인프런 - 모든 개발자를 위한 HTTP 웹 기본 지식에서 김영한 님이 강의해주는 내용을 바탕으로 정리를 진행했습니다. 강의를 직접 듣고 싶으신 분들은 하단 북마크를 눌러주세요.
*제 포스팅에 나오는 모든 이미지는 김영한 님께서 만든 강의 자료에서 가져왔습니다.

요약 정리
전체 내용을 보기 쉽게 요약 정리해둔 부분입니다. 자세히 알기 원하는 문장을 선택하시면 관련 섹션으로 이동합니다.
들어가며
이번 챕터에서는 먼저 URI, URL, URN이 어떤 의미를 가지는지 보고, 웹 브라우저에서 요청이 흐름이 어떤 식으로 진행되는지 이전에 본 네트워크 흐름과 섞어서 설명을 해보려고 합니다.
URI(Uniform Resource Identifier)
URI는 리소스를 식별하는 통합된 방법이라고 해석할 수 있습니다. 뭔가 확 와닿진 않죠?
일단, 우리가 URI에 대해서 알기 전에 URI, URL, URN 이런 단어들에 대한 구분이 필요합니다.
rfc 표준 스펙을 살펴보면, URI에 대한 설명이 나와있습니다.
URI는 로케이터(Locator), 이름(name) 또는 둘 다 추가로 분류될 수 있다.
- https://www.ietf.org/rfc/rfc3986.txt - 1.1.3. URI, URL, and URN
URI는 URL과 URN 위에 있는 큰 개념입니다. URI가 Resource Identifier, 즉 자원 자체를 식별하는 방법을 나타내는데 그 방법에는 2가지가 있습니다. 그게 바로 URL과 URN 입니다.
1.
URL(Resource Locator)
- 리소스의 위치가 해당 위치에 있다는걸 나타냄.
2.
URN(Resource Name)
- Duna(네임 예시)가 여기 있다고 해서 찾아가면 Duna가 거기 있음.
- URN은 Duna(네임) 그 자체를 나타내는 것임.
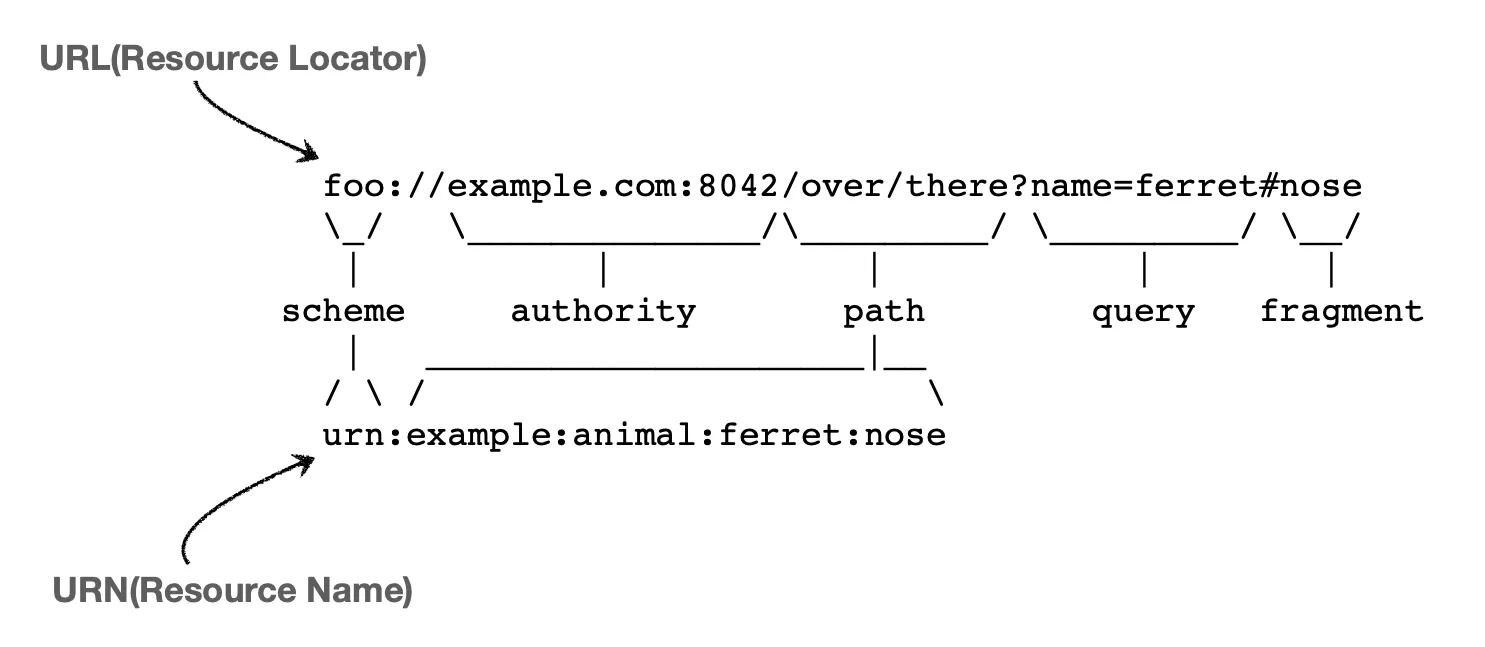
이해를 조금 더 돕기 위해서 URL, URN의 모습을 보여드리겠습니다.
https://www.ietf.org/rfc/rfc3986.txt
