
인프런 - 모든 개발자를 위한 HTTP 웹 기본 지식에서 김영한 님이 강의해주는 내용을 바탕으로 정리를 진행했습니다. 강의를 직접 듣고 싶으신 분들은 하단 북마크를 눌러주세요.
*제 포스팅에 나오는 모든 이미지는 김영한 님께서 만든 강의 자료에서 가져왔습니다.

목차 보기
요약 정리
전체 내용을 보기 쉽게 요약 정리해둔 부분입니다. 자세히 알기 원하는 문장을 선택하시면 관련 섹션으로 이동합니다.
들어가며
이번 챕터에서는 HTTP에 관한 기본 지식을 알아보려고 합니다. HTTP가 뭐까지 가능하고 어떤 모습을 가졌는지 알아봅시다.
HTTP(HyperText Transfer Protocol)
HTTP는 하이퍼 텍스트 문서를 전송하기 위한 프로토콜 입니다.
HTML, 문서간의 링크를 통해서 연결할 수 있는 Hyper Text 문서를 통해서 연결할 수 있는 HTML를 전송하는 프로토콜로 처음 시작했습니다.
지금은 HTML만 전송 가능하던 예전과는 다르게 모든 것을 HTTP 메시지에 담아서 전송 가능해졌습니다.
HTML, Text, Image, 음성, 영상, 파일, JSON, XML … 등등 거의 모든 형태의 데이터가 전송 가능해졌습니다. 심지어, 서버 간의 데이터를 주고 받을 때에서도 이 HTTP를 사용합니다.
서버 간의 데이터 전송에 HTTP가?
HTTP의 역사
HTTP에는 다양한 버전이 존재하지만 우리에게 중요한 버전은 1997년에 나온 HTTP/1.1 입니다.
해당 버전이 왜 제일 중요한가요?
HTTP/1.1에 현재 우리가 사용하고 있는 대부분의 기능들이 다 들어있습니다. 따라서, 현재도 가장 많이 사용하고 있어요. 이후에 HTTP/2, HTTP/3이 나오긴 했지만 두 버전은 성능 개선에 초점을 두기 때문에 HTTP/1.1 에서 성능이 개선된 정도입니다.
HTTP/1.1의 RFC는 총 3번 개정되었는데, 3번째 개정인 RFC7230~7235는 2014년에 개정되었기 때문에 대부분의 책이나 문서가 2번째 개정인 RFC2616에 초점을 맞춰서 설명되어 있는 경우가 많습니다. 따라서 신규 스펙에 대해서 공부하고 싶다면 7230부터 보는걸 추천합니다.
이번엔 다양한 버전이 있다는 점에 초점을 맞춰서 각 버전의 기반 프로토콜을 살펴볼게요.
•
TCP 위에서 동작 : HTTP/1.1, HTTP/2
•
UDP 위에서 동작 : HTTP/3
HTTP/3은 다른 버전들과는 다르게 UDP 위에서 동작합니다. 이전 챕터([Network] 인터넷 네트워크)에서도 얘기했듯 TCP는 안정적이고 신뢰할 수 있는 프로토콜입니다. 안정적인 TCP를 사용하지 않고 HTTP/3에서는 UDP를 선택한 이유는 뭘까요?
[Network] 인터넷 네트워크)에서도 얘기했듯 TCP는 안정적이고 신뢰할 수 있는 프로토콜입니다. 안정적인 TCP를 사용하지 않고 HTTP/3에서는 UDP를 선택한 이유는 뭘까요?안정적인 TCP는 안정적인 통신을 위해서 3 Way Handshake를 진행하고, 많은 데이터를 가지고 있습니다. 안정적이고 신뢰할 수 있는 통신은 가능해졌지만 그만큼 속도도 느려졌습니다. 따라서 HTTP/3는 UDP 프로토콜 위에서 동작하면서 성능을 최적화하도록 설계되었습니다.
구글 사이트에 hello를 검색하고 브라우저 개발자 툴을 통해서 Network 통신이 어떻게 되고 있는지 살펴봅시다. 3번째 열에 있는 Protocol 영역을 보면 다양한 HTTP 프로토콜 버전을 사용하고 있는걸 볼 수 있습니다. h2, h3 프로토콜을 사용하고 있네요.
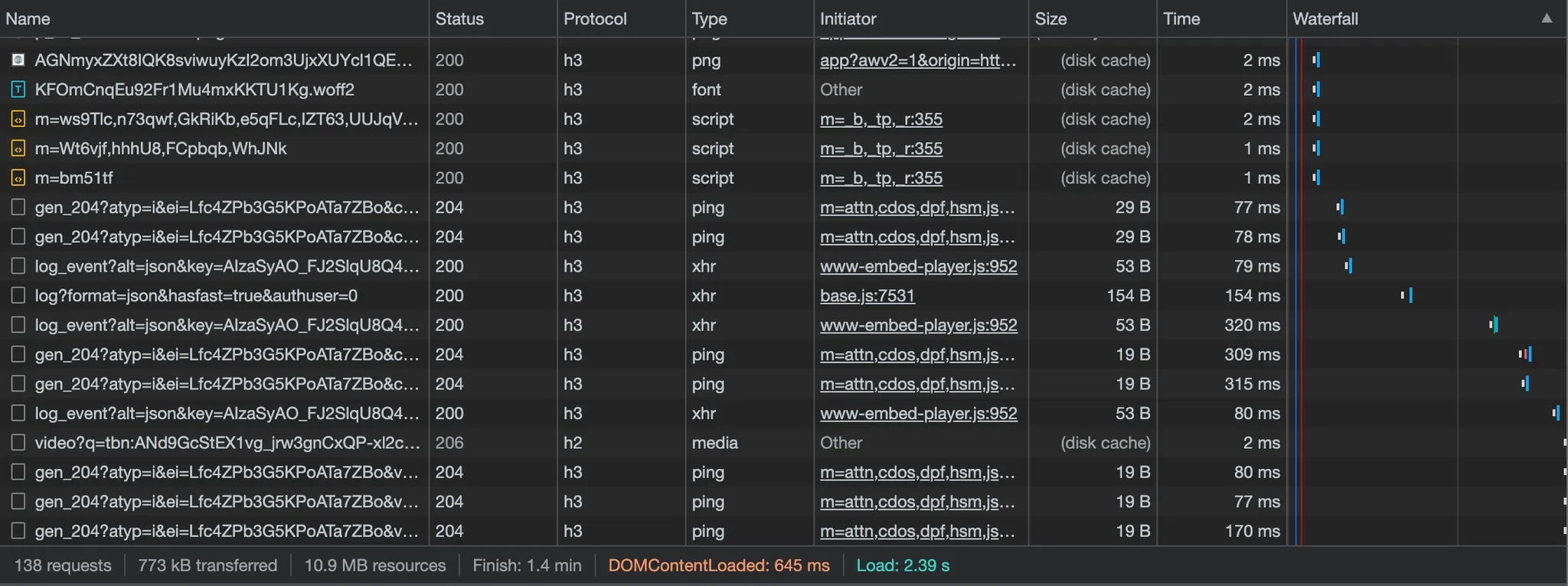
HTTP가 다양한 버전을 가졌고 HTTP/1.1이 제일 중요하다는 걸 아셨다면, 이번엔 HTTP의 특징을 알아봅시다.
HTTP의 특징
HTTP는 이러한 특징들을 가지고 있습니다.
