
인프런 - 모든 개발자를 위한 HTTP 웹 기본 지식에서 김영한 님이 강의해주는 내용을 바탕으로 정리를 진행했습니다. 강의를 직접 듣고 싶으신 분들은 하단 북마크를 눌러주세요.
*제 포스팅에 나오는 모든 이미지는 김영한 님께서 만든 강의 자료에서 가져왔습니다.

목차 보기
요약 정리
전체 내용을 보기 쉽게 요약 정리해둔 부분입니다. 자세히 알기 원하는 문장을 선택하시면 관련 섹션으로 이동합니다.
들어가며
우리가 서버 개발자로 HTTP API를 설계한다고 가정해봅시다. 우리가 만들어야 하는 API는 회원 정보 관리 API 입니다. 5가지 요구사항이 존재하고 서버 연동을 하기 위해서 API, URL를 설계해야 하는 상황입니다.
처음 API를 설계해보는 우리는 의미있고 그럴 듯한 이름으로 네이밍을 합니다.

괜찮은 URI 설계일까요?
URI를 설계할 때 가장 중요한 건 리소스 식별입니다. 리소스에 의미를 담아야 하는거죠.
리소스?
“미네랄을 캐라” 라는 문장이 있다고 할 때, 리소스는 미네랄입니다. “미네랄을 캐라” 라는 문장자체가 리소스가 아닙니다. 따라서 해당 개념을 회원 정보 관리 API를 만드는데 적용하면 회원 등록, 회원 조회, 회원 수정, 회원 삭제 이러한 것들이 리소스가 아니라는 걸 알 수 있습니다.
우리에게 리소스는 “회원” 이라는 개념 자체입니다.
그렇다면 리소스를 어떻게 식별하는게 좋을까요?
등록, 수정, 조회, 삭제는 모두 배제하고 회원이라는 리소스만 식별하면 됩니다. 회원을 URI에 매핑하는 겁니다.
리소스를 식별하라는 개념이 뭔지 대충 알았으니 API를 다시 설계해볼까요?

이번에는 리소스를 식별한다는 점을 중요하게 잡고 리소스를 리소스답게 설계했습니다. 또한 path는 계층 구조를 가진다는 점을 유념해서 계층 구조를 활용하여 URI를 설계했습니다.
근데 한 가지 문제점이 보이지 않나요? 구분이 안됩니다. 회원 조회, 등록, 수정, 삭제가 모두 같은 path를 가지게 됩니다. 위에서 하라는대로 리소스와 행위(조회, 등록..)을 분리했고 URI는 리소스만 식별해야하기 때문에 path도 리소스를 식별할 수 있게 만들었는데, 모든 행위들이 같은 path를 가지는 문제가 생겼습니다.
그렇다면 어떻게 행위들을 구분할 수 있을까요?
이 문제를 해결해주는 것이 HTTP 메서드 입니다.
우리가 URI의 리소스만 식별해두면 HTTP 메서드인 GET, POST, PUT, PATCH, DELETE 가 행위를 대신 해주게 됩니다.
HTTP 메서드
HTTP 메서드는 클라이언트에서 서버로 무언가를 요청할 때 기대하는 행동입니다.
HTTP 메서드에는 주요 메서드가 5개 있는데, 그게 바로 GET, POST, PUT, PATCH, DELETE 입니다.
GET 은 이름 그대로 뭔가를 가져오는 행동이고, POST 는 무조건 데이터를 담아서 클라이언트에서 서버로 데이터를 보내줘야 합니다. PUT 은 클라이언트에서 서버로 리소스를 보내서 해당 리소스로 원래 있던 리소스를 대체하는 일을 합니다. 파일을 저장할 때 이미 파일이 존재해서 해당 파일을 덮어쓰는 예시를 생각해주시면 이해하기 쉽겠네요. PATCH 는 회원 이름을 변경한다거나 특정 필드 정보를 부분적으로 변경할 때 사용합니다. DELETE 도 이름 그대로 삭제를 하는 메서드라고 생각하시면 됩니다. 지금은 가볍게 설명했지만 뒷 부분에서 더 자세하게 설명할게요.
주요 메서드 5가지말고도 기타 메서드가 존재하는데, HEAD, OPTIONS, CONNECT, TRACE 입니다.
HEAD 는 GET과 동일하다고 보면 되는데 다른점은 바디를 제외하고 보낸다는 점입니다. OPTIONS, CONNECT, TRACE 는 거의 사용하지 않기 때문에 그런 메서드가 존재하는구나 라고 알아만 두시면 될 것 같네요.
그러면 이제부터 주요 메서드들을 자세하게 설명해드리겠습니다.
GET
GET 은 리소스 조회를 합니다. 해당 path에 있는 자원을 달라고 요청하는 메서드입니다.
검색 시, 검색 엔진에 내가 필요한 파라미터를 넘겨야 한다면 query(쿼리 파라미터, 쿼리 스트링)를 통해서 전달합니다. 이전에 [Network] URI와 웹 브라우저 요청 흐름 챕터에서 key-value 형태로 데이터를 보내는 쿼리를 배웠을 겁니다. GET 메서드는 쿼리를 이용해서 path만으로는 나타낼 수 없는 데이터들을 넣어줍니다.
[Network] URI와 웹 브라우저 요청 흐름 챕터에서 key-value 형태로 데이터를 보내는 쿼리를 배웠을 겁니다. GET 메서드는 쿼리를 이용해서 path만으로는 나타낼 수 없는 데이터들을 넣어줍니다. body를 사용해서 데이터를 보내주면 안되나요?
전에도 얘기했듯 GET 메서드는 메시지 바디를 전달할 수 있습니다. 최근 스펙에서는 메시지 바디를 전달할 수 있게 허용해줬지만 실무에서는 HTTP GET 메서드 바디에 무언가를 넣는 걸 권장하지 않습니다. 전달할 데이터는 쿼리를 통해서만 보내죠.
그 이유는 GET 메서드에서 메시지 바디 값을 전달하는 걸 지원하지 않는 서버가 많기 때문입니다. 따라서 문제가 발생할 수도 있기 때문에 권장하지 않습니다.
상황) GET 메서드를 사용해서 100번 유저 정보 조회
1.
클라이언트는 서버로 100번 유저를 달라는 요청(GET /members/100)을 보냅니다.
*GET은 요청시에 바디 데이터를 전달하지 않습니다.

2.
요청을 받은 서버는 100번 유저 정보를 조회해달라(GET /members/100)는 클라이언트의 요청을 해석합니다. 그리고 내부 DB를 조회해서 메시지를 만듭니다. 그리고 해당 Response 메시지를 클라이언트로 보냅니다.