아마 상단에 위치한 URL은 익숙한 모습일겁니다. 우리가 웹 브라우저에서 많이 사용하는 방식이니깐요. 하지만 URN은 대부분 낯설겁니다.
URN은 이름을 부여하는 방법입니다. 하지만 이름을 부여하면 거의 찾을 수 없습니다. 중간 어딘가에 이름을 넣으면 리소스 결과가 나올 수 있게 매핑이 되어 있어야 하는데 그게 어렵기 때문에 거의 URL만 사용합니다. URN은 그냥 이런게 있구나 정도로만 봐주시면 될 것 같습니다.
URI
URI의 단어 뜻을 더 자세하게 살펴보자면:
•
Uniform : 리소스 식별하는 통일된 방식
•
Resource : 자원, URI로 식별할 수 있는 모든 것(제한 없음)
HTML 이런 것만이 자원이 아닙니다. 실시간 교통 정보도 자원이 될 수 있고, 우리가 구분할 수 있는 모든 리소스들은 자원이라고 이해하면 됩니다.
•
Identifier : 다른 항목과 구분하는데 필요한 정보
일상 생활에 적용해서 생각해본다면 주민번호 같은 거라고 생각하시면 됩니다.
URI는 위에서 말했듯이, URL과 URN으로 나뉩니다.
URL, URN
•
URL
Locator, 즉 리소스가 있는 위치를 지정합니다.
웹 브라우저에 URL을 친다면 리소스가 여기에 있을거야 하고 검색하는 겁니다.
•
URN
Name, 즉 리소스에 이름을 부여합니다.
리소스가 있는 위치는 변할 수 있지만, 이름은 변하지 않습니다.
예를 들어서 어떤 책의 URN이 urn:isbn:8960777331 이라고 하겠습니다. 해당 URN를 검색한다면 실제 결과가 나오진 않습니다. 검색 엔진에서는 뭔가가 나올 수도 있겠지만 책이 딱 하고 나오지 않습니다.
URN 방법은 옛날에 사용을 해보려고 시도해봤지만 결과적으로 잘 안됐고 보편화에 실패했습니다.
∴ URN은 사용이 거의 안되기 때문에 URL만 알면 됩니다. 앞으로 URI와 URL를 같은 의미로 사용하겠습니다.
그렇다면 URI, URL, URN이 뭔지 알았으니, 우리가 자주 사용하는 URL를 한 번 분석해보겠습니다.
