

contents
Paging

각각의 페이지들이 어느 위치에 올라가 있는지 알아내기 위해서는 페이지별로 주소 변환을 해주는 방법이 필요하다.
단순히 Register 2개만의 가지고 주소 변환이 불가능하다.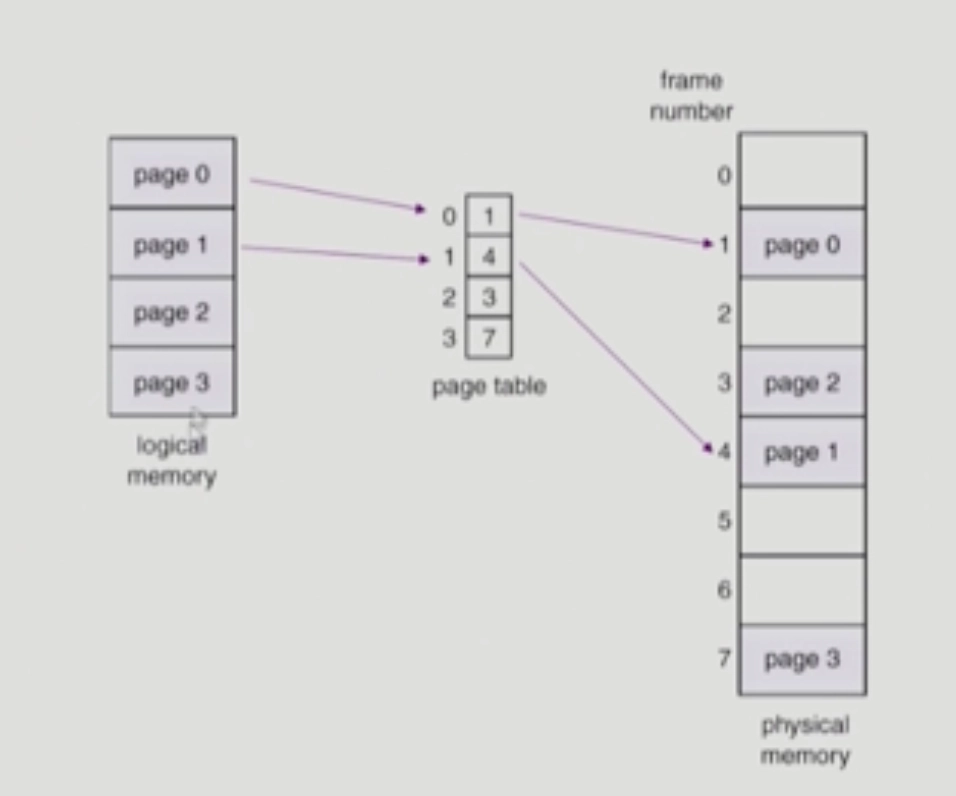
프로그램을 구성하는 논리적 메모리를 동일한 크기의 페이지로 잘라서 각각의 페이지 별로 물리적 메모리의 적당한 위치에 어디든지 비어있는 위치가 있으면 올라갈 수 있게 해준다.
•
페이징 기법에서 주소 변환을 위해서는 페이지 테이블이 사용된다.
◦
논리적인 페이지 0번이 물리적인 메모리 어디에 올라가 있는가, 각각의 논리적인 페이지 별로 주소 변환을 하기 위한 테이블이 페이지 테이블
논리적인 페이지 갯수만큼 entry가 존재함. 그 안의 값으로 물리적인 메모리 몇 번째 자리에 올라가 있는지 표시를 해줌ex. 배열
Array(= table)
•
각각의 논리적인 페이지들이 물리적인 메모리에 어디 올라가 있는가, 논리적인 페이지도 페이지 번호를 0~3까지 매겨둠
•
물리적인 공간에서 해당 페이지가 들어갈 수 있는 공간을 “페이지 프레임"이라고 한다.
◦
페이지 프레임도 0번부터 동일한 크기의 페이지로 잘라서 번호를 매겨둠.