POST
POST는 클라이언트가 서버로 요청을 보낼 때 데이터를 줍니다. 서버는 보낸 요청 데이터를 받아서 처리해줍니다.
메시지 바디를 통해 서버로 요청 데이터를 전달하고 서버는 해당 데이터를 받아서 처리합니다. POST 메서드에서는 메시지 바디를 통해서 들어온 데이터를 처리하는 모든 기능을 수행합니다. 신규 데이터 등록이나 프로세스 처리 같은 기능말이죠.
상황) POST 메서드를 사용해서 유저 등록
서버와 클라이언트는 POST /members로 데이터를 보내면 서버가 저장할거라는 약속을 미리 해둡니다.
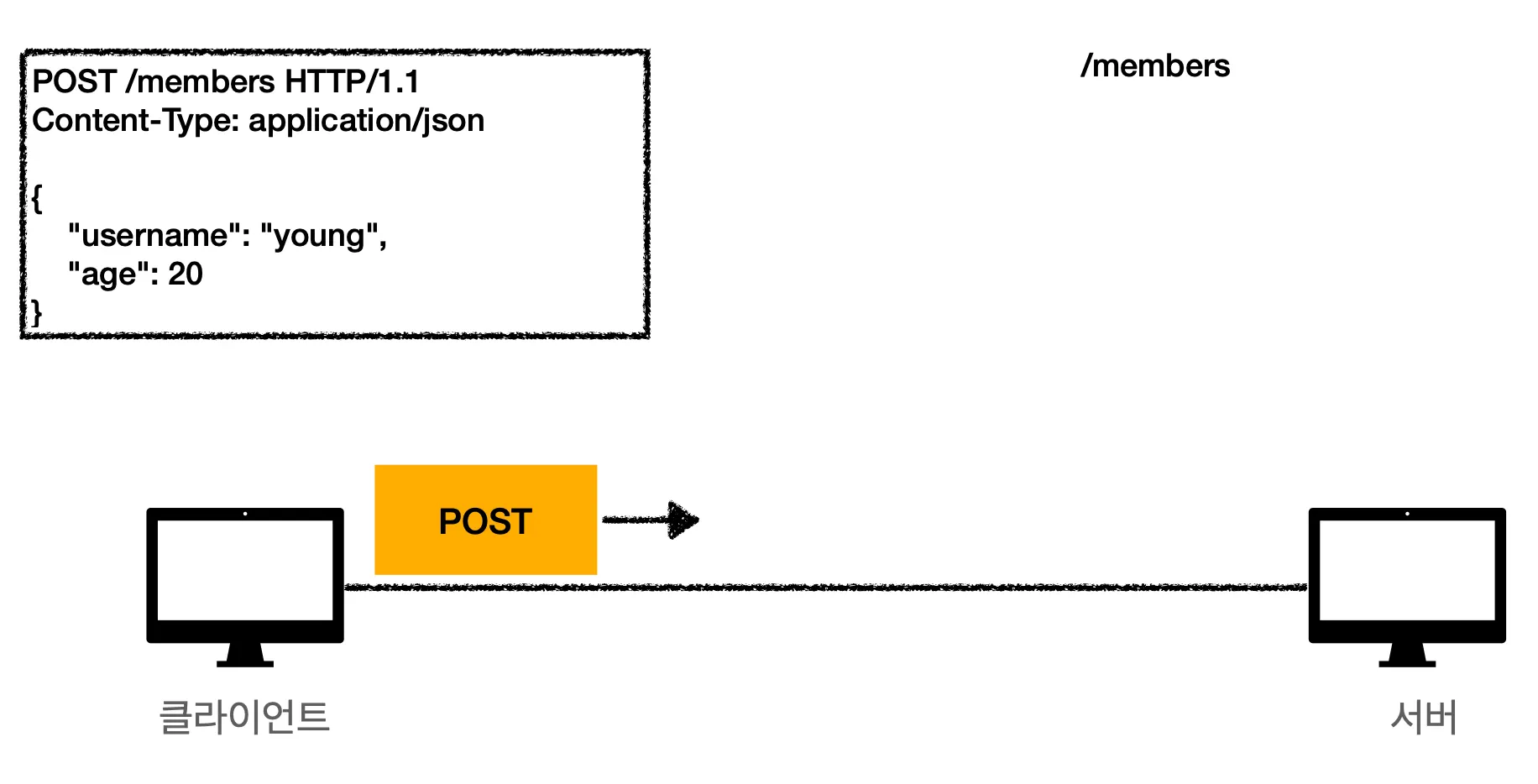
1.
클라이언트에서는 필요한 데이터를 서버로 보냅니다. 유저를 등록하는 상황이니 현재 상황에서는 유저 정보가 보내지겠죠?
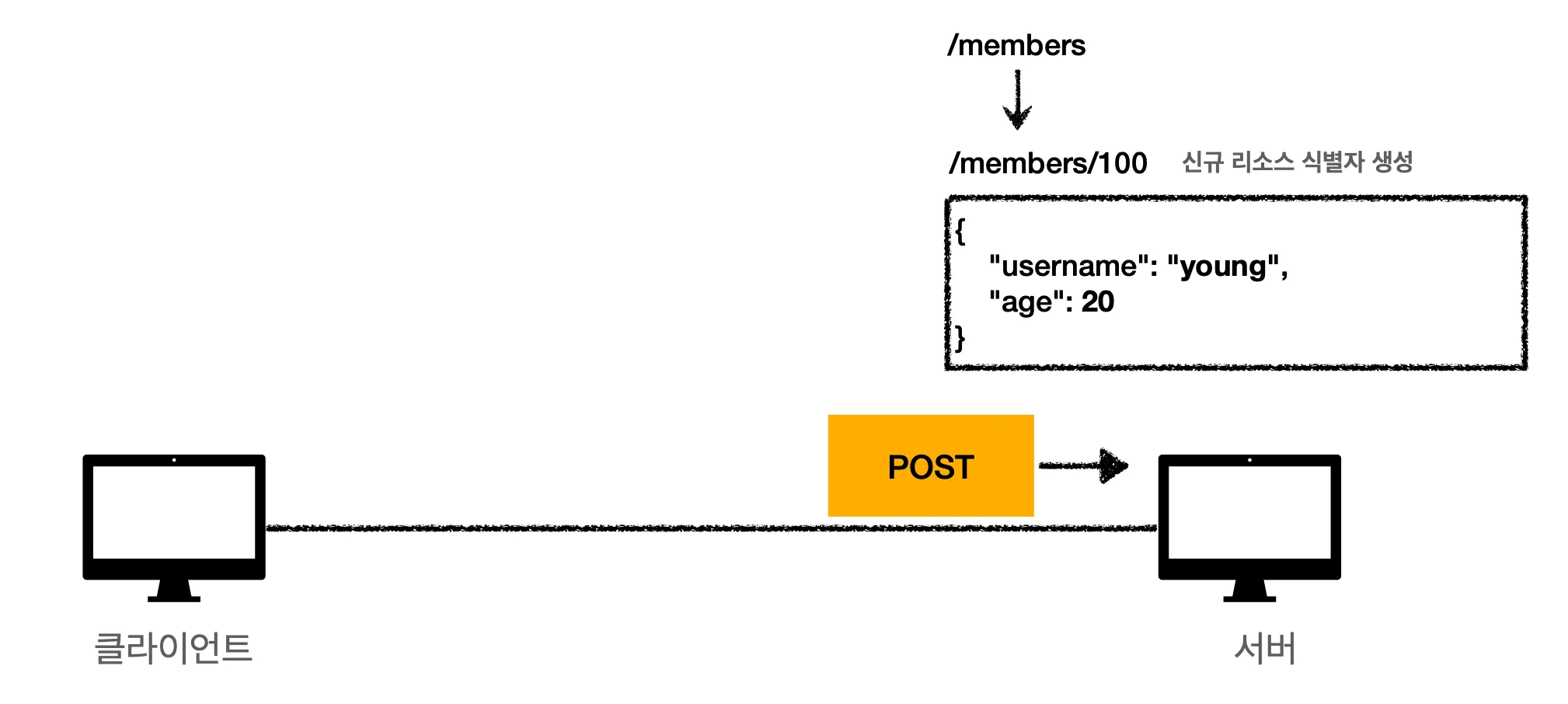
2.