URL 분석
이런 URL를 많이 보셨을겁니다. 아마 웹 브라우저에서 해당 URL를 쳤을 때 그에 대한 리소스 결과를 돌려주는 걸 이미 경험하셨을겁니다.

그렇다면, 각 단어들이 어떤 의미를 가지는지 문법적으로 봐볼까요?

1.
scheme
scheme에는 주로 프로토콜을 씁니다. 프로토콜은 어떤 방식으로 리소스에 접근할 것인가 하는 클라이언트와 서버 간의 약속과 규칙입니다. 이전에 TCP/IP에 대한 네트워크 방식을 보면서 애플리케이션 프로토콜을 잠깐 보셨을 겁니다. 혹시 까먹으셨다면 잠깐 들렸다 오세요. [Network] URI와 웹 브라우저 요청 흐름
[Network] URI와 웹 브라우저 요청 흐름 애플리케이션 프로토콜에는 http, https, ftp 등이 있습니다. 자주 사용하는 http, https는 자주 사용하는 포트가 등록되어 있어서 이후에 PORT 부분을 생략해도 알아서 포트 번호를 넣어줍니다.
2.
userinfo@
URL에서 사용자 정보를 포함해서 인증해야 할 때 사용하는 부분입니다. 하지만 거의 사용하지 않습니다.
3.
host
보통 도메인 명이나 IP 주소를 직접 입력하는 부분입니다.
4.
port
접속 포트 번호를 나타냅니다. http, https 같은 프로토콜은 포트 번호를 생략합니다.
따라서 일반적인 웹 브라우저에서는 포트 번호를 대체로 생략합니다. 하지만 특정 서버에 따로 접근을 해야 한다면 입력해줘야 하는 부분입니다.
5.
path
해당 리소스가 있는 경로를 나타냅니다. path는 보통 계층적 구조로 설계합니다.
계층적 구조를 조금 설명드리자면, /member 라는 경로가 있다면 우리는 해당 경로가 멤버 정보를 가져오는 경로라고 생각할겁니다. 그리고 /member/100 라는 경로가 있다면 아까 그 경로에서 100번째 멤버의 정보를 가지고 있는 경로라고 생각할겁니다. 이렇게 path는 보통 계층적으로 설계가 됩니다.
6.
query
key-value 형태로 데이터가 들어있는 부분입니다. 일단 ? 로 시작하고, & 기호를 사용해서 추가되는 Parameter들을 붙입니다.
위의 예시에서 쿼리 값을 해석해보자면, 우리가 q 라는 파라미터에 hello라는 값을 넣고 추가적으로 hl 이라는 파라미터에 ko라는 값을 넣어주었습니다. 조금 더 해석해보자면, q는 검색할 값을 나타내는 부분이기 때문에 hello를 검색한다는 걸 알 수 있고, hl는 해당 언어 정보로 데이터를 내려달라는 걸 나타내는 부분이기 때문에 ko, 즉 한국어로 데이터가 내려온다는 걸 알 수 있습니다.
query는 query parameter, query string으로도 불립니다.
query parameter로 불리는 이유는 웹 서버에 제공하는 파라미터 정보이기 때문입니다. query string으로 불리는 이유는 query로 값을 보내면 어떤 타입이더라도 문자로 넘어가기 때문에 그렇습니다.
7.
fragment
잘 사용하지 않는 부분입니다. 이 부분은 HTML 내부 북마크 등에 사용되는 부분입니다. 따라서 서버로 전송되는 정보는 아닙니다.
이제 URL 분석까지 해봤으니, URL를 호출했을 때 실제 웹 브라우저에서 어떻게 패킷을 만들어서 어떻게 인터넷 망에서 흘러가고 또 서버에 패킷이 도착해서 어떤 식으로 응답을 주는지 전체적인 흐름을 한 번 살펴보겠습니다.