⓵ 클라이언트, 서버 구조로 기본적으로 동작
⓶ 무상태 프로토콜(스테이스리스) 지향
⓷ 비연결성
⓸ HTTP 메시지를 통해서 통신
⓹ 단순하고 확장 가능 → 이 부분은 위의 내용을 듣다보면 이해가 될 것!
각 특징들이 가지고 있는 내용들이 너무 중요하기 때문에, 앞으로 하나씩 자세하게 알아볼겁니다.
클라이언트, 서버 구조
HTTP는 클라이언트, 서버(Request, Response) 구조로 기본적으로 동작합니다.
클라이언트, 서버 구조로 동작한다는 말이 뭔가요?
클라이언트는 HTTP 요청 메시지를 서버로 보냅니다. 그리고 응답이 올 때까지 무작정 기다립니다. 서버에서는 요청에 대한 결과를 만들어서 클라이언트에 HTTP 응답 메시지를 보냅니다. 응답 메시지를 받은 클라이언트는 응답 결과를 열어서 동작하게 됩니다.
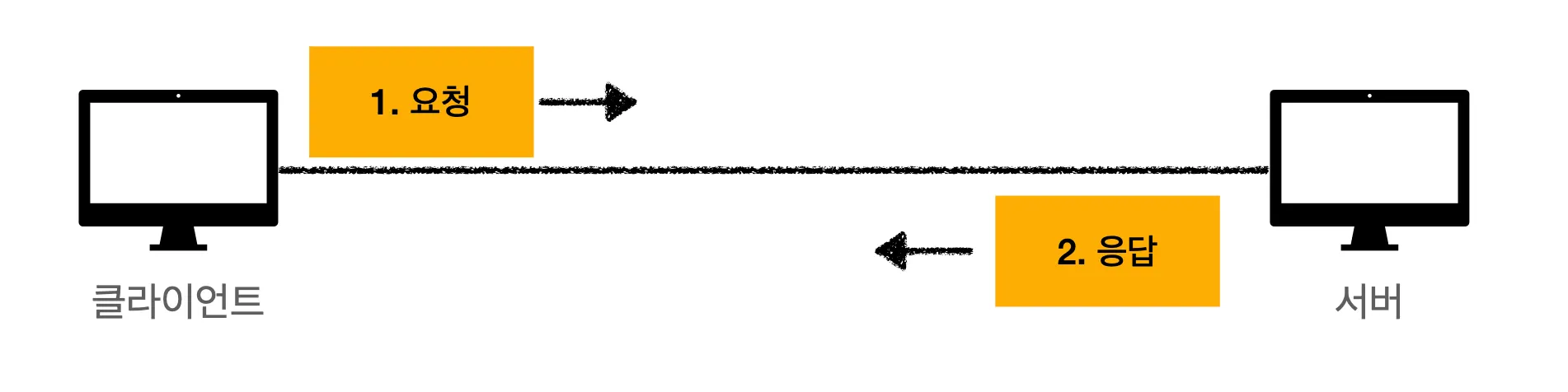
하지만, 이렇게 동작한다는건 되게 표면적인 얘기입니다.
우리가 중요하게 봐야하는건 이렇게 클라이언트와 서버로 분리를 한다는겁니다.
왜 그게 중요한가요?
오래전엔 클라이언트와 서버라는 두 개념이 분리가 되어있지 않았습니다. 그래서 한 뭉탱이로 존재했습니다.
이후에 개념적으로 클라이언트와 서버를 분리하게 되었고, 분리를 하면서 서버엔 비즈니스 로직과 데이터 같은 부분들을 밀어넣게 됩니다. 클라이언트는 UI 그리고 사용성에 집중을 하게 됩니다.
두 개념으로 분리를 하면서 클라이언트, 서버가 각각 독립적으로 진화 가능하게 되었습니다.
클라이언트는 복잡한 비즈니스 로직 같은 것이 없기 때문에 복잡한 데이터를 다룰 필요도 없고 그냥 단순하게 UI를 어떻게 그릴지, UX를 어떻게 개선할지에 집중하면 됩니다. 서버도 어떻게 대용량 트래픽을 관리할지, 비즈니스 로직을 어떻게 구현할지에 대한 부분만 고민해도 됩니다. 클라이언트는 대용량 트래픽을 어떻게 관리할지에 대한 부분을 전혀 몰라도 됩니다. 따라서, 양쪽이 독립적으로 진화할 수 있게 된거죠.
무상태 프로토콜 지향(Stateless)
HTTP는 무상태 프로토콜(Stateless)을 지향합니다. 무상태 프로토콜을 지향하기 때문에 서버는 클라이언트의 상태를 보존할 필요가 없습니다. 이게 무슨 소리인가 싶을겁니다. 서버가 클라이언트의 상태를 보존할 필요가 없다고?
이해를 돕기 위해 무상태(Stateless)와 상태를 보존하는 Stateful를 예시를 들어서 차근차근 설명해보겠습니다.
상황 1) Stateful하게 노트북을 사는 경우
고객 : 이 노트북 얼마인가요? 점원 : 100만원 입니다. 고객 : 2개 구매하겠습니다. 점원 : 200만원 입니다. 신용카드, 현금 중에 어떤 걸로 구매하시겠어요? 고객 : 신용카드로 구매하겠습니다. 점원 : 200만원 결제 완료되었습니다.상황 1에서는 점원이 고객의 이전 상태를 알고(보존) 있습니다. 그렇기 때문에 고객에 문장에서 어떤걸 2개 살지, 어떤 것을 신용카드로 구매할 지 얘기하지 않아도 알 수 있죠.
점원이 고객의 이전 상태를 알고(보존) 있습니다. 그렇기 때문에 고객에 문장에서 어떤걸 2개 살지, 어떤 것을 신용카드로 구매할 지 얘기하지 않아도 알 수 있죠.하지만 조금 다른 상황을 제시해보겠습니다.
상황 2) Stateful하게 노트북을 사는 경우에 점원이 바뀜
고객 : 이 노트북 얼마인가요? 점원A : 100만원 입니다. 고객 : 2개 구매하겠습니다. 점원B : 무엇을 2개 구매하시겠어요? 고객 : 신용카드로 구매하겠습니다. 점원C : 무슨 제품을 몇 개 신용카드로 구매하시겠어요?상황 2는 상황 1과 비슷한 상황이지만 매 질문마다 점원이 바뀌었습니다. 이전에는 점원 한 명이 고객의 주문을 받았기 때문에 이전 Context를 이해하고 있었지만, 지금은 아닙니다. 점원A가 점원B에게, 점원B가 점원C에게 고객이 어떤 질문을 했는지 얘기해주지 않으면 다른 점원들은 어떤 상황인지 알 수 없습니다.
Context를 모르기 때문에 고객의 질문을 전혀 이해하지 못합니다.
아무튼, Stateful은 고객의 이전 상태를 보존하고 있기 때문에 상황 1 에서처럼 점원이 고객이 하는 말을 바로 알아듣습니다. 누군가는 위의 상황을 보고 당연한 것이 아니냐고 생각할 수 있습니다. 당연히 고객이 말한 정보를 점원이 계속 기억해야하는게 아니냐구요. 그리고 이게 무상태(Stateless)와 얼마나 큰 차이가 있겠냐고 생각할 수도 있습니다.