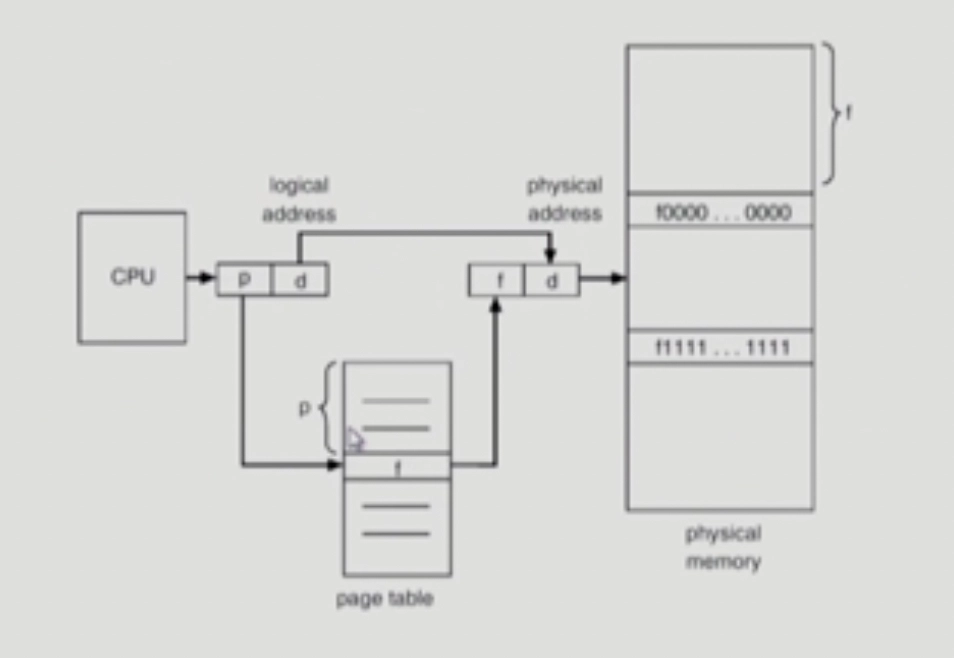
다른 식의 그림으로 그려본 것
CPU가 논리적인 주소를 주게 되면 이걸 물리적인 메모리 상의 주소로 바꿔야 하는데 페이징 기법에서는 주소 변환을 할 때 페이지 테이블을 사용한다.
p : 페이지 번호
d : 그 페이지 내에서 얼만큼 떨어져 있는지를 나타냄(offset)
f : 페이지 프레임 번호
•
이 논리적인 주소를 물리적인 주소로 바꾸게 되는데, 단지 논리적인 페이지 번호를 물리적인 프레임 번호로 위에서 몇 번째 프레임인지를 나타내는 이걸로 바꾸어주면 주소 변환이 끝나는 것
example) 논리적인 주소가 각 도시라고 생각하면 서울시 11-1번지를 주소변환을 하면 제주도 땅에 가 있게 된다. 제주도 땅에 서울시가 올라가 있는데 내부적인 위치(상대적인 위치)는 바뀌지 않는다. 땅 덩어리를 고대로 들어서 옮겼기 때문이다.
p : 서울시(행정구역)
f : 제주도
d : 11-1번지
Implemenation of Page Table
Page table은 메인 메모리에 상주하고 있다.
기본적인 MMU 기법에서는 CPU안에 들어있는 Register를 사용해서 주소 변환을 함.
하지만 페이지 크기는 대체로 4KB, 프로그램의 공간이 100만개의 페이지로 잘린다.
100만개의 entry가 CPU의 register같은 곳에 들어갈 수 있는가? 못들어간다. 페이지 테이블을 위해서 많은 공간이 필요하다는 것•
페이지 테이블은 각 프로그램마다 별도로 존재.
◦
페이지 테이블의 용량이 크기 때문에 register에 넣을수도 없고 메모리 접근을 위한 주소 변환인데, 하드디스크에 저장할 수는 없다.