웹 브라우저의 요청 흐름
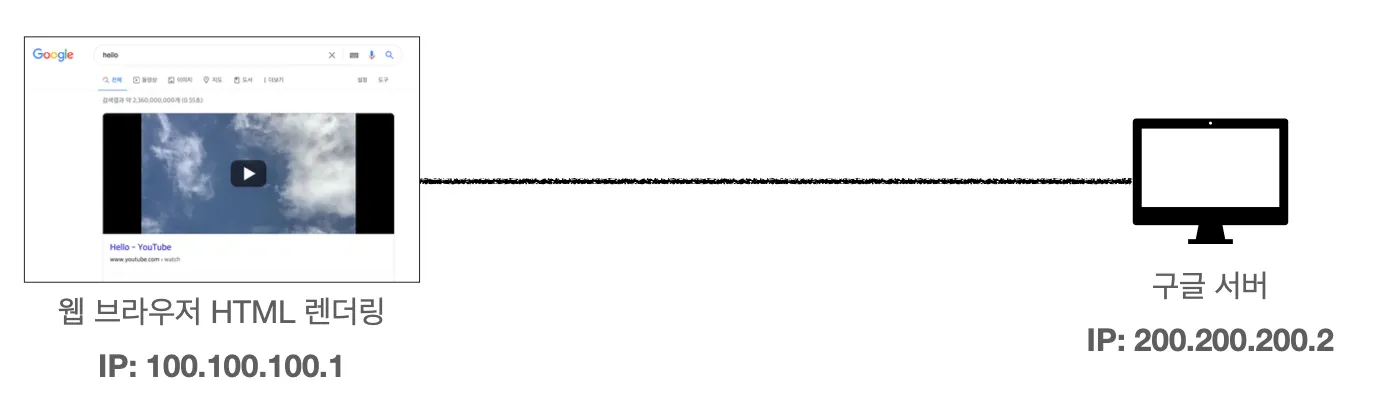
현재 우리가 하단 URL를 웹 브라우저에서 호출한다고 해봅시다.

1.
먼저 DNS 서버를 조회해서 www.google.com이 나타내는 IP 주소를 찾습니다. DNS 서버를 조회했더니 IP 주소가 200.200.200.2가 나오는군요. 그리고 scheme에 적힌 프로토콜이 https이기 때문에 포트 번호는 443이 될겁니다. https의 포트 번호이기 때문에 이는 생략 가능합니다.

2.
IP 주소와 포트 정보를 찾아냈다면, 이제 패킷에 담아서 보낼 HTTP 요청 메시지를 생성해야 합니다. HTTP 요청 메시지의 모습은 이렇습니다.

HTTP 요청 메시지
대충 요청 메시지를 해석해보자면, 처음에 나오는 GET은 요청을 보내는 방식을 나타내는 느낌이네요. 뒤에 path는 이전에 URL를 분석하면서 봤기 때문에 넘어가겠습니다. 뒤에 HTTP/1.1은 HTTP 버전 정보입니다. 그리고 HOST 정보를 가지고 있네요. 해당 정보들말고도 추가적으로 들어가는 정보들이 있긴 하지만 그건 이후에 HTTP에 대한 공부를 하면서 알아가 봅시다.
이제 패킷에 담을 IP 주소, 포트 번호, HTTP 요청 메시지 까지 생성을 했으니 어떤 식으로 패킷이 흘러가는지를 봅시다.
3.
익숙한 그림일겁니다. 이전에 인터넷 네트워크에서 봤었던 네트워크 흐름 그림([Network] 인터넷 네트워크 )입니다. 이번에는 해당 그림을 통해서 HTTP 메시지가 전송되는 모습을 볼겁니다.