그러면 어떤 차이가 있는지 설명하기 위해서 위의 상황 1, 상황 2 예시를 동일하게 사용하겠습니다.
상황 1) Stateless하게 노트북을 사는 경우
고객 : 이 노트북 얼마인가요? 점원 : 100만원 입니다. 고객 : 노트북 2개 구매하겠습니다. 점원 : 노트북 2개는 200만원 입니다. 신용카드, 현금 중에 어떤 걸로 구매하시겠어요? 고객 : 노트북 2개를 신용카드로 구매하겠습니다. 점원 : 200만원 결제 완료되었습니다.상황 1를 보고 “그래서 위랑 무슨 차이가…?” 라고 생각하시는 분들이 있을 거 같습니다. 고객이 Stateful할 때보다 점원에게 주는 정보가 조금 많아졌네요. 아까 전보다 고객이 점원에게 줘야 하는 정보가 많아졌습니다. 하지만 점원이 답하는 말은 동일합니다. 오히려 손해 아닌가? 라는 생각이 들 수도 있습니다. 그렇다면 상황 2를 한 번 볼까요?
상황 2) Stateless하게 노트북을 사는 경우에 점원이 바뀜
고객 : 이 노트북 얼마인가요? 점원A : 100만원 입니다. 고객 : 노트북 2개 구매하겠습니다. 점원B : 노트북 2개는 200만원 입니다. 신용카드, 현금 중에 어떤 걸로 구매하시겠어요? 고객 : 노트북 2개를 신용카드로 구매하겠습니다. 점원C : 200만원 결제 완료되었습니다.Stateful한 상황과는 다르게 고객이 다른 점원들과 대화를 통해서 노트북 2개를 신용카드로 결제하는데 성공했습니다. Stateful한 상황에서는 중간에 점원이 바뀌면 대화가 통하지 않습니다. 서버와 클라이언트라고 한다면 서버에서 장애가 발생하는거죠. 원하는 데이터, 즉 고객이 노트북을, 2개를 산다는 정보가 해당 점원(서버)이 모르고 있기 때문입니다. 만약, 문제가 생기길 원하지 않는다면 고객의 상태 정보를 다른 점원에게 미리 알려줘야 하겠죠. 하지만 이는 쉽지 않습니다.
반대로 Stateless는 고객이 필요한 데이터를 그때 그때 넘겨줍니다. 따라서 중간에 점원이 바뀌어도 아무 문제가 없는거죠.
클라이언트, 서버 아키텍쳐에서 무상태(Stateless)는 엄청난 확장성을 가지고 옵니다. 왜냐하면 무한 증식이 가능하기 때문이죠. 무상태는 상태를 유지하지 않아도 되기 때문에 응답 서버를 쉽게 바뀔 수 있고, 무한한 서버 증설이 가능합니다.
만약, 위의 예시에서 마트 세일 행사로 고객이 갑자기 증가한다고 할 때 Stateful하다면 점원이 고객의 정보를 보존하고 있어야 하기 때문에 모든 점원들이 고객의 정보를 보존하고 있으려면 어려움이 클겁니다. 하지만 매번 고객들이 필요한 모든 정보를 주고 점원들이 각 고객의 정보를 보존하지 않아도 된다면 고객이 증가할 때 점원을 대거 투입할 수 있을겁니다.
이를 클라이언트, 서버로 바꿔서 생각하면 행사가 있어서 사용자가 갑자기 많아질 경우에 서버를 대거 투입시킬 수 있는겁니다.
상태 유지로부터 생길 수 있는 문제를 하나 더 볼게요.
위에서 봤듯 Stateful한 상황에서는 항상 같은 서버가 유지되어야 합니다. 서버가 바뀌게 되면 처음부터 다시 요청과 응답을 진행해야하니깐요.
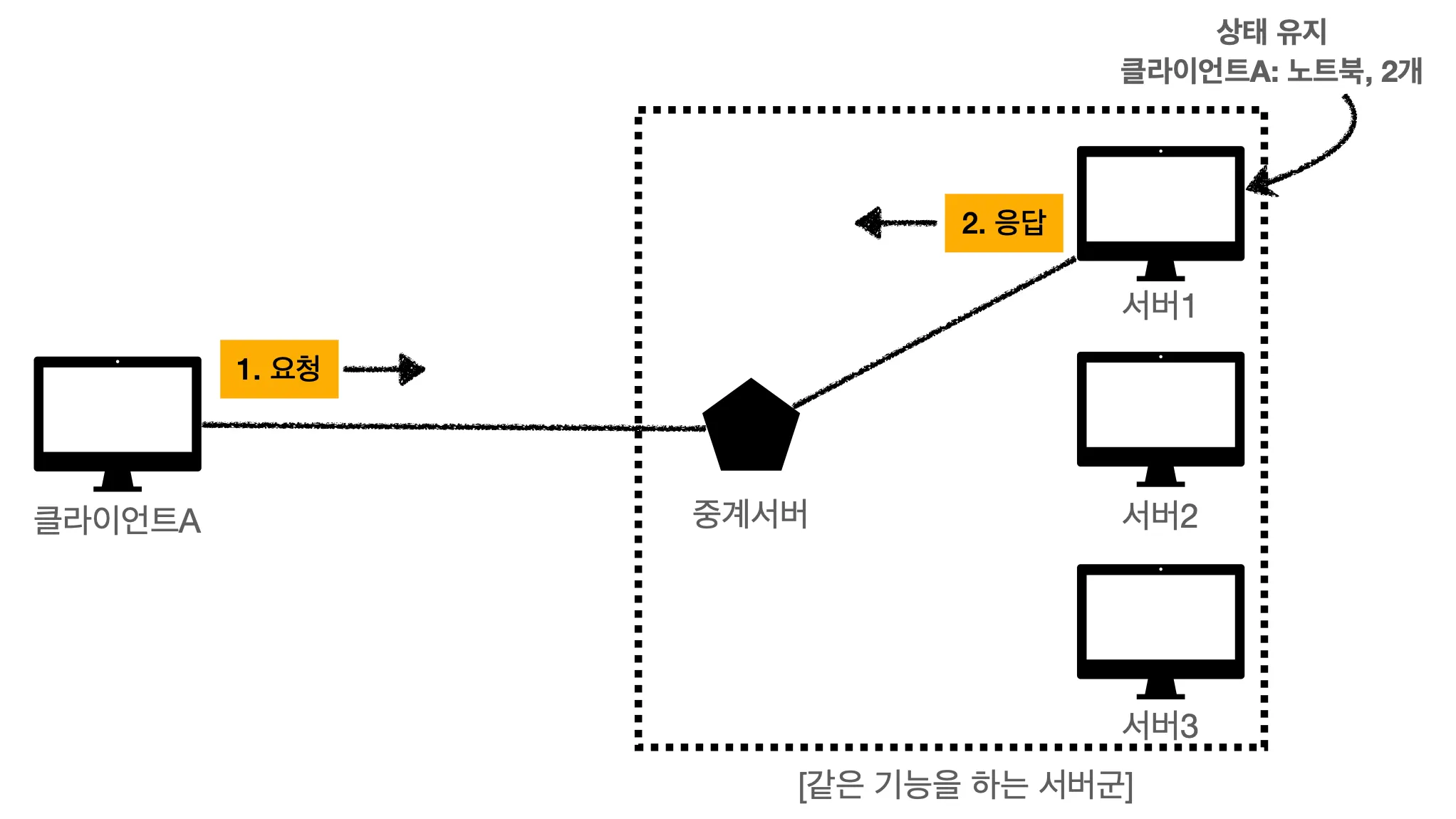
근데 중간에 서버 장애가 발생했다고 가정해봅시다. 서버1이 더이상 클라이언트 A와 통신할 수 없는 상태가 되면 클라이언트는 서버2, 서버3과 통신을 해야할겁니다. 하지만 서버2, 서버3은 클라이언트 1에 대한 정보를 가지고 있지 않기 때문에 클라이언트 A는 처음부터 모든 과정을 다시 해야할겁니다. 대단히 비효율적이죠?