◦
캐시 메모리에 들어가기에도 용량이 너무 크다.
따라서 페이지 테이블을 메모리에다가 집어 넣는다. •
메모리에 접근하기 위해서는 주소 변환을 한 후에 접근해야 하는데, 주소 변환을 하려면 페이지 테이블에 접근해야하고 페이지 테이블이 메모리에 올라가 있기 때문에 결국에는 2번의 메모리 접근이 필요하게 된다.
1.
페이지 테이블을 통한 주소 변환을 위해서
2.
주소 변환이 됐으면 실제로 데이터를 메모리에서 접근하기 위해서
MMU안에 있는 두 개의 Register가 Paging 기법에서는 어떻게 사용되는가?
메모리 접근을 두 번 하는 것은 비용이 상당히 크다.
따라서, 속도 향상을 위해서 별도의 하드웨어를 둔다.
•
associative register → translation look-aside buffer(TLB) : 일종의 Cache
•
메인 메모리와 CPU 사이에 존재하는 주소 변환을 해주는 계층
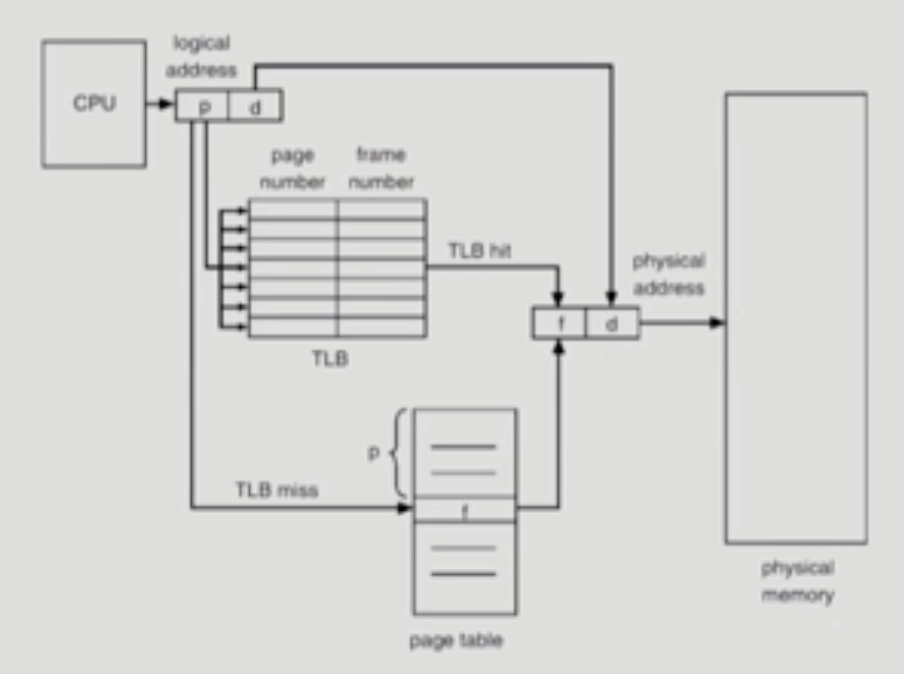
사실은 Page table이 물리적인 메모리 안에 존재
•
Original Paging 기법
CPU가 주는 논리 주소에 대해서 메모리상에 존재하는 페이지 테이블을 통해서 주소 변환을 하고 변환된 주소를 가지고 물리적인 메모리에 접근하게 된다.
→ 2번의 메모리 접근 필요, 속도 개선을 위해서 TLB라는 별도의 하드웨어를 두는 것
메인 메모리 윗단에 있는 캐시 메모리
캐시 메모리
캐시 메모리 처럼 메모리 주소 변환을 위한 별도의 캐시 : TLB
•
데이터를 보관하는 캐시 메모리하고는 용도가 다르다.