[Network] 인터넷 네트워크 )입니다. 이번에는 해당 그림을 통해서 HTTP 메시지가 전송되는 모습을 볼겁니다.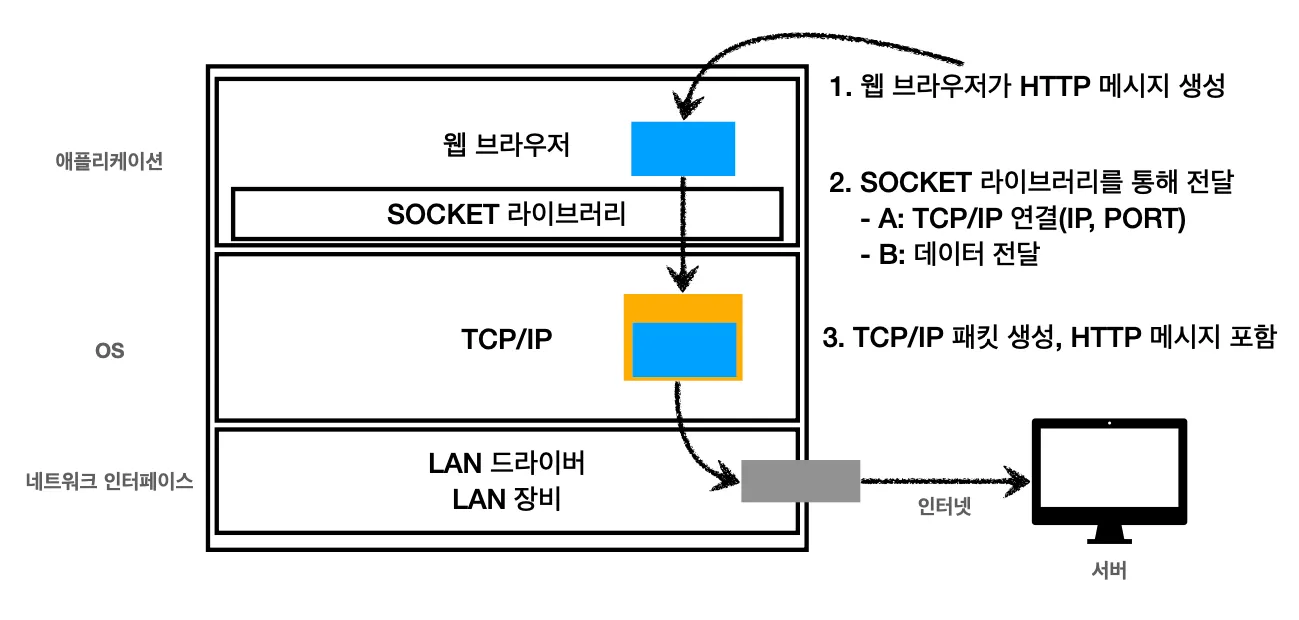
⓵ 먼저 애플리케이션 계층에서 웹 브라우저가 HTTP 메시지를 생성합니다.
⓶ Socket 라이브러리를 통해서 OS(TCP/IP 계층)에 전달합니다.
a.
Socket를 통해서 TCP/IP로 IP/PORT 정보를 사용해서 SNK, ACK 메시지를 보냅니다. 메시지를 받은 google.com 서버가 현재 클라이언트와 통신해서 연결을 합니다. 만약, 서버에서 응답이 없다면 연결이 되지 않고 HTTP 메시지도 보내지지 않을겁니다.
b.
서버와 연결이 되었다면 데이터 전송을 위해서 HTTP 메시지 데이터를 전달합니다.
⓷ TCP/IP 계층에서 IP/PORT 정보를 사용해서 패킷을 생성합니다.

패킷의 모습
⓸ 네트워크 인터페이스에 있는 LAN 카드를 통해 패킷이 인터넷 망으로 들어갑니다.
위의 그림의 전체적인 흐름을 살펴봤습니다. 이제 인터넷 망으로 흘러들어간 패킷이 어떻게 되는지 한 번 볼까요?
4.
복잡한 인터넷 망으로 던져진 패킷은 수 많은 중간 노드(서버)를 거쳐서 목적지 IP로 전달됩니다.

5.
패킷이 도착하면 구글 서버는 먼저 TCP/IP 패킷을 다 까서 버립니다. 그리고 그 안에 있는 HTTP 메시지를 끄집어낸 다음에 메시지를 해석합니다.