유저 정보를 받은 서버가 DB에 받은 데이터를 저장합니다. DB에 데이터를 저장하면서 신규 리소스를 식별할 수 있는 리소스 식별자를 생성합니다. 해당 데이터에는 100를 부여해줬군요.
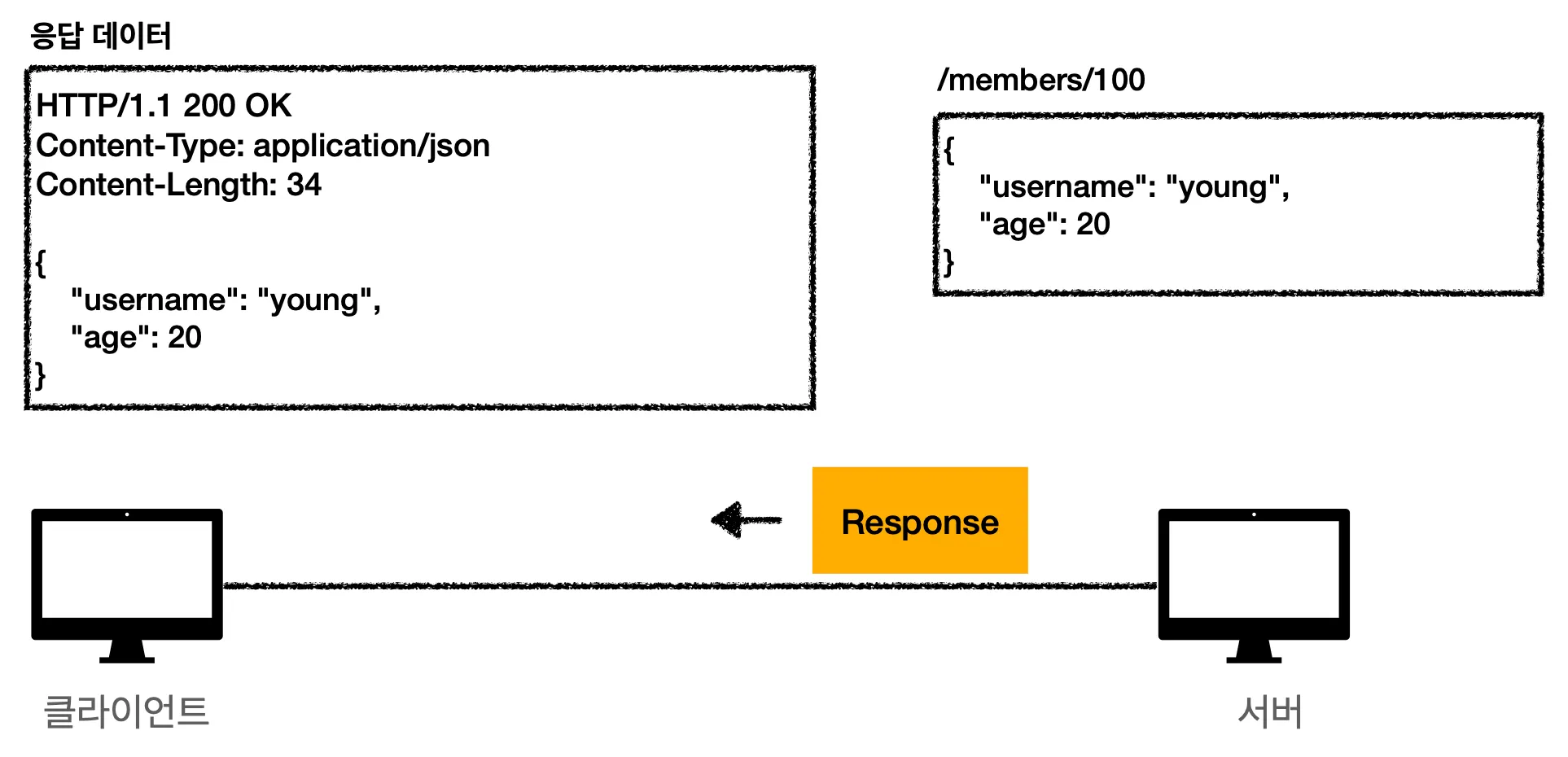
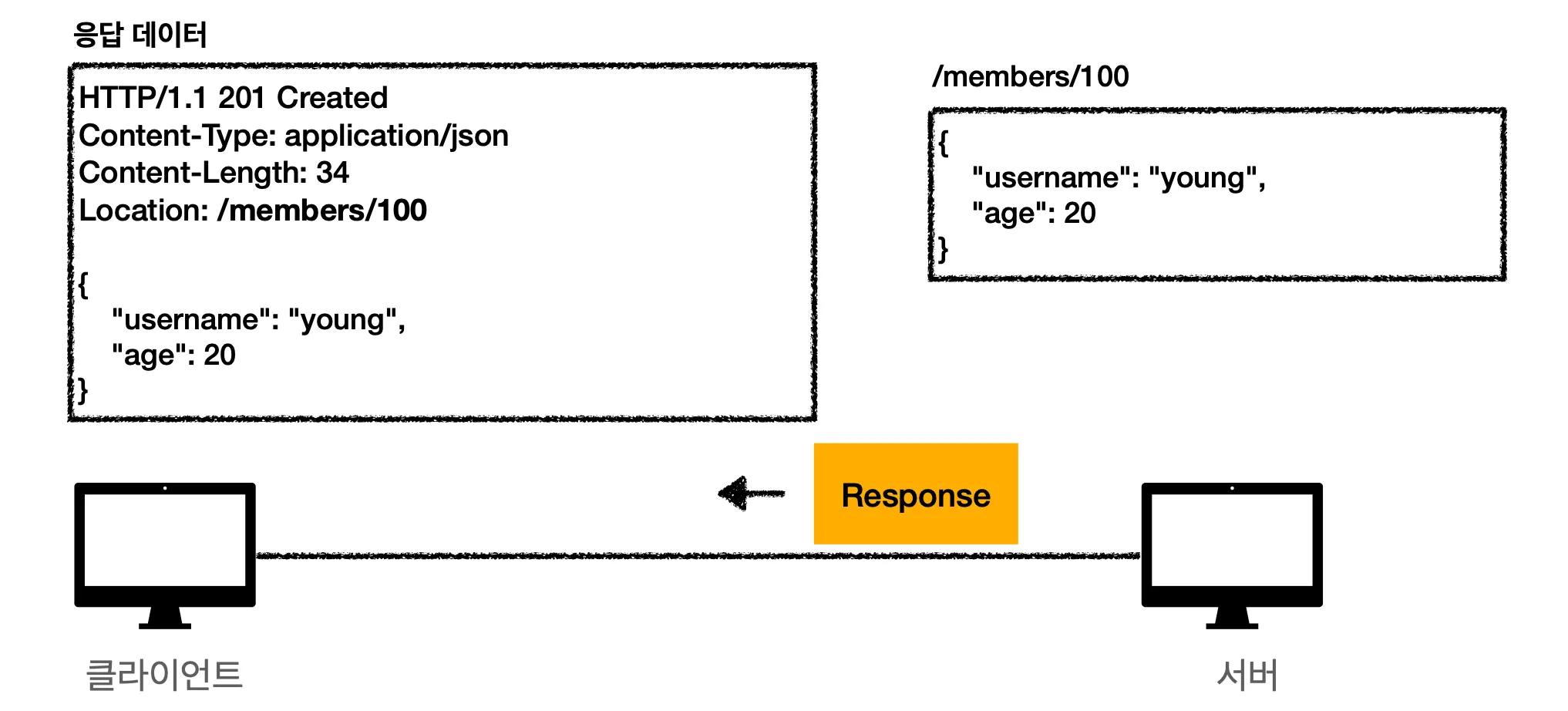
3.
서버는 클라이언트로 Response 메시지를 보냅니다. 응답 메시지에는 데이터 생성이 성공했다는 상태코드가 나타나있네요. 그리고 리소스가 생성된 경로(path)를 보내줍니다. 아까 /members/100 에 리소스를 생성했으니 Location: /members/100 이네요. 마지막으로 등록된 리소스에 대한 데이터를 보내줍니다.
POST는 메시지 바디를 통해 서버로 요청 데이터를 전달하고 서버는 해당 데이터를 받아서 처리 한다는 행위를 나타내는 메서드입니다. 그렇다면 POST는 요청 데이터를 어떻게 처리한다는걸까요? 처리한다는 게 무슨 뜻일까요?
스펙은 POST 메서드를 이렇게 표현합니다.
POST 메서드는 대상 리소스가 리소스의 고유한 의미 체계에 따라 요청에 포함된 표현을 처리하도록 요청합니다.
무슨 말인지 이해가 되시나요? ( ◉ 3 ◉ )
이해를 돕기 위해서 POST가 사용되는 기능에 대한 예시를 보겠습니다.
⓵ HTML 폼에서 회원가입, 주문 처리 등에 사용
⓶ 게시판 글쓰기, 댓글 달기
⓷ 서버가 아직 식별하지 않은 새 리소스 생성
⓸ 기존 자원에 데이터 추가
이 리소스 URI에 POST 요청이 오면 요청 데이터를 어떻게 처리할지 리소스마다 따로 정해야 합니다. 왜냐하면 따로 정해진 것이 없기 때문입니다.
POST에 대한 정리를 다시 한 번 해보자면,