•
주소 변환을 위한 캐시 메모리
TLB는 페이지 테이블에서 빈번히 참조되는 일부 entry를 캐싱하고 있다.•
메인 메모리보다 접근이 빠른 하드웨어로 구성되어 있음
•
따라서 CPU가 논리적인 주소를 주면 메모리 상에 있는 페이지 테이블에 접근하기 전에 TLB를 먼저 검색한다.
→ 주소 변환 정보 중에서 TLB에 저장되어 있는 정보를 이용해서 정보 변환이 가능한 지를 체크해보는 것
if, p에 해당하는 entry가 TLB에 저장되어 있었다고 하면
TLB를 통해서 바로 주소 변환이 된다.
바로 주소 변환을 해서 물리적인 메모리에 접근을 하니깐 메모리를 한 번만 접근하면 된다. if, TLB에 없다면
페이지 테이블에 접근을 해서 일반적인 주소 변환을 하고 메모리에 접근하게 된다.
2번의 메모리 접근이 필요하다. TLB라는 건 페이지 테이블의 정보 전체를 담고 있는 것이 아닌 일부를 담고 있음. 빈번한 entry만.페이지 테이블에서는 주소 변환을 할 때 페이지 번호가 p면 그냥 위에서부터 p번째 entry를 가면 나온다.
But, TLB는 모든 값을 가지고 있는 것이 아니기 때문에 몇 번째 entry를 주소 변환한 게 f인지 알 수 없다.
논리적인 페이지 번호 p, 그 p에 대한 주소 변환된 프레임 번호 f, 이 두 개를 쌍으로 가지고 있어야 한다. why?
모두 가지고 있는 것이 아니기 때문에 논리적인 페이지, 물리적인 페이지의 쌍을 지니고 있어야 한다.
+) 주소 변환을 위해서 TLB에 특정 항목을 검색하는 것이 아니고 전체를 검색해야 한다.
p라는 페이지가 TLB에 있는지 확인해보려면 위에서부터 p가 있는지 다 찾아봐야 함. → 없으면 페이지 테이블
Associative registers
TLB는 특정 항목 서치하는 것이 아닌 전체 서치를 해야 한다.
전체 서치를 하는 시간이 오래 걸린다. 그런걸 막기 위해서 TLB는 보통 parallel search가 가능한 associative register를 통해서 구현이 한다.
•
CPU가 페이지 번호 p를 주면 p라는 주소 변환 정보가 있는지를 병렬적으로 싹 서치를 해서 어느 한 군데 p가 있으면 주소 변환이 바로 이루어 진다.
•
어디에도 없으면 TLB miss가 났다고 본다. → 이 경우에는 페이지 테이블을 통해서 주소 변환
◦
페이지 테이블을 통한 주소 변환은 전체를 서치할 필요가 없음
◦
p를 주면 p로 가면 바로 주소 변환이 이루어 지기 때문에 병렬 서치, sequencial 서치가 필요한 것이 아니고 직접 p번째 entry에 가면 되는 것
주소 변환을 위한 탐색에서도 차이점이 존재한다.페이지 테이블은 각각의 프로세스마다 존재하는 것
프로세스마다 논리 체계가 다르고 그에 따라 페이지 테이블이 프로세스마다 존재해야 함.
그렇기 때문에 페이지 테이블의 일부를 담는 TLB도 프로세스마다 다른 정보로 존재.
다른 프로세스로 넘어가면 페이지 테이블에 들어가는 주소 변환 정보도 달라진다. •
TLB에 있는 정보는 context switch가 일어날 때 flush를 시켜서 모든 entry를 비워야 한다.
→ 프로세스마다 주소 변환 정보가 다르기 때문에 그렇게 해줘야 함.