HTTP 요청 메시지
구글 서버 : “아, 검색하고자 하는게 hello고, 한글로 검색 정보를 내려주면 되네?”구글 서버는 검색 엔진을 통해서 hello와 관련된 한국어 결과 데이터를 찾을 겁니다. 그러고나서 HTTP 응답 메시지를 생성합니다.
6.
구글 서버에서는 HTTP 응답 메시지를 생성합니다.

HTTP 응답 메시지
요청 메시지처럼 해석을 조금 해보자면, HTTP/1.1은 위에서 봤던 거처럼 HTTP 버전 정보를 나타내는 거 같고, 200 OK는 정상 응답을 하는 느낌이네요. Content-Type 이라는 부분은 응답 데이터가 어떤 형식을 가졌는지 나타내는 부분인 거 같고, Content-Length는 해당 데이터의 길이(사이즈)가 이정도 된다를 나타내는 거 같네요.
서버에서도 웹 브라우저와 동일하게 응답 패킷을 만들고 TCP/IP를 씌웁니다. 그리고 웹 브라우저로 전달합니다.
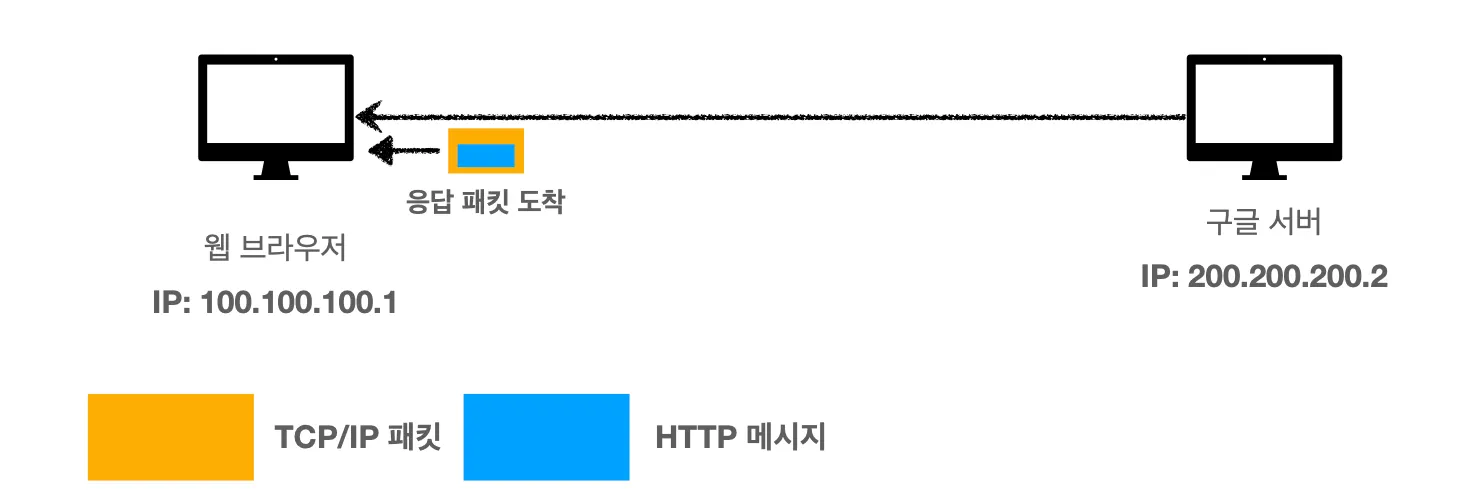
7.
응답 패킷이 웹 브라우저로 도착했습니다. 웹 브라우저도 구글 서버와 동일하게 TCP/IP 패킷을 까고 내부에 있는 HTTP 메시지를 봅니다. 아까 서버에서 보낸 HTTP 응답 메시지를 보면 HTML 데이터가 들어있을 겁니다.
8.
웹 브라우저는 해당 HTML 데이터를 렌더링합니다. 그 결과로 우리는 HTML로 만들어진 화면을 볼 수 있게 됩니다.