupt) |
Page Fault
*Page Fault에 관한 처리 루틴은 운영체제에 정의가 되어 있습니다.
if, entry에 invalid가 있는 페이지에 접근을 하면
1.
주소 변환을 해주는 하드웨어가 트랩을 발생 시킨다. → page fault trap
2.
cpu가 자동적으로 OS한테 넘어오게 된다.
3.
OS에 page fault를 처리하는 코드, page fault handler가 실행되게 된다.
•
page fault handler가 하는 일
1. Invalid reference?
잘못된 요청이 아닌지, address가 잘못되어 있지 않은지, 이 프로세스가 사용하지 않는 주소는 아닌지, 접근 권한에 대한 violation은 안했는지 확인한다.
강제로 abort를 시키는 절차 진행 |
2. Get an empty page frame
만약 비어있는 페이지 프레임이 없고 꽉 차있다면 빈 페이지를 하나 획득하기 위해 하나를 쫓아내야 한다.(replace) |
3. 해당 페이지 disk에서 memory로 읽어오기
빈 페이지가 획득이 됐다면 디스크에서 메모리로 올려놓게 된다. |
3-1. cpu를 page fault난 프로세스로부터 뺏기
이 작업은 대단히 느린 작업이다. 메모리보다 디스크가 수십만배~백만배 느리기 때문이다.
page fault에 대해서 디스크 I/O를 하게 되면 이 프로세스가 cpu를 계속 가지고 있어봐야 cpu 낭비가 된다.
cpu를 page fault난 프로세스로부터 뺏어서 이 프로세스의 상태는 block으로 만들어두고 당장 cpu를 사용할 수 있는 ready 상태 프로세스에게 cpu를 넘겨줘야 한다. |
3-2. Disk I/O
ready 상태 프로세스로 넘기기 전에 디스크 컨트롤러에게 “디스크에서 그 페이지를 읽어와라” 부탁한다.
나중에 Disk I/O가 끝나면 interrupt가 걸린다. |
3-3. page fault났던 프로그램이 cpu를 다시 잡음
entry에다가 valid로 표시해두고 해당하는 페이지 프레임 번호를 적는다.
page fault났던 프로그램이 cpu를 다시 잡게 되면 메모리 주소 변환을 해도 page fault가 나지 않고 MMU에 의해서 정상적으로 주소 변환을 진행하게 된다. |
4. 이후 부분 계속 실행 |
Steps in Handling a Page Fault
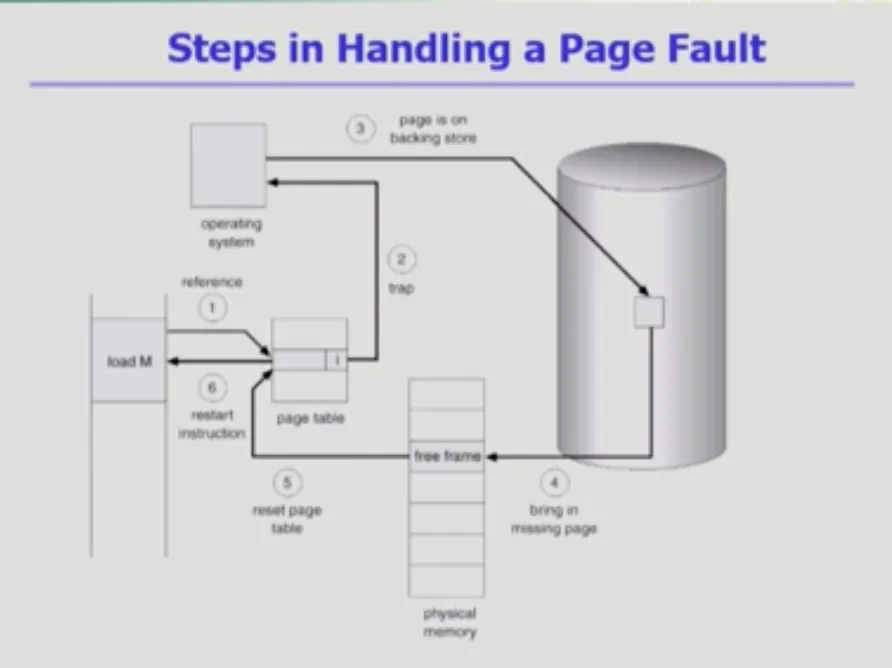
1. 메모리 레퍼런스에 있었는데 주소 변환을 하려고 보니 invalid로 표시되어 있음 |
2. 페이지가 메모리에 올라와 있지 않다는 얘기니깐 trap이 걸려서 cpu가 OS에게 자동으로 넘어감 |
3. OS는 패킹 스토어에 있는 페이지를 물리적 메모리에 올려둠 |
3-1. 만약 빈 페이지 프레임이 없다면 뭔가를 쫓아내고서 거기다가 올려야 하는 작업을 올리면 됨 |
4. 해당하는 프레임 번호를 entry에 적어두고 invalid였던걸 valid로 바꾸는 작업을 진행함 |
5. 나중에 cpu를 다시 얻어서 주소 변환을 하게 되면 valid로 되어 있어서 주소 변환 정상적으로 진행함 |
6. 해당하는 물리 메모리의 페이지 프레임에 접근 가능해짐 |
•
page fault가 일어났을 때, 디스크에 접근하는 건 대단히 오래걸리는 일이다.