Effective Access Time
실제로 메모리 접근하는 시간이 얼만큼 되겠는지
Formula )
TLB를 접근하는 시간 : ⍴
•
보통은 TLB 접근하는 시간이 메인 메모리 접근하는 시간인 1보다 작음
•
⍴ < 1(메인 메모리 접근 시간)
TLB로부터 주소 변환이 되는 비율(TLB로부터 주소 변환 정보가 찾아지는 비율) : ⍺
실제 메모리 접근을 하는 시간이 어느 정도 될 것인가
•
TLB에서 주소 변환 정보가 찾아지는건, TLB 접근 시간 ⍴하고 메모리 접근 시간 1만큼이 걸릴 것
→ (1 + ⍴)
•
주소 변환 정보가 TLB 에 없는 경우(1 - ⍺), TLB 접근은 해봤는데 TLB 에 없는 경우 ⍴하고 메모리 접근하는 시간 2만큼이 걸릴 것 → (2 + ⍴)
→ 결과적으로 TLB 로부터 주소 변환이 되는 비율은 ⍺(굉장히 높다, 거의 1에 가까움)
→ ⍴ (굉장히 작음, 1에 비해서 작다)
→ 2보다는 훨씬 작은 값이 된다.
페이지 테이블을 이용한 주소 변환
페이지 테이블이 1. 메모리에 있고 2. 속도 향상을 위해서 TLB 라는 주소 변환용 캐시를 이용해서 메모리 접근을 더 빠르게 한다.Two-level Page Table
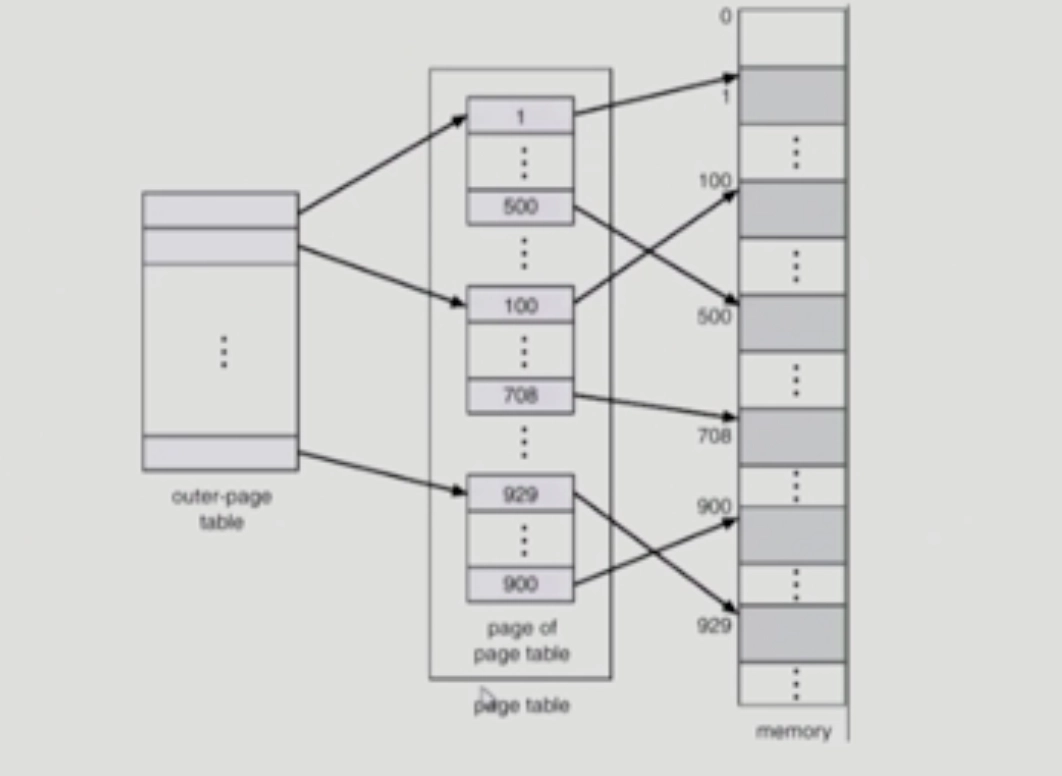
Page Table이 두 단계로 존재하는 경우, 안쪽 페이지 테이블과 바깥쪽 페이지 테이블이 있다.
CPU가 논리적인 주소를 주게 되면 페이지 테이블을 두 단계 거쳐서 주소 변환을 하고 실제로 메모리 접근을 하게 된다.
why?