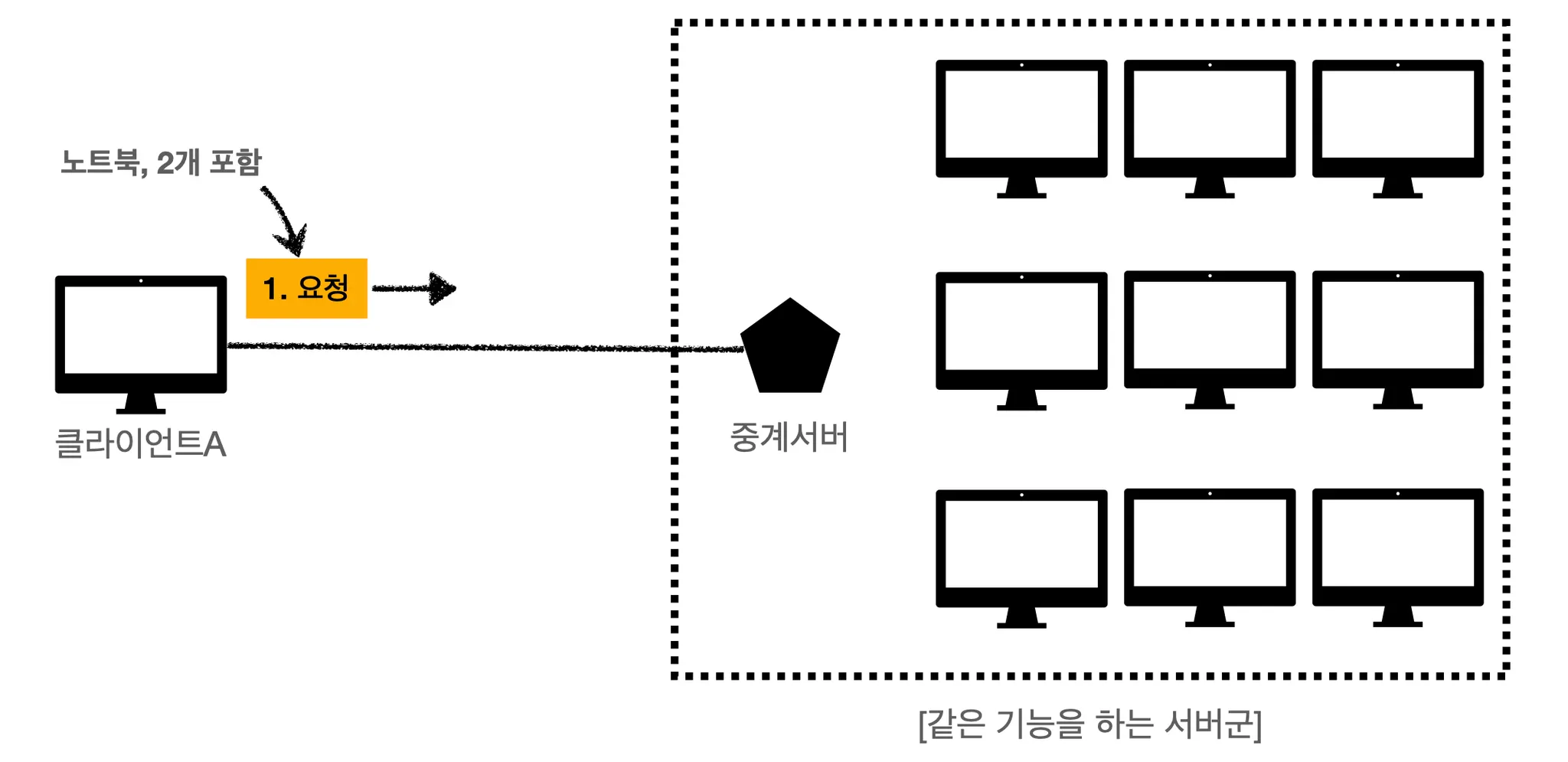
Stateless한 상황이라고 한다면, 아무 서버나 호출하면 됩니다. 애초에 클라이언트가 요청할 때 필요한 모든 데이터를 담아서 보내기 때문입니다.
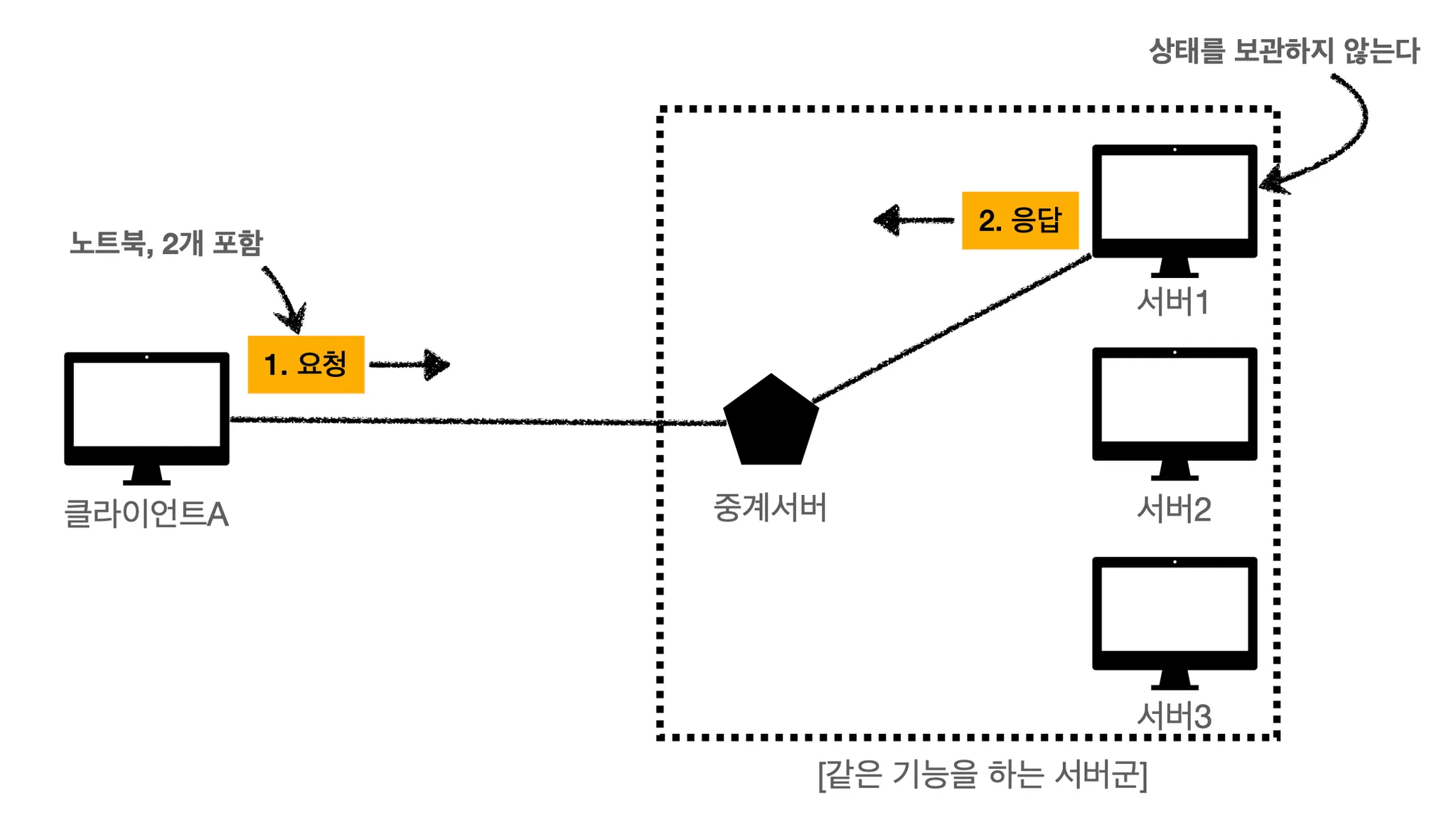
위에서처럼 중간에 서버 장애가 발생한다고 하면 중계 서버가 서버2로 요청을 알아서 던져줄겁니다. 그리고 요청에 필요한 모든 데이터가 다 들어있기 때문에 서버2에서 성공적으로 응답해줄겁니다. 훨씬 좋죠!