1.
새 리소스 생성(등록) - POST의 주요 기능
2.
요청 데이터 처리
단순히 데이터를 생성하거나, 변경하는 것을 넘어서 프로세스를 처리해야 하는 경우에도 POST를 사용합니다. 프로세스가 처리되는 경우는 서버에서도 큰 변화가 생깁니다. 예를 들어서 결제 완료 → 배달 시작 → 배달 완료로 변경되는 하나의 프로세스가 있다고 하면 이 프로세스도 POST 메서드를 사용해서 변경됩니다.
하지만, 프로세스를 처리하는 것이기에 POST의 결과로 새로운 리소스가 생성되지 않을 수 있습니다. 하지만 POST를 통해서 무조건 새로운 리소스가 생성되어야 하는 건 아니기 때문에 생성되지 않아도 괜찮습니다.
이러한 시작 라인이 있다고 칩시다. POST 메서드를 사용해서 요청을 보내는데 URI 모양이 이상합니다. start-delivery 라고 되어 있네요. 아까 분명 행위는 리소스가 될 수 없다고 했는데 행위가 리소스로 들어가 있네요.

리소스만으로 URI 설계가 불가능하다면 동사 URI가 나올 수도 있습니다. 리소스로 최대한 설계하되, 어쩔 수 없는 경우에는 control URI를 사용해서 설계합니다.
3.
다른 메서드로 처리하기 애매한 경우
예를 들어서 JSON으로 조회 데이터를 넘겨야 하는데, 조회하고 싶은 데이터를 쿼리 파라미터말고 메시지 바디에 넣고 싶다고 가정해봅시다. 하지만 이전에도 얘기했듯이 GET 메서드가 메시지 바디를 가지고 있는걸 지원하지 않는 서버가 존재할 수 있습니다. 이런 경우에는 조회시에 POST 메서드를 사용합니다. POST 메서드를 사용하면서 메시지 바디에 조회용 데이터를 넘깁니다. POST로 들어왔지만 서버는 조회를 원하는 데이터를 응답 메시지로 보내줄 겁니다.