1.
속도를 빠르게 하기 위해서? but, 줄어들지 않음 → 한 번 하던걸 두 번하니깐 시간이 더 걸린다.
2.
공간을 줄이기 위해서? 맞다. 이게 목적.
현대의 컴퓨터는 메모리 주소 체계가 굉장히 크다.
(32비트의 address사용, 64비트 address 체계까지 올라옴)
32비트로 표현할 수 있는 전체 메모리 논리적인 주소 한 개→ 프로그램 크기 maximum 얼마까지 가능하겠는가
현대의 컴퓨터 시스템은 각 프로그램의 메모리 크기하고 실제의 물리적인 메모리의 크기하고 독립적이다.
•
물론 물리적인 메모리의 크기가 크다면 더 빠를 것
◦
가능한 많은 내용이 물리적인 메모리에 올라가기 때문에
•
어차피 페이지 단위로 나뉘어서 메모리에 올라가기 때문에 물리적인 메모리보다 논리적인 메모리 크기가 크더라도 실행하는데 문제는 없다.
◦
프로그램마다 가지는 가상 메모리의 크기가 maximum 얼마까지 가능한가
▪
그건 가상 메모리를 표시하는 주소 체계를 몇 비트 주소 체계를 쓰느냐에 달려있다.
메모리에는 주소가 어떤 단위로 매겨지느냐 하면 byte단위로 매겨집니다.
example) 맨 위의 0번지는 0번째 byte, 젤 아랫쪽의 3000번지 거기는 3000바이트째 주소
◦
주소를 32비트를 쓴다고 하면 32비트로 표현 가능한 서로 다른 정보가 몇가지입니까?
1비트로 표현 가능한 정보가 2가지, 즉 2^32 가지 위치 구분이 가능
메모리 주소가 0번지부터 2 ^ 32 - 1 번지까지 주소를 매기기 가능2^10 | K(킬로) |
2^20 | M(메가) |
2^30 | G(기가) |
◦
32비트 주소 체계를 사용해서 표현할 수 있는 메모리 주소는 2의 32승 바이트를 표시할 수 있고 각 프로그램이 가질 수 있는 최대 메모리 주소는 4기가 바이트
▪
4기가 바이트의 공간을 페이지 단위로 쪼갬
각각의 페이지 크기가 4KB총 4기가 바이트 공간을 4KB로 쪼개면 페이지 1M개의 page 개수를 얻을 수 있음
Page Table의 entry가 1M(백만개 이상)개
Page Table의 entry가 1M(백만개 이상)개▪
page table도 메모리에 들어가야 하는 것이고 각 프로그램마다 페이지 테이블이 따로 있는데 이걸 모두 메모리에 넣게 되면 공간 낭비가 심해진다.
▪
각각의 page table entry가 보통 4Byte정도로 보면 된다.
•
그러면 프로그램마다 페이지 테이블을 위해서 4MB의 공간이 필요
•
2단계 페이지 테이블을 쓰겠다는 것
•
전체 메모리 주소 공간 중에서 실제 프로그램이 사용하는 공간은 지극히 일부
코드, 데이터, 스택, 사용이 안되고 있는 논리 주소(상당 부분)
◦
page table이라는 것은 entry를 중간에 구멍이 있다고 해서 빼고 만들 수는 없다.
▪
배열이라는 것은 index를 통해서 접근을 하는데 앞에서 p번째 entry로 접근하기 때문에 없는 공간을 비울 수 없다.
▪
주소 체계 중에서 상당히 일부분만 실제로 사용됨에도 페이지 테이블 entry는 다 만들어져야 한다.
◦
따라서, 1단계 페이지 테이블을 쓰면 공간 낭비가 심함.