무상태는 상태를 보존하지 않기 때문에 옆 서버를 늘리는 스케일 아웃(수평 확장)에 굉장히 유리합니다. 큰 이벤트 시에 백엔드에서는 서버를 수십대, 수백대로 늘리면 되기 때문이죠.
하지만, 무상태 프로토콜도 실무적인 한계가 존재합니다.
첫 번째, 모든 것을 무상태로 설계 할 수 있는 경우도 있고 없는 경우도 있습니다.
만약, 단순한 이벤트 소개 페이지를 만든다고 한다면 상태 유지가 필요없을 겁니다. 따라서 무상태로 페이지를 만들 수 있겠죠.
하지만, 상태를 유지해야하는 경우, 즉 로그인을 진행하는 경우에는 로그인했다는 상태를 유지해야합니다. 브라우저 쿠키, 서버 세션을 사용해서 상태 유지를 하는 기능을 만들 수도 있겠네요. 아무튼 한계가 있지만 상태 유지는 최소한으로 사용해야 합니다. 꼭 필요한 경우가 아니라면 사용해선 안됩니다.
토큰을 기반으로 한다면 stateless하지 않아?
두 번째, 데이터를 너무 많이 보냅니다.
서버는 상태를 유지하지 않습니다. 따라서 클라이언트는 필요한 모든 데이터들을 서버로 보내줘야 합니다. 상태를 유지할 때보다 클라이언트에서 서버로 보내줘야 하는 데이터가 배로 늘어나는 겁니다.
하지만 무상태가 주는 이점을 무시할 수 없기에, 최대한 무상태로 설계해야 하고 어쩔 수 없는 경우에 한해서만 상태 유지를 해야 합니다.
비연결성(Connectionless)
TCP/IP 연결같은 경우에는 한 번 연결을 하고 나면 연결을 유지하고 있습니다.
연결을 유지하는 모델 같은 경우에는 클라이언트 1, 2, 3과 서버가 연결을 하고 나면 그 연결을 계속 유지하고 있습니다. 서버 자원이 소모가 되는거죠.
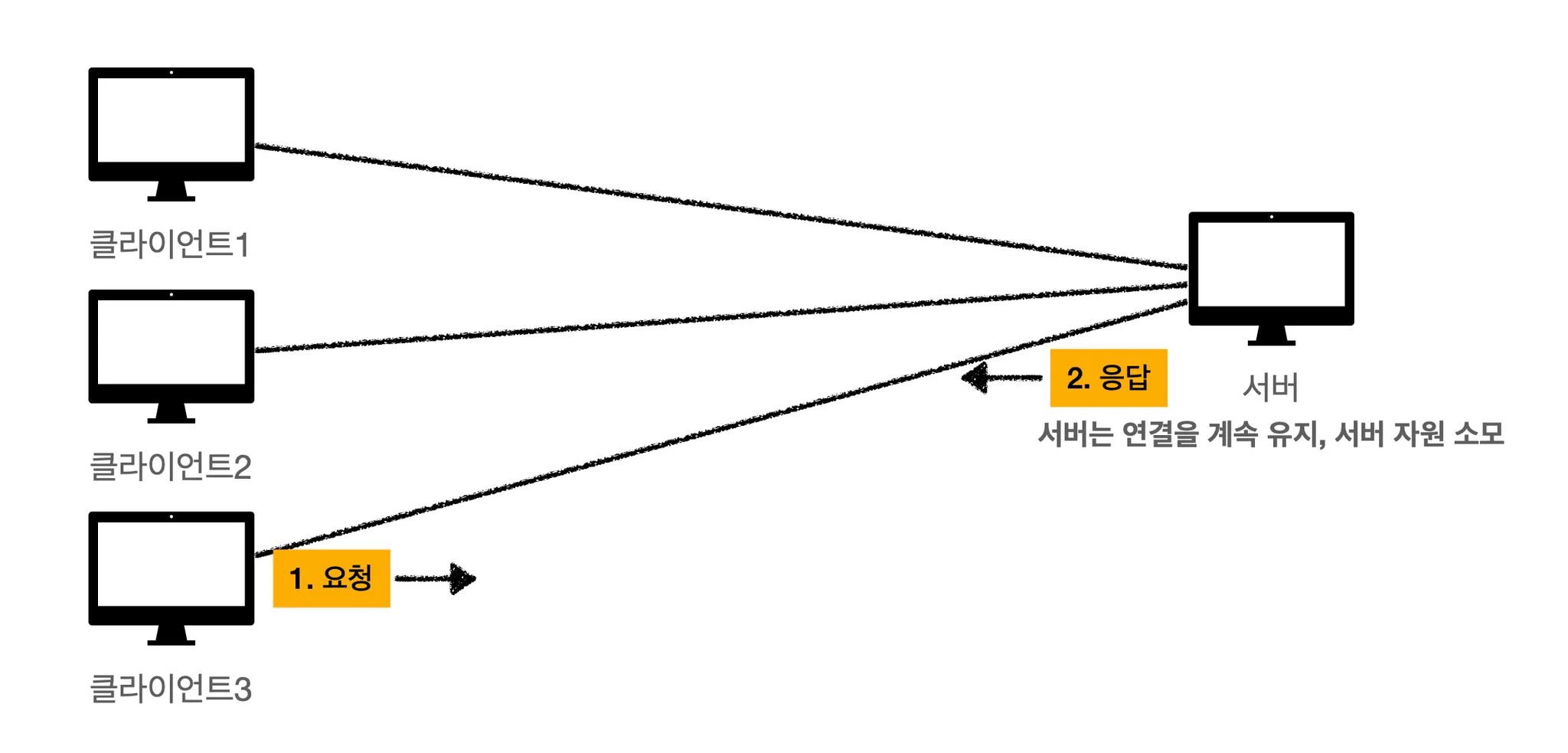
서버 자원이 소모된다는 건 무슨 말이냐?