page fault가 얼마나 나는가에 따라서 메모리 접근 시간이 크게 좌우된다.Performance of Demand Paging
*page fault rate를 이렇게 잡았다고 합시다.
•
: 절대 page fault가 나지 않는다. 메모리에서 다 참조해온다.
•
: 매번 메모리 참조를 할 때마다 page fault가 난다.
•
실제로 page fault rate는 어느정도 되는가?
거의 0에 가깝게 나옵니다. 대부분의 경우에 page fault가 안나지만 page fault가 한 번 났다면 엄청난 시간을 겪어야 합니다.
•
메모리 접근하는 시간을 page fault까지 감안해서 계산을 해보면 아래 식처럼 나옵니다.
◦
: page fault가 안나는 비율 (*memory access 시간만 걸림)
◦
: page fault가 나는 비율 (*엄청난 시간)
엄청난 시간
Page replacement
빈 페이지가 없는 경우, 어떤 페이지를 메모리에서 쫓아내고 그 자리에 새로운 페이지를 올려놓는 OS 업무
이 작업을 해주는 알고리즘이 replacement algorithm 입니다.
•
replacement algorithm
메모리에서 쫓아냈더니 그 페이지가 다시 참조된다면 엄청난 시간을 겪어야 하기 때문에 가능하면 page fault가 나지 않는 선에서 페이지를 쫓아내면 좋겠죠.
page fault rate가 0에 가깝게 되는 것이 알고리즘의 목표입니다.
◦
reference string
시간 순서에 따라서 페이지들에 서로 다른 번호를 붙여두고 페이지들이 참조된 순서를 나열해 둔 것
•
Page Replacement(OS)
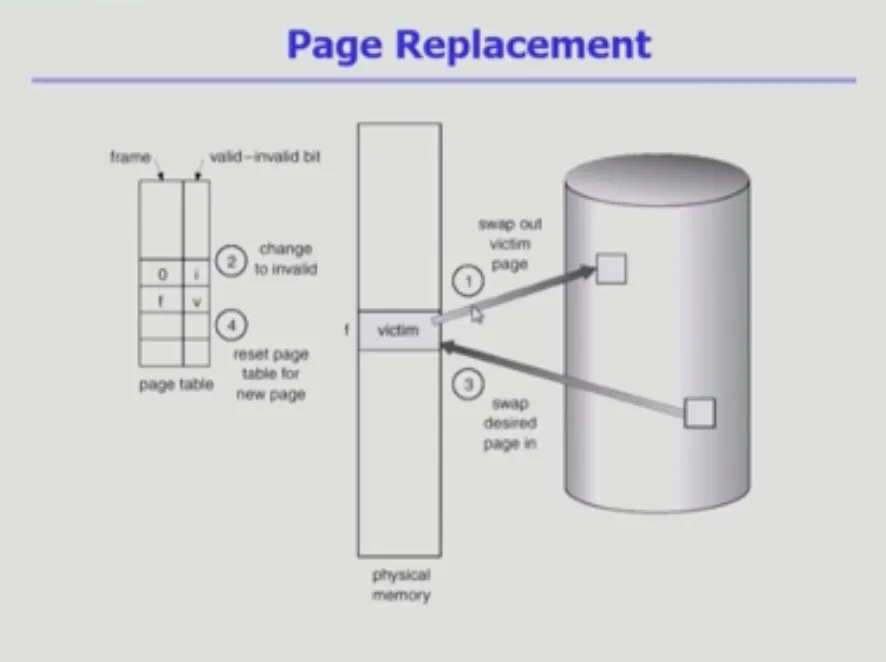
1. 어떤 걸(victim) 쫓아낼 지 결정한다. |
2. Disk로 쫓아낸다. |
2-1.