그래서 만들게 된 것이 바로 2단계 페이지 테이블
Two-Level Page Table(Image)

•
바깥쪽 페이지(p1)의 번호 p1, 안쪽 페이지(p2)의 번호 p2, offset
Address-translation Scheme
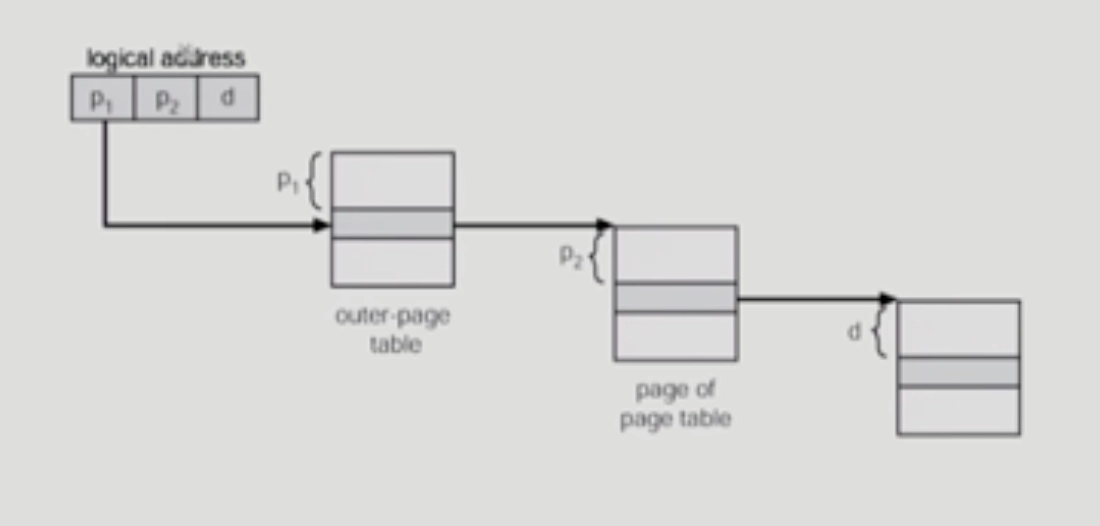
1.
outer-page table에서 p1으로 가서 주소 변환 정보를 얻는다.
2.
이곳에서 얻어지는 것은 안쪽 페이지 테이블 중에 어떤 페이지 테이블인지 지정해줌.
•
안쪽 페이지 테이블은 여러개가 존재.
•
각각의 바깥 페이지 테이블마다 안쪽 페이지 테이블이 만들어지는 것
•
바깥쪽 페이지 테이블의 포인터가 가르키는 것은 안쪽 페이지 테이블이 어떤 건지
3.
안쪽 페이지 테이블의 페이지 번호를 이용해서 p2번째 entry에 가면 논리적인 페이지 프레임 번호를 얻게 된다.
4.
이 페이지 프레임 번호를 logical address 에 덮어씌우면 그 페이지 프레임이 나오고 페이지에서 d번째 떨어진 위치에서 원하는 정보를 찾을 수 있게 된다.
이렇게 2단계로 주소 변환•
2단계 페이지 테이블에서 한 가지 기억해야 할 점.
안쪽 페이지 테이블의 크기가 페이지 크기하고 동일
→ 즉, 안쪽 페이지 테이블은 그 자체에 페이지화되어서 페이지 어딘가에 들어가 있게 된다.
◦
페이지 하나의 크기가 4KB라고 했기 때문에 안쪽 테이블의 크기도 하나가 4KB이다.
◦
보통 페이지 하나의 entry의 크기가 4Byte, 4KB의 안쪽 페이지 테이블에서 entry하나당 4byte씩이라고 하면 엔트리 갯수는 1K개를 집어넣을 수 있음
if, 32비트 주소 체계가 아니고 64비트 주소 체계를 사용한다고 생각한다면, (페이지는 똑같이 4KB, 2단계 페이지 테이블을 사용)
그렇다면 p1, p2, d는 각각 몇 비트가 필요할까.(생각해보셈)
서로 다른 n개의 정보를 구분하기 위해서 몇 비트가 필요하냐
N비트로 구분 가능한 서로 다른 위치가 몇 군데 인가.