클라이언트 2, 3이 더이상 요청을 보내지 않고 놀고 있어도 서버는 그 연결을 계속 유지해야 합니다. 예시에서는 3대의 클라이언트가 서버와 연결하지만 수천대라고 한다면 자원 소모가 엄청나겠죠?
반대로, 연결을 유지하지 않는 모델 이라면 서버는 클라이언트와 연결을 하고 나서 요청, 응답 프로세스가 끝나면 연결을 끊을겁니다. 아래 그림처럼요.
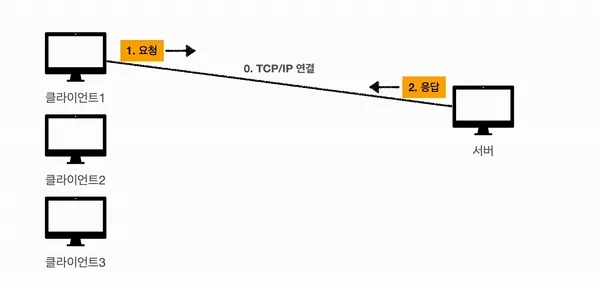
서버는 연결을 유지하지 않아도 되기 때문에 최소한의 자원을 유지하면 됩니다. 연결은 자원이 필요한 데이터가 있어서 요청을 하려고 할 때 다시 하면 됩니다.
HTTP는 기본적으로 연결을 유지하지 않는 모델입니다. 따라서 초 단위 이하의 빠른 속도로 응답이 가능합니다.
수천명이 동시에 버튼을 누르는 것이 아니라서 동시 처리하는 요청은 수십 개 이하가 됩니다. 왜냐하면 사용자들이 연속해서 검색 버튼을 누르지 않거든요. 검색을 하고 한참을 보다가 다시 검색 버튼을 누릅니다. 따라서 동시 처리하는 요청은 적은 수로 발생합니다.
HTML 문서를 주고 받는 환경에서는 연결이 유지되지 않는게 서버의 가용성이 높아지는 길입니다. 연결을 유지하지 않으면 서버 자원을 매우 효율적으로 사용할 수 있기 때문이죠.
이러한 장점을 가진 비 연결성에도 단점이 존재합니다.
⓵ TCP/IP 연결을 새로 맺어야 합니다.
TCP/IP 연결을 할 때는 3 Way Handshake를 진행합니다. 핸드쉐이크를 하면서 SYN, ASK 메시지를 보내는데 이 메시지를 보내는 시간이 추가됩니다. 사용자 입장에서는 연결하는데 드는 시간이 추가로 걸리는 거라서 단점일 수 있습니다.
⓶ HTML 외에 다른 자원을 함께 다운로드 받을 때 비효율적입니다.
우리가 웹 브라우저 요청을 하게되면 응답으로 HTML 데이터만 오는 것이 아닙니다. 자바스크립트, CSS, 추가 이미지 등 수 많은 자원이 함께 다운로드됩니다. 문제는 해당 자원들을 다운로드할 때 발생합니다.
HTTP 초기에는 이런 방식으로 각 리소스를 다운받았습니다. 연결 → 요청 → 리소스 응답 → 종료 다시 연결 → 요청 → 리소스 응답 → 종료 다시 연결 → 요청 → 리소스 응답 → 종료 를 반복합니다.
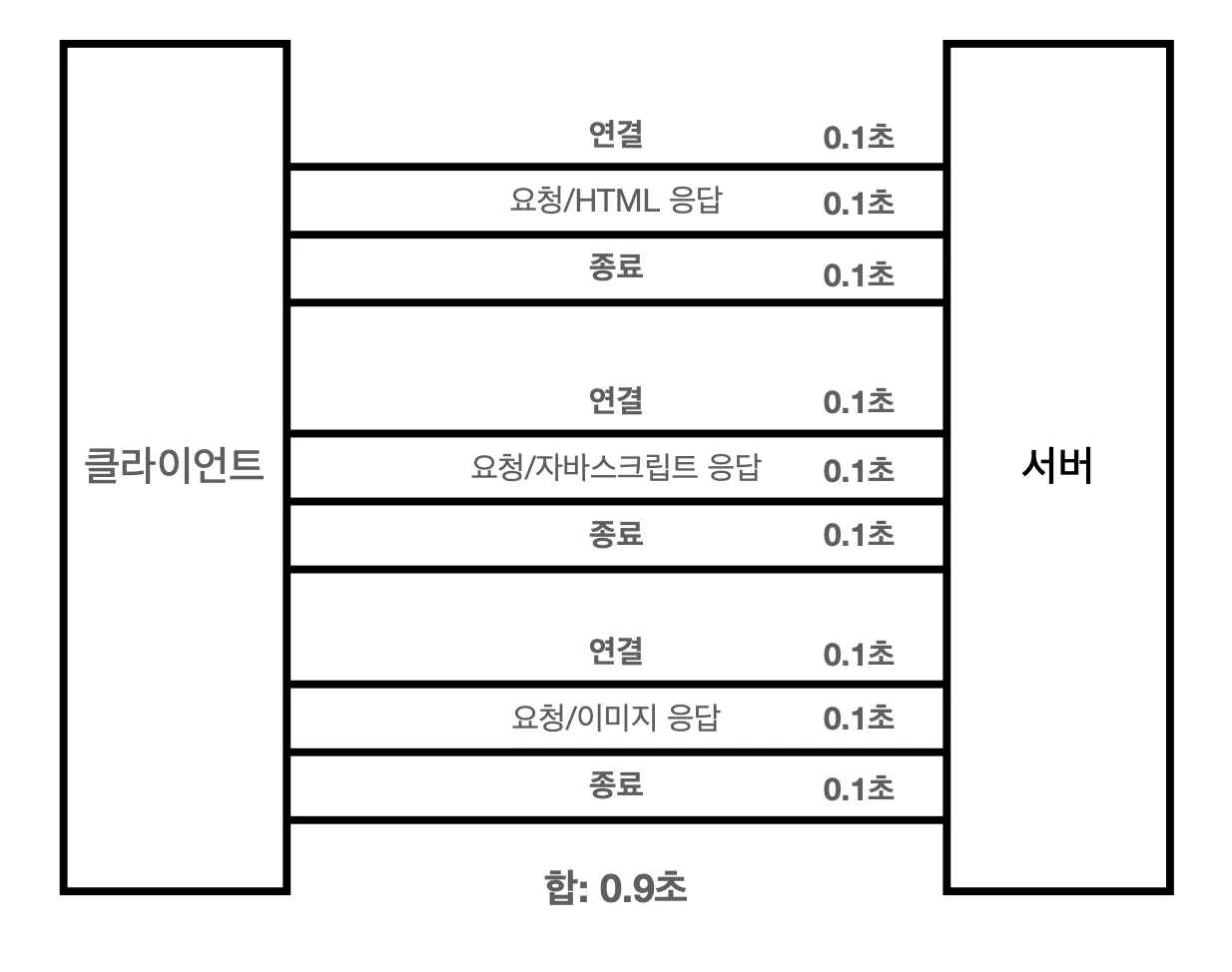
자원을 받을 때마다 연결하고 리소스를 받고 끊고를 반복하는건 너무 비효율적이지 않나요?