만약 디스크에서 메모리로 올라온 이후에 내용이 변경됐다고 하면(write) victim를 쫓아내기만 하면 되는 게 아니라 쫓아낼 때 변경된 내용을 메모리에서 패킹 스토어에 써주어야 한다. |
2-2.
메모리로 올라온 이후에 victim이 쫓겨날 때까지 변경된 게 없다면 그냥 메모리에서 지우기만 하면 된다. |
3. 새로운 페이지를 넣는다. |
3-1.
쫓겨난 페이지에 대한 테이블 entry를 invalid로 변경하고, 메모리로 올라온 페이지에 대해서는 프레임 번호를 entry에 적고 valid로 변경한다. |
•
도대체 어떤 알고리즘이 가장 좋은 알고리즘이냐
알고리즘 중에서 가장 좋은 알고리즘은 Optimal Algorithm입니다.
Demand Paging 상황에서는 page fault를 가장 적게 하는 알고리즘이 가장 좋은 알고리즘 입니다.
Optimal Algorithm
실제 시스템에서는 미래를 알 수 없기 때문에 이걸 쫓아내야할지 말아야 할 지 결정하기 힘듭니다. 따라서 Optimal Algorithm에서는 미래에 참조되는 페이지를 안다고 가정을 하고 진행합니다.

*실제 시스템에서는 사용될 수 없기때문에 Offline Optimal Algorithm 입니다.
•
알고리즘이 어떻게 운영되는가?
가장 먼 미래에 참조되는 page를 replace합니다.
1. 처음 참조되기 때문에 참조할 때 page fault가 발생한다.(빨강) |
2. 이미 올라와 있어서 메모리 참조가 진행된다.(연보라) |
3. 5번의 page fault가 난다. |
4. 메모리가 꽉 차서 어느 하나 쫓아내야 하는데, 가장 먼 미래에 참조되는 Page순으로 교체가 일어난다. |
4-1. 1, 2, 3, 4 순으로 참조되기 때문에 4번을 쫓아내고 5번을 집어넣게 된다. |
5. 총 6번의 page fault가 발생한다. |
어떤 알고리즘을 쓰더라도 page fault가 6번보다 더 적게 낼 수는 없습니다.
다른 알고리즘의 성능에 대한 upper bound를 제공하기 때문에 아무리 좋은 알고리즘을 만들어도 이거보다 좋을 수 없습니다.
•
내가 만든 게 optimal algorithm과 비슷한 page fault를 보인다면 그 이상으로 더 좋게 만들 수 없다는 것
•
Belady’s optimal algorithm, MIN, OPT 등으로 불림
FIFO(First In First Out) Algorithm
실제로 사용할 수 있는 알고리즘으로 Optimal Algorithm과 다르게 미래를 가정하지 않습니다. 미래를 모르지만 미래를 잘 예측해야 합니다.