•
p2에서는 1K군데를 구분, d에서는 서로 다른 4K군데를 구분
→ 10비트, 12비트
•
전체 주소에서 빼면 맨 앞에 비트는 자동으로 계산 가능
Two-level Page Table을 사용하는 이유
시간은 더 걸리지만 페이지 테이블을 위한 공간 줄이기 → 프로그램마다 entry가 100만개 이상 필요하기에
•
2단계 페이지 테이블을 사용해도 안쪽 테이블에는 여전히 100만개 이상이 필요함.
오히려 밖에 테이블이 하나 더 만들어지기 때문에 1단계보다 공간적으로도 손해!시간, 공간 모두 손해인데 2단계 테이블을 사용하는 이유는 뭘까?
◦
안에 들어갈 값이 없는데 배열이기 때문에 상당 수의 값들이 비어 있는 상태로 만들어지게 된다.
이런 문제를 2단계 페이지 테이블이 해소할 수 있다.물론 논리적인 페이지 크기만큼 바깥 페이지 테이블이 만들어지지만 실제로 사용하지 않는 주소에 대해서는 안쪽 페이지 테이블이 안만들어지고 포인터가 그냥 null상태로 되어 있다.
•
실제로 사용되는 메모리 영역에 대해서만 안쪽 페이지 테이블이 만들어져서 주소를 가르키고 있고 중간에 사용이 상당히 안되는 주소 공간에 대해서는 null이 되어서 안쪽 페이지 테이블이 안 만들어지기 때문에
•
페이지 테이블의 공간을 줄일 수 있다.
•
전체 주소 공간 중에서 상당 부분은 실제로 사용이 안되는 공간이기 때문에 안쪽 페이지 테이블이 만들어지지 않기 때문에 그런 것이다.
[문제] 32개의 주소 체계 중에서 페이지 안에 있는 offset이 몇 비트가 되어야 하고, 안쪽 페이지 번호가 몇 비트로 표현되어야 하고, 바깥쪽 페이지 번호가 몇 비트로 표현되어야 하는지 알아보자.
•
비트 수를 알기 위해서는 맨 안쪽부터 차례대로 따라오면 된다.
1.
일단 페이지 하나의 크기가 4KB
4KB안에서 byte 단위로 주소 구분을 하려면 몇 비트가 필요할까요.
4KB = 2^12 byte
하나의 페이지 안에서 몇번째 떨어져있는 바이트 인지를 구분하기 위해서는 서로 다른 4K(12승)의 위치를 구분하기 위해서 몇 비트가 필요한지 보면 된다.
(example)
100 채의 집을 구분하기 위해서는 10진수로 2자리만 필요하다(00~99)
만약, 이 안에 집이 10000채가 있다면 0000~9999, 10진수 4자리까지 필요
즉, 10의 4승 채의 집을 구분하려면 10진수 4자리가 필요하고 2의 12승 바이트를 구분하기 위해서는 12비트가 필요
그래서 페이지 안에서 바이트 단위로 얼마나 떨어져있는지 구분하는 offset를 위해서 12비트가 필요한 이유.
2.
32비트 중에서 20비트(페이지 번호)
어떻게 안쪽 페이지 비트, 바깥쪽 페이지 비트로 나눌 것인가?
편하게 10비트씩 나누면 되는걸까? 이렇게 결정되는것은 아님.•
안쪽 페이지 테이블이 페이지화되어서 들어간다고 했음 → 4KB
•
각 entry가 4B이기 때문에 entry수가 1K개가 존재.
a.
안쪽 페이지 테이블의 시작 위치로부터 p2 페이지 번호 값은 이 페이지 테이블에서 위에서부터 몇 번째 entry인지를 구분하는 숫자(p2)
b.
1K 안에서 구분해내야 하기 때문에(서로 다른 2^10 가지 entry를 구분하기 위해서) p2는 10비트가 필요하다.
따라서 전체 32비트에서 12, 10비트를 빼게 되면 10비트가 남게 된다.