HTTP는 기본적으로 지속 연결을 사용합니다. 지속 연결을 사용하게 되면 연결을 하고 나서 리소스들이 모두 다운로드될 때까지 요청, 응답하는 연결을 유지합니다. 요청, 응답 프로세스가 끝나면 연결을 종료합니다.
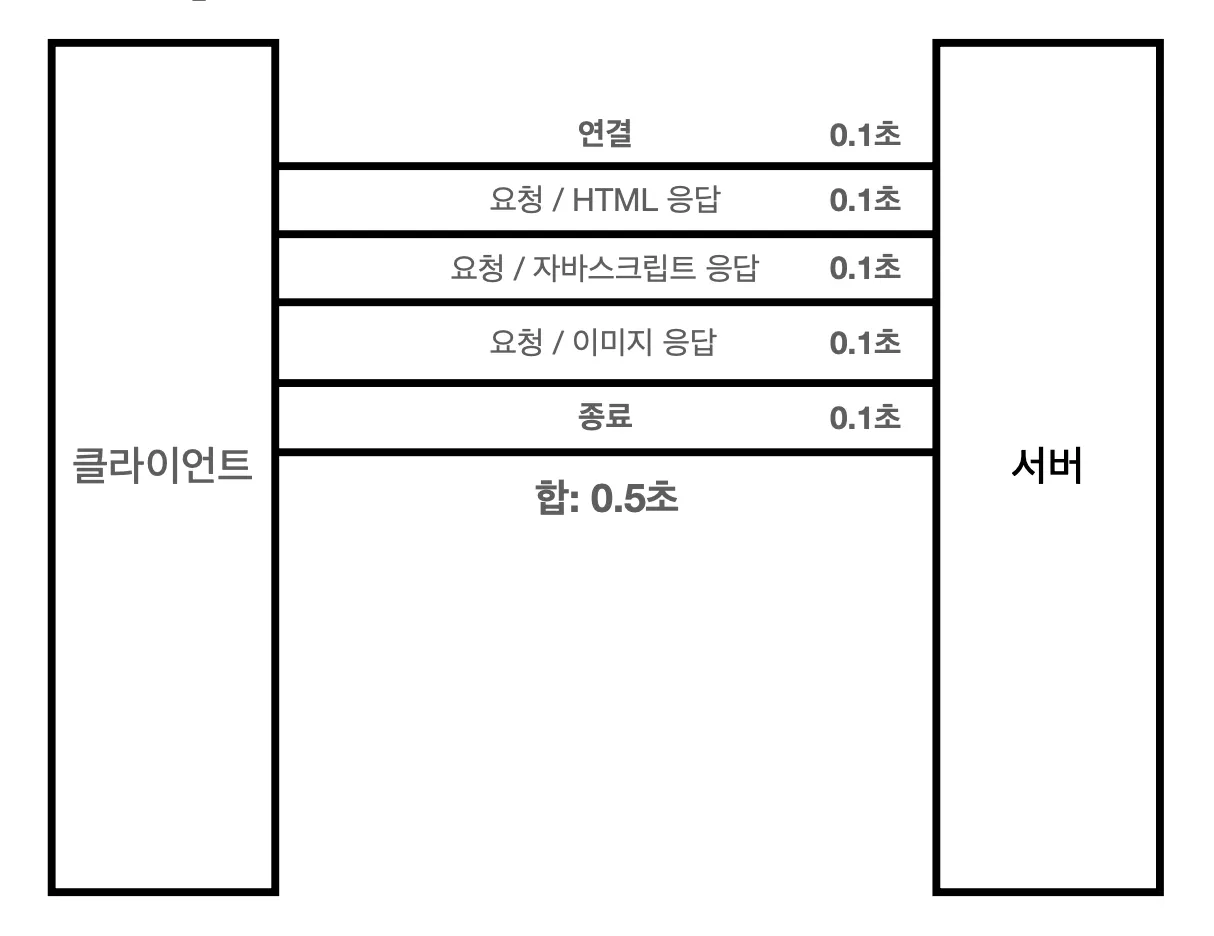
HTTP/2, HTTP/3 에서는 지속 연결을 더 빠르게 진행할 수 있도록 성능을 개선했습니다. 특히 HTTP/3은 UDP 프로토콜을 사용하면서 연결 속도 자체도 줄였습니다.
Stateless를 기억합시다!
같은 시간에 딱 맞춰서 대용량 트래픽이 발생하는 업무를 서버 개발자들이 가장 어려워한다고 합니다.
예를 들어서 선착순 이벤트, 학과 수업 등록 같은 상황에서는 수만명이 동시에 요청을 하는 경우가 생깁니다. 이때는 비 연결성이 소용이 없습니다. 대신 최대한 Stateless하게 서버를 설계해서 대용량 트래픽 시에 서버를 무한 증식시킬 수 있도록 만들어야 합니다.
물론 이런 방식말고도 로그인이 필요없는 페이지에서는 순수한 HTML를 보여줘서 버튼을 동시에 누르지 않게 한다거나 하는 방법을 쓸 수도 있다고 합니다.
아무튼 위의 Stateless 섹션에서도 강조했지만, 무상태로 갈 수 있는 부분은 최대한 무상태로 가고 어쩔 수 없는 부분에 대해서만 Stateful하게 잘 설계해야 합니다.
HTTP 메시지
우리가 생각할 수 있는 모든 바이너리 데이터들은 HTTP를 통해서 HTTP 메시지로 전송할 수 있습니다.
그렇다면 HTTP 메시지가 어떻게 생겼길래 모든 바이너리 데이터들을 메시지로 나타낼 수 있는걸까요?
HTTP 메시지에는 두 가지가 있습니다. HTTP 요청 메시지와 HTTP 응답 메시지 입니다. 이 두 가지 메시지의 구조는 동일하지만 들어가는 데이터에 차이가 있습니다.
일단 메시지의 구조부터 함께 볼게요.