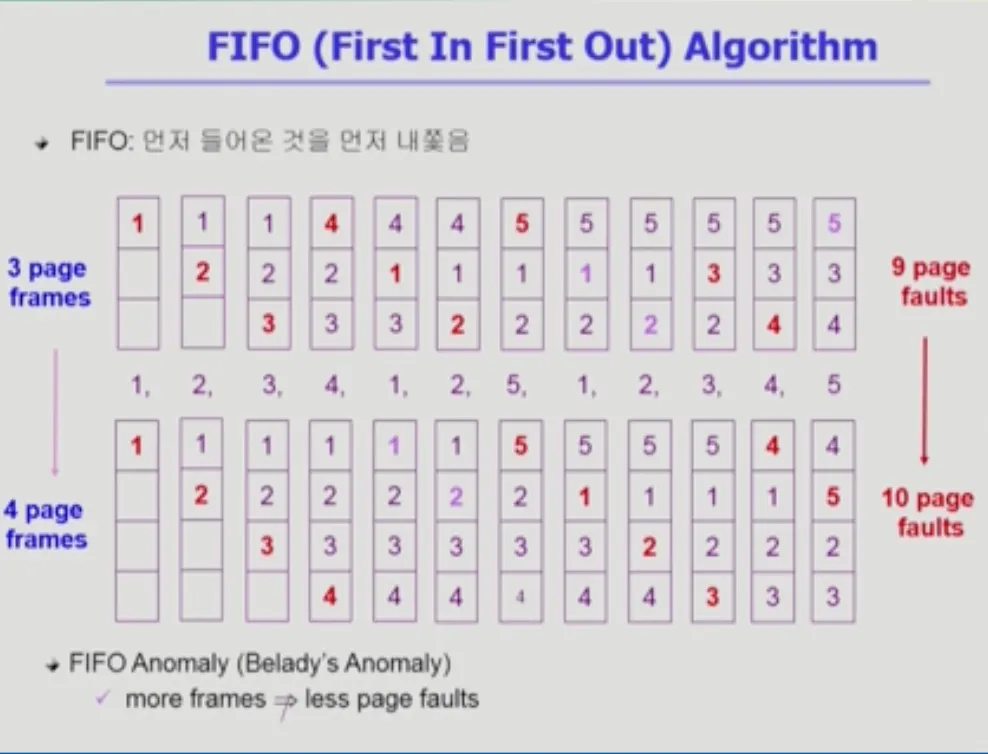 미래를 모를 때 참고할만한 중요한 단서 → “과거를 보자.”
미래를 모를 때 참고할만한 중요한 단서 → “과거를 보자.”•
이 알고리즘은 메모리에 먼저 들어온(First In) 페이지를 먼저 쫓아내는(First Out) 방식입니다.
•
특이한 성질
◦
메모리 크기를 늘려주면 성능이 더 나빠지는, 즉 page fault가 늘어나는 현상이 있습니다.
◦
메모리 프레임을 늘렸는데 성능이 더 나빠지는 현상으로 FIFO Anomaly 라고 불립니다.
LRU(Least Recently Used) Algorithm
메모리 관리 부분에서 가장 많이 사용되는 알고리즘
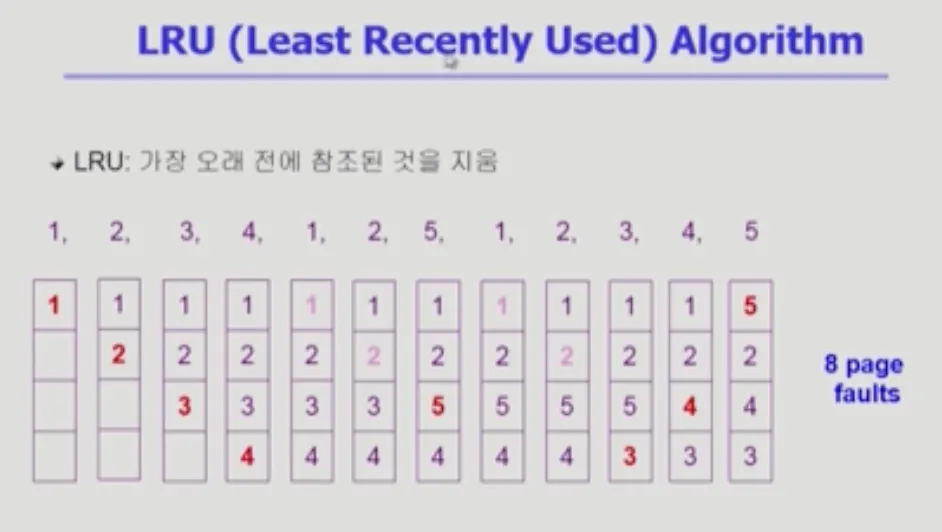
•
가장 오래 전에 사용된 페이지를 쫓아내는 알고리즘
◦
먼저 들어왔지만 들어온 뒤에 재사용된다면 쫓아내지 않습니다.(최근에 사용되었다면)
◦
최근에 사용된 게 가까운 미래에 사용될 가능성이 높다고 판단
•
비교적 page fault를 줄일 수 있음
LFU(Least Frequently Used) Algorithm
가장 덜 빈번하게 사용된 페이지를 쫓아내는 알고리즘

•
참조 횟수가 적은 페이지를 쫓아냅니다.
•
과거에 참조 횟수가 많았던 페이지는 미래에 다시 참조될 가능성이 높다고 판단해서 쫓아내지 않음.
•
참조 횟수가 가장 적은 페이지가 여러개 있을 수 있는데 이런 경우에는 어떤 걸 쫓아내야 한다고 명시되어 있지 않다.