POST는 메시지를 내부에 넣어서 하는 모든 것들이 가능합니다. 하지만 각 메서드가 가지고 있는 역할이 있고 서버끼리 역할에 따라서 약속한 부분들도 존재하기 때문에 각 메서드의 역할에 따라서 HTTP 메서드를 사용해야 합니다. POST를 사용해서 정보를 조회할 수도 있겠지만, 우리에게는 GET 메서드가 존재합니다. GET 으로 조회해야 유리한 부분도 있습니다. 서버끼리 GET 메서드를 사용해서 데이터를 조회하면 해당 데이터를 캐싱하겠다는 약속을 했습니다. 따라서 GET 메서드를 사용했을 시에는 데이터 조회 시에 데이터가 캐싱됩니다. POST는 자동으로 그런 기능을 넣어주지 않습니다. 따라서 최대한 해당 역할을 해주는 메서드를 사용하는게 좋습니다.
그 외 데이터 변경, 프로세스 진행, 어쩔 수 없는 경우에는 POST를 사용하시면 됩니다.
PUT
PUT은 리소스를 대체할 때 사용합니다. 리소스를 대체한다는 건 파일 복사를 생각하시면 됩니다.
우리가 어떤 폴더에 파일을 하나 넣는다고 합시다. 만약 해당 파일이 존재하지 않는다면 새로 생성될거고, 존재했다면 덮어쓰기 될 겁니다. 이게 바로 PUT 이 하는 일입니다.
PUT은 해당 위치에 리소스가 없다면 데이터를 신규 생성하고, 있다면 기존 데이터를 없애고 새로운 데이터를 덮어씁니다. 완전히 대체해버리는거죠.
그렇다면 POST 메서드와의 차이점은 뭔가요?
중요한 차이점은 PUT 메서드는 클라이언트가 구체적인 리소스 전체 경로를 알고 있다는 점입니다. 리소스 전체 경로를 알고 URI를 지정합니다.
이 부분이 POST 메서드와의 가장 큰 차이점입니다. POST는 /members 까지만을 URI로 사용합니다. 서버에서 해당 데이터를 100번에 넣어줄 지, 200번에 넣어줄 지 모르기 때문입니다.
PUT은 URI를 딱 지정합니다. 클라이언트가 리소스를 식별할 수 있기 때문입니다. 클라이언트가 /members/100 이라는 리소스를 알고 있기 때문에 가능합니다.
우리가 PUT 메서드를 누군가에게 설명해야한다면 2가지 특징을 말해주면 됩니다. ⓵ 리소스를 대체한다는 점, ⓶ 클라이언트가 리소스를 알고 있어야 한다는 점 입니다.
상황 1) PUT 메서드를 사용해서 유저 대체(리소스가 있는 경우)
1.
클라이언트에서 서버로 데이터를 보냅니다. PUT 메서드를 사용해서 /members 의 100번째 자리로 데이터를 보낼겁니다.
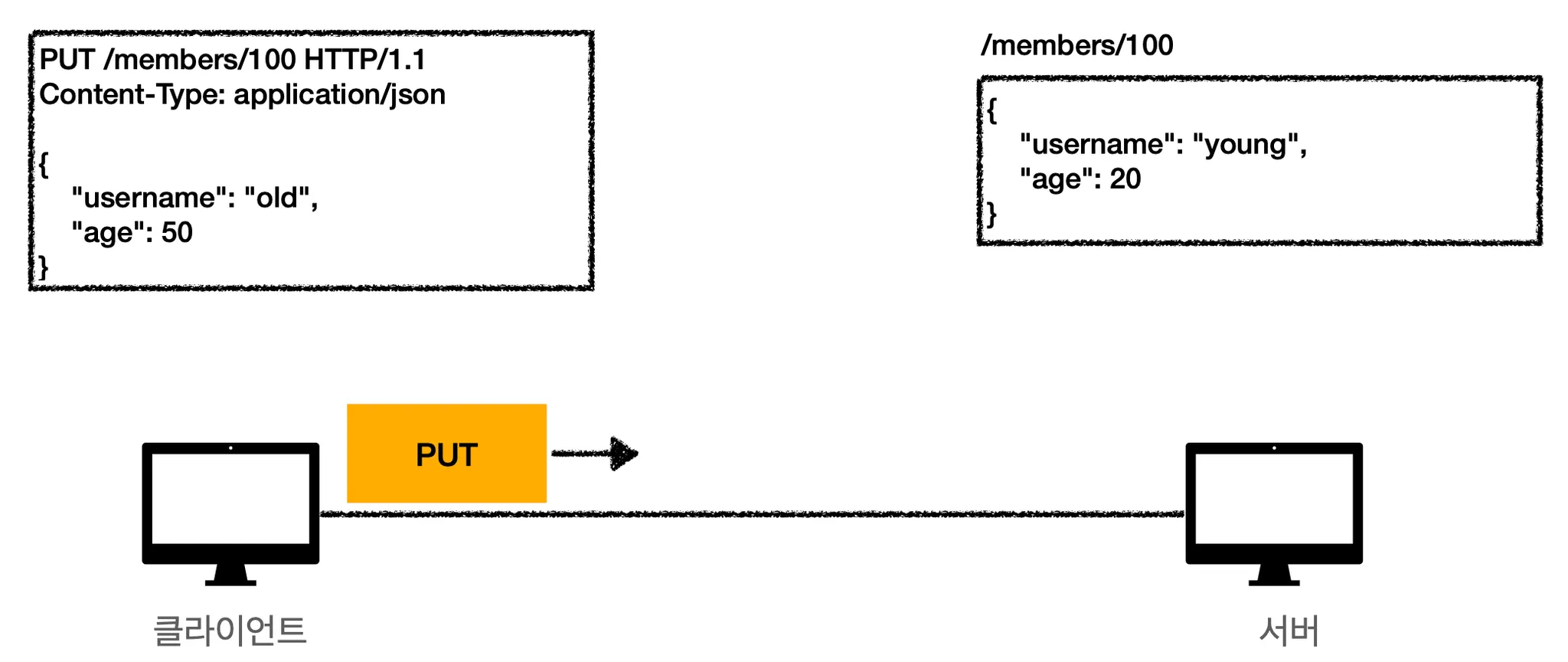
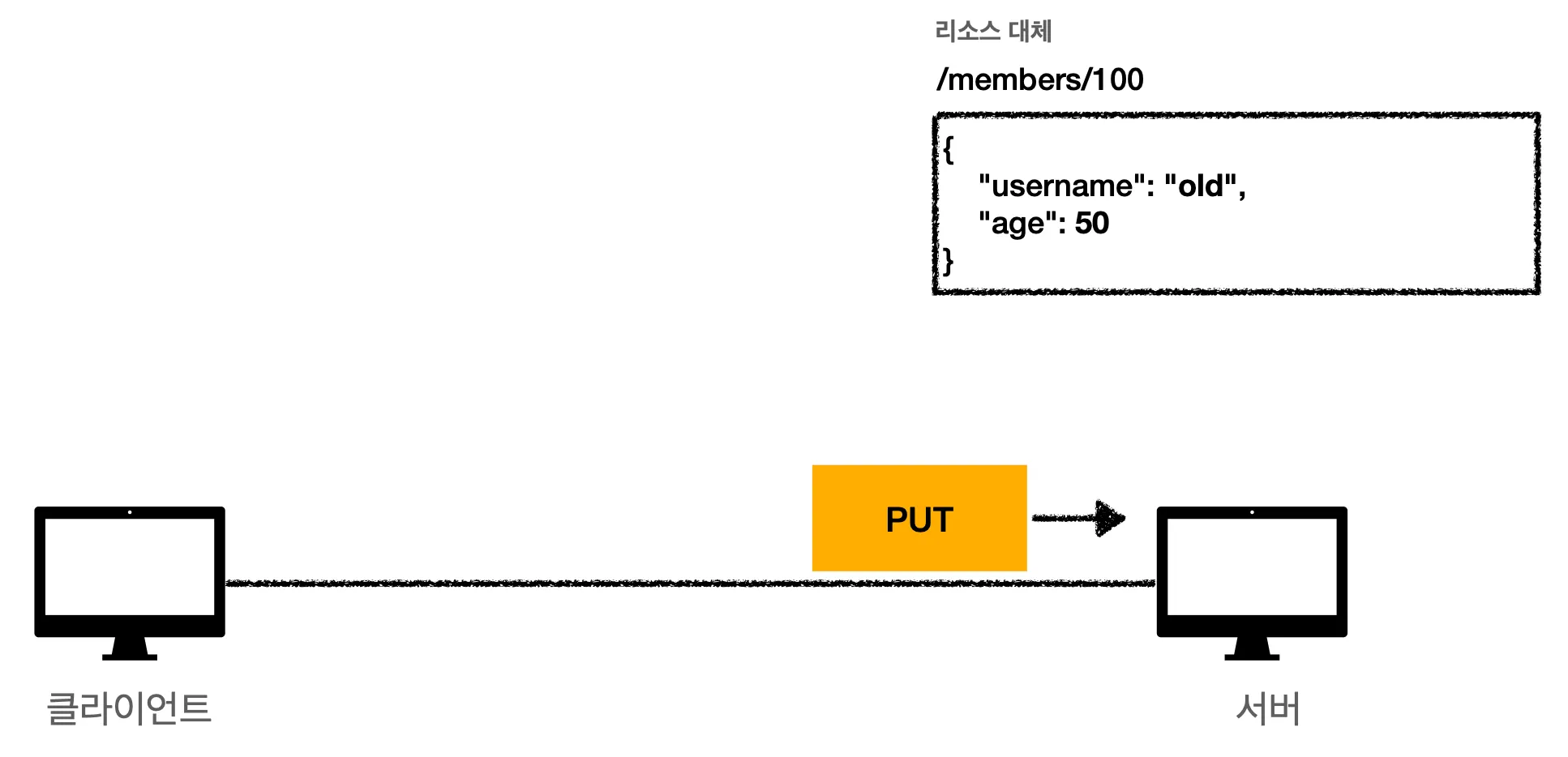
2.
해당 자리에는 이미 데이터가 있기 때문에 해당 데이터는 새로운 데이터로 대체될 겁니다.
상황 2) PUT 메서드를 사용해서 유저 생성(리소스가 없는 경우)
1.
클라이언트에서 서버로 데이터를 보냅니다. PUT 메서드를 사용해서 /members 의 100번째 자리로 데이터를 보낼겁니다.
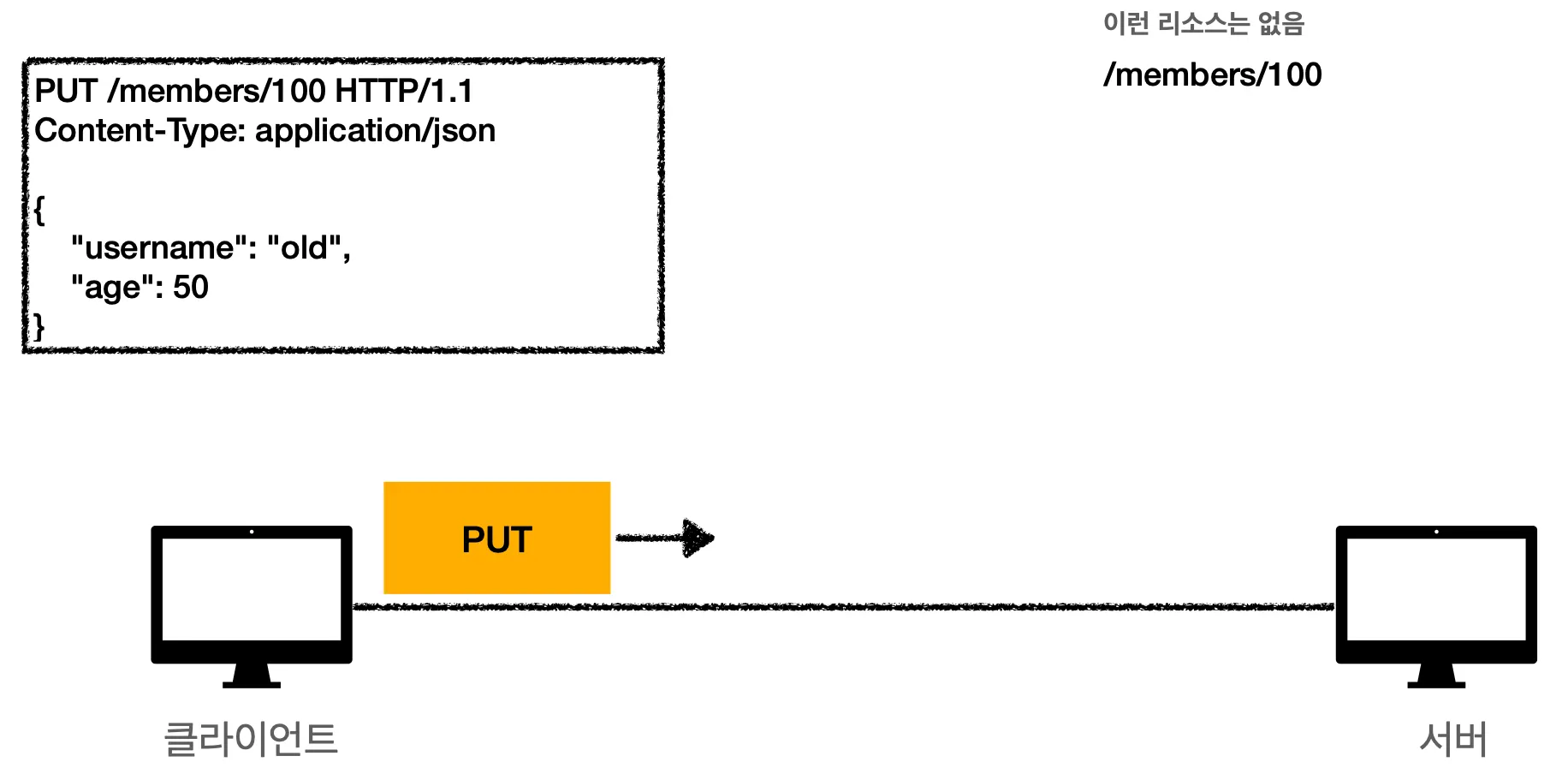
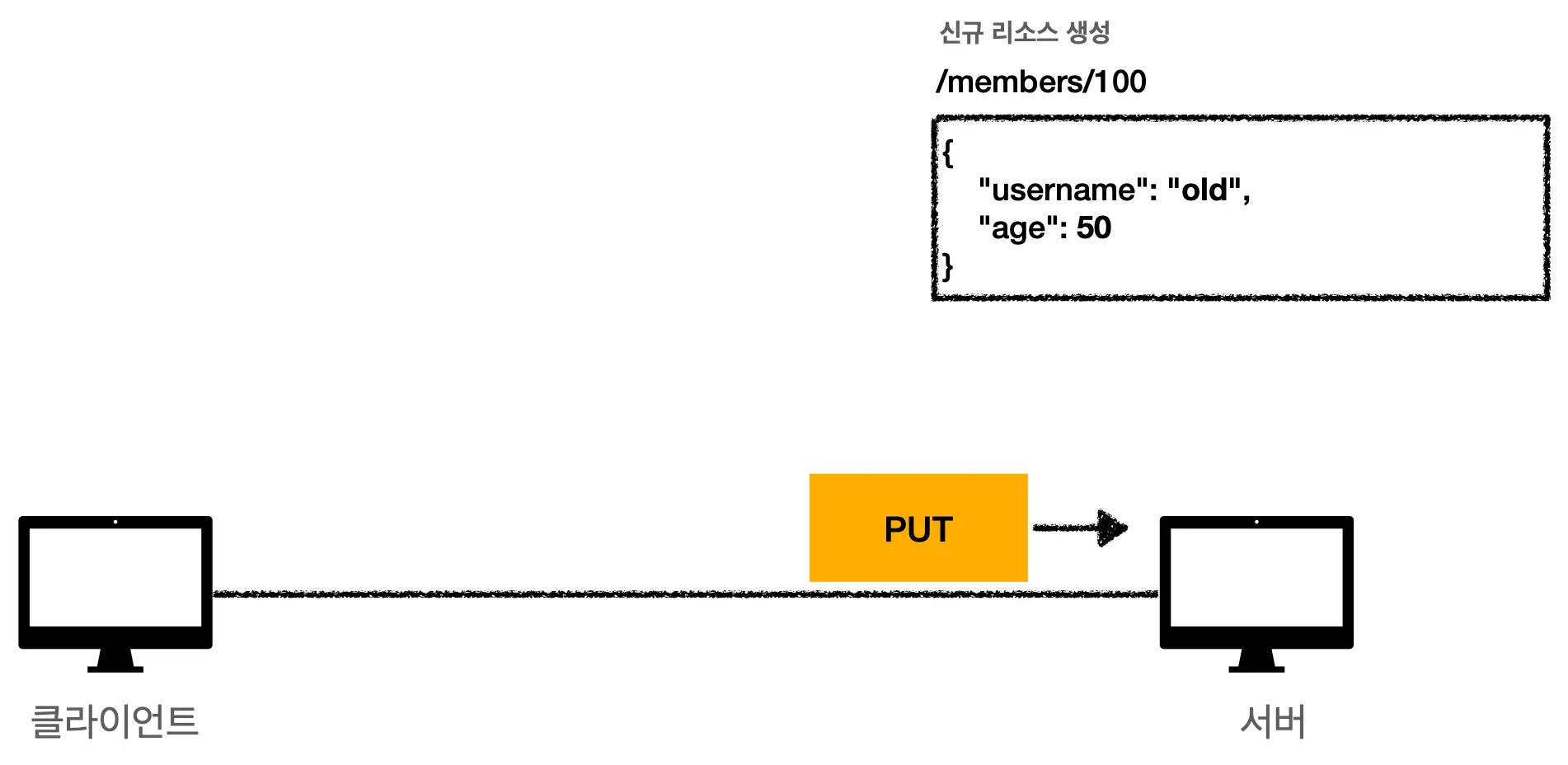
2.
해당 자리에는 데이터가 없었기 때문에 해당 데이터는 새로운 데이터로 생성될 겁니다.
상황 3) PUT 메서드를 사용해서 유저 대체(모든 필드값이 없을 경우)
1.
클라이언트에서 서버로 데이터를 보냅니다. PUT 메서드를 사용해서 /members 의 100번째 자리로 데이터를 보낼겁니다. username 필드는 수정하지 않을거라서 수정을 하고 싶은 age 부분만 데이터를 넣어서 보냈습니다.
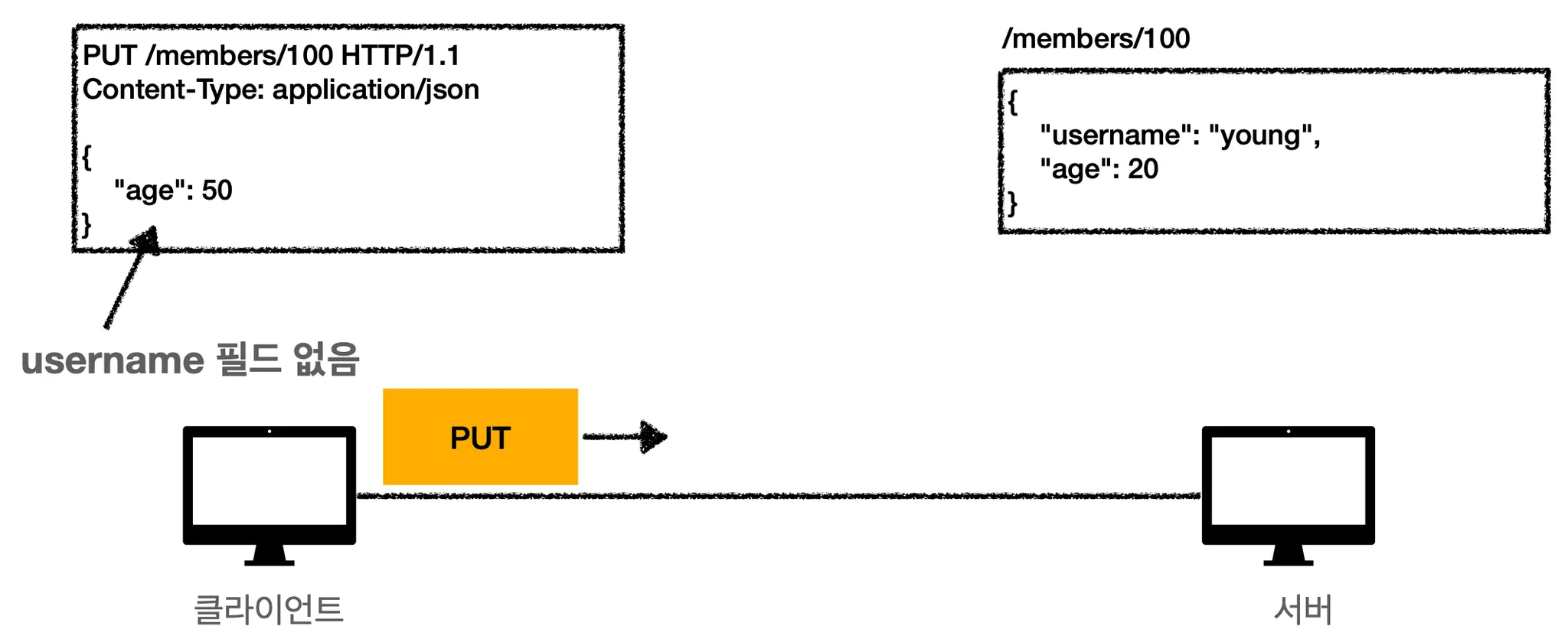
2.
username 필드가 삭제되었습니다. PUT 이 기존 리소스를 삭제하고 완전히 덮어버리기 때문에 필드 자체가 삭제된겁니다.
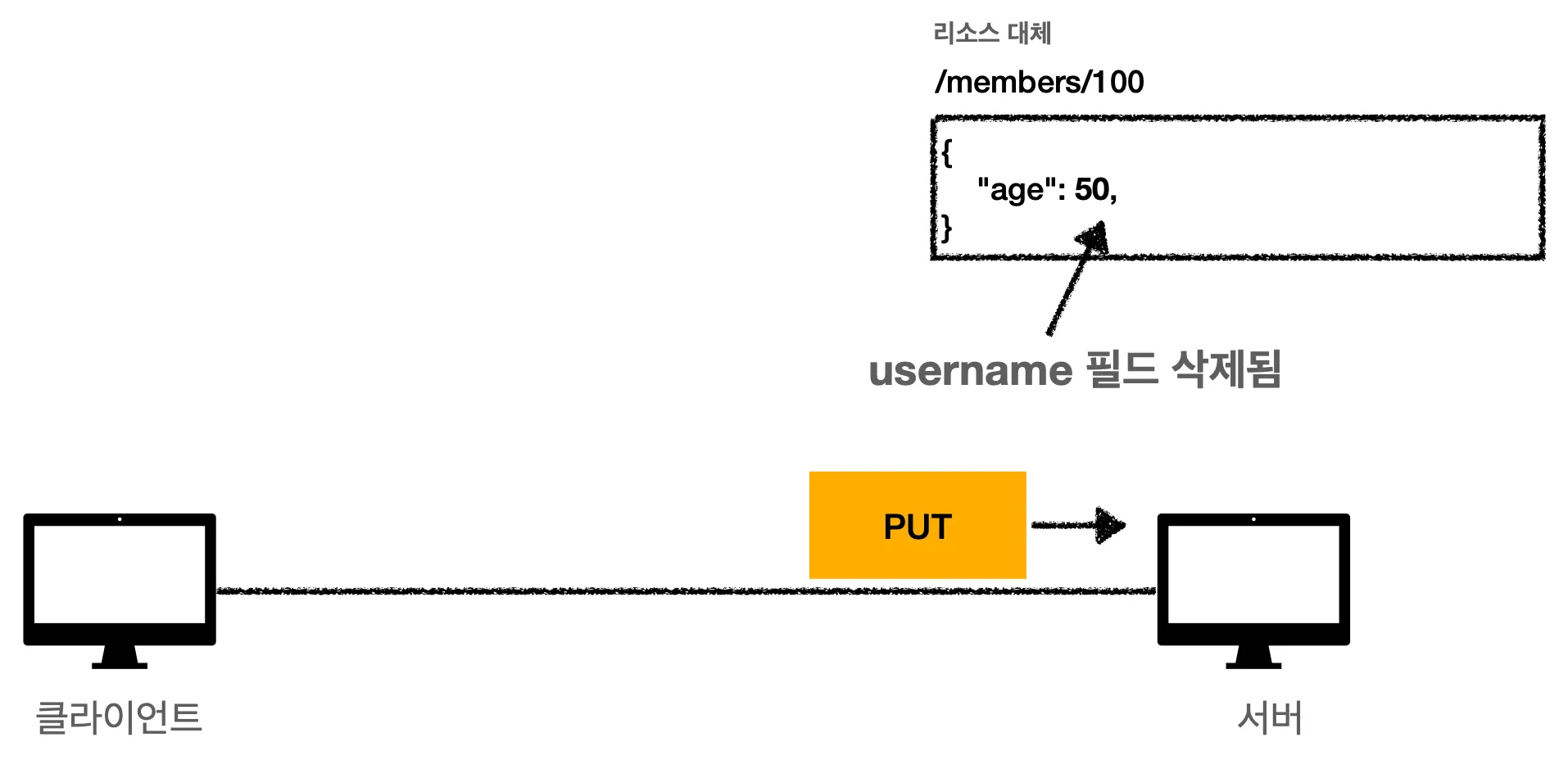
이렇게 되면 리소스를 수정하기 어려워집니다. 리소스를 수정하려면 수정하지 않을 데이터도 다 보내주어야 하니깐요.
눈치를 채셨겠지만 PUT 메서드는 리소스를 수정하는 메서드가 아닙니다. 기존 리소스를 갈아치우는 일을 하는 메서드입니다. 그렇다면 진짜로 수정을 하고 싶다면 