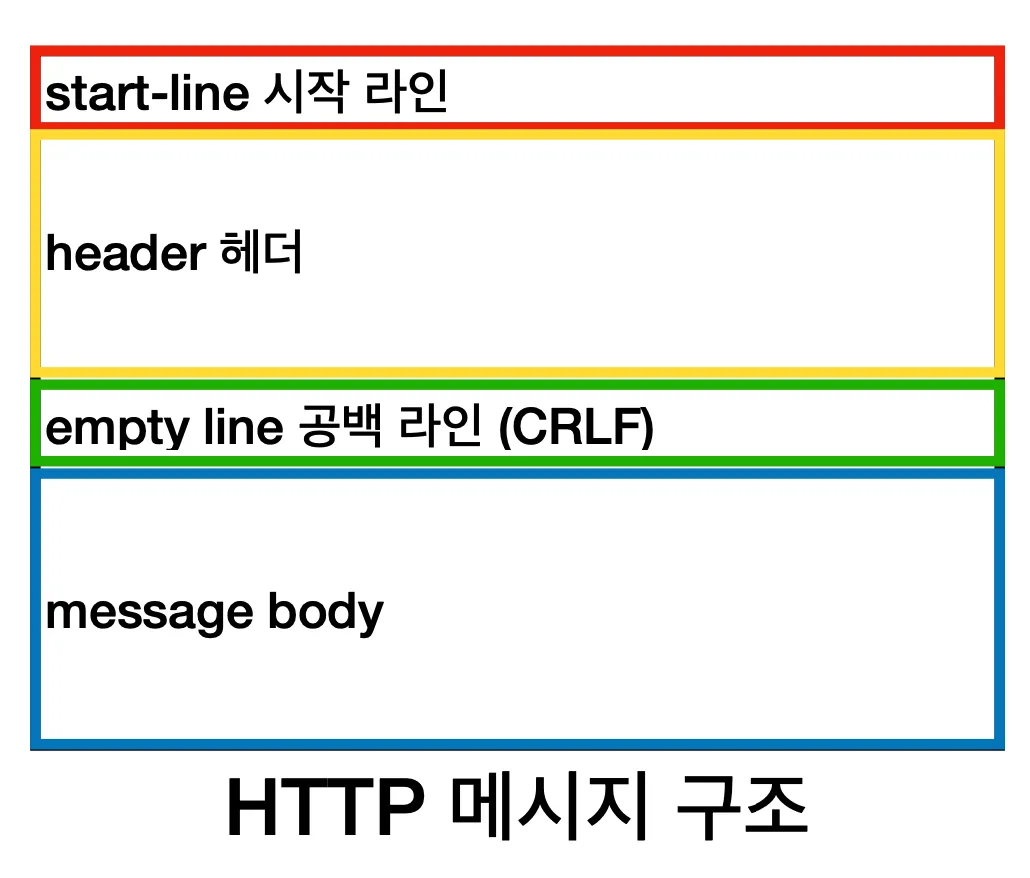
메시지 구조자체는 시작 라인, 헤더, 공백 라인, 바디로 구성이 되어 있네요. 정말 간단합니다.
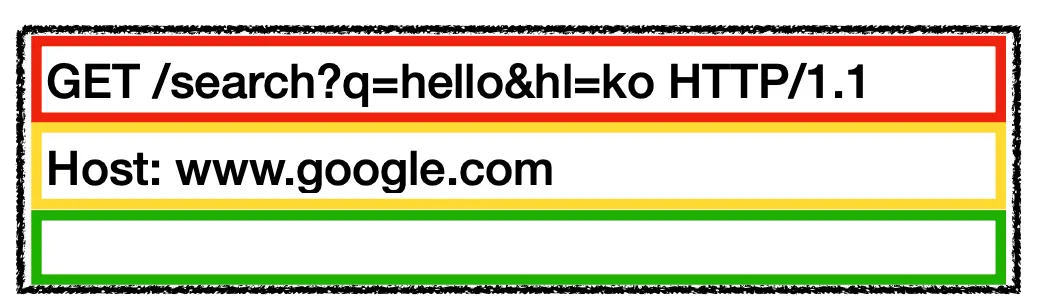
HTTP 요청 메시지의 예시 그림입니다. 요청 HTTP 메시지 구조와는 다르게 메시지 바디가 없는데, 해당 예시에서는 바디가 필요없기 때문에 바디를 추가하지 않았습니다. 메시지 바디가 필요하다면 요청 메시지에서도 추가할 수 있습니다. 바디의 경우에는 필요가 없다면 아무런 데이터를 보내지 않을수도 있고 요청할 데이터가 있다면 데이터를 태워보낼 수도 있습니다.
구조의 각 영역이 가지고 있는 문법들과 특징이 있는데 이 부분을 더 자세하게 알아야지 헤더를 더 잘 사용할 수 있을 거 같군요.
시작 라인
HTTP 요청 메시지의 시작 라인은 이러한 문법을 따릅니다.

•
method
메서드에는 HTTP 메서드가 들어갑니다. HTTP 메서드는 서버가 수행해야 할 동작을 지정해주는 역할을 합니다. GET, POST, DELETE 등의 메서드가 있고 각 메서드는 의미를 가지고 있습니다. HTTP 메서드에 관한 자세한 내용은 이후 챕터들에서 더 자세하게 배워봅시다.
•
request-target
path가 들어간다고 보시면 됩니다. 요청 대상을 나타내며 보통 absolute-path[?query]로 시작합니다.
절대 경로란, /로 시작하는 경로를 생각하시면 됩니다. 물론 다른 경로로 지정하는 방법도 존재합니다. *를 넣거나 http://...?x=y와 같은 다른 유형의 경로 지정 방법이 존재하지만 우리는 그냥 절대 경로로 시작한다고 이해합시다.
•
HTTP-version
이전에 계속 얘기했던 HTTP 버전이 들어가는 영역입니다.
HTTP 응답 메시지의 시작 라인은 이러한 문법을 따릅니다.

•
HTTP-version
이전에 계속 얘기했던 HTTP 버전이 들어가는 영역입니다.
•
status-code
상태 코드가 들어가는 영역입니다. 상태 코드는 클라이언트가 보낸 요청이 성공했는지, 실패했는지를 나타냅니다.
기본적으로 200은 성공을 나타내며, 400은 클라이언트에서 보낸 요청에 문제가 있다는 걸 말합니다. 500 에러는 서버 내부에서 문제가 생겼다는 걸 뜻합니다. 각 상태 코드에 대한 자세한 설명은 이후 챕터에서 계속 진행하겠습니다.
•
reason-phrase
상태 코드가 200이라고 했을 때 이해하지 못할 수 있습니다. 따라서 사람이 이해할 수 있는 짧은 상태 코드 설명 글을 해당 영역에 작성합니다.
HTTP 헤더
HTTP 헤더는 이러한 문법을 따릅니다.

위에서 썼던 Host: www.google.com 헤더 필드는 필드네임이 Host고 필드벨류가 www.google.com 입니다. 필드네임은 대소문자를 구별하지 않기 때문에 Host와 host에 큰 차이가 없습니다. 하지만 필드벨류는 대소문자를 구분하기 때문에 대소문자를 혼동해서 잘못쓰지 않도록 조심해야 합니다.
가장 주의해야할 점은 Host와 : 사이는 꼭 붙여서 써야 한다는 점입니다.
HTTP 헤더는 HTTP 전송에 필요한 모든 부가정보를 가지고 있습니다.
HTTP 바디가 HTML인지, XML인지, 크기는 어떻게 되는지, 압축은 됐는지, 인증 정보가 어떻게 되는지, 요청 클라이언트의 정보(웹 브라우저)가 어떻게 되는지, 캐시 관리는 어떻게 하는지… 등등 다양한 정보를 들고 있습니다.
하단 예시를 보면 Content-Type, Content-Length 에 대한 정보를 헤더가 가지고 있는 걸 볼 수 있습니다. 헤더는 메시지 바디에 들어가진 않지만 필요한 메타데이터 정보를 다 들고 있습니다.

필요 시에 임의의 헤더 네임과 헤더 벨류를 추가할 순 있지만 약속된 값은 아니기 때문에 해당 값을 사용하기로 약속한 클라이언트와 서버만 해당 값을 이해할 수 있습니다.
HTTP 바디
실제 전송할 데이터를 가지고 있는 영역입니다. HTML 문서, 이미지, 영상, JSON 등등 byte로 표현할 수 있는 모든 데이터를 가지고 있습니다.

단순함!
HTTP의 스펙은 단순합니다. HTTP 메시지도 매우 단순한 모양입니다. 시작 라인과 머리, 몸만 기억하면 되니깐요. HTTP는 복잡하게 잘 만들어졌기 때문에 성공한 것이 아니라 단순하고 확장 가능한 기술이기 때문에 성공할 수 있었습니다.