◦
조금 더 성능을 높이고 싶다면, 참조 횟수가 동률인 페이지 중에서 마지막 참조시점이 더 오래된 페이지를 쫓아내는 게 낫다.
LRU, LFU의 장단점 찾아보기
예제를 통해서 알아봅시다.

LRU | 5번 페이지 보관을 위해 1번 페이지를 삭제한다. |
이유 : 현재 시점부터 마지막 참조 시점까지의 거리가 가깝기 때문에 4, 3, 2번 순서로 살려두고 가장 참조 시점이 오래된 1번을 쫓아낸다. | |
특징 : 마지막 참조 시점만 보기 때문에 그 전에 어떤 기록을 가지고 있는지 보지 않는다는게 약점이다. LRU는 1번이 많이 참조되었다는 걸 고려하지 않는다. | |
LRU 알고리즘은 메모리 안에 있는 페이지들을 참조 시간 순에 따라서 한 줄로 줄을 세운다.
맨 위에 위치한 페이지가 가장 오래된 페이지고, 맨 아래 있는 게 가장 최근에 참조된 페이지이다.
Linked List 형태로 참조 시간 순서를 관리하게 된다. | |
만약 어떤 페이지가 메모리에 들어오거나 메모리 안에서 다시 참조를 하면 그 페이지가 가장 최근에 참조가 된 시점으로 변경이 되고 가장 아랫쪽(가장 최근 참조)으로 들어간다. | |
Replacement는 가장 위에 있는 페이지를 쫓아내면 된다. 리스트 형태로 구현되기 때문에 시간 복잡도가 O(1)가 걸린다.
쫓아내기 위해서 비교할 필요가 없기 때문에 시간 복잡도가 O(1)이다. | |
타임 스탬프를 찍고 비교를 해야한다면 n만큼의 시간이 걸릴 것이다. 이는 비효율적이다.
Why? 바로 결정해야 하는데 백 만개 페이지의 참조 시간 순서를 알아내는 건 너무 비효율적 | |
LFU | 5번 페이지 보관을 위해 4번 페이지를 삭제한다. |
이유 : 현재 시점부터 참조 횟수가 많은 기준 1, 2, 3번 순서로 살려두고 가장 참조가 적은 4번을 쫒아낸다. | |
특징 : 비록 4번이 참조횟수가 1번이지만 이제 막 참조가 시작되는 그런 상황인데, 쫓아낸다면 문제가 될 수 있다. | |
참조횟수가 적은 페이지가 윗 쪽, 참조 횟수가 많은 페이지가 아랫쪽으로 줄이 세워진다. 참조 횟수가 적은 페이지를 쫓아내면 된다. 하지만 불가능하다. | |
Why?
어떤 페이지가 참조됐을 때 LRU의 경우에는 현재 참조한 페이지가 가장 가치가 높다. 시간 순서로 따지는 것이 아니기 때문이다. 하지만 LFU는 참조 됐다는 게 1이 늘어났다는 의미이기 때문에 가장 참조 횟수가 많은 페이지가 아니다. 비교를 해서 어디까지 내려갈 수 있는지 확인을 해야 한다. | |
최악의 경우 : 모든 페이지의 참조 횟수가 동일한 경우
하나 하나 비교를 해서 어디까지 자리를 바꿀 수 있는지 확인하고 이를 반복한다. | |
O(n)의 시간 복잡도가 걸리기 때문에 한 줄로 세우지 않고 heap를 사용한다.
→ O(log n)의 구현
이진 트리 형태로 참조 시간 순서를 관리하게 된다. | |
이진 트리 형태로 맨 위에 있을수록 참조 횟수가 적은 페이지고, 참조 횟수가 늘면 직계 자식 2개하고만 비교를 한 뒤에 자리 바꾸기가 가능하다면 자식 노드와 자리를 바꾼다. 더 내려갈 수 있는지는 자식과 또 비교를 해서 자리 바꿈을 하면서 내려간다. | |
해당하는 경로만 따라 내려가면서 어디까지 내려갈 수 있는지 찾아보기 때문에 높이가 n이라고 한다면 이 걸린다.
비교 횟수가 많아봐야 이 된다. | |
맨 위에 있는(루트) 노드부터 쫓아내고나서 heap를 재구성한다. | |
알고리즘이 적어도 O(log n)정도는 되어야지 replacement algorithm으로 사용 가능하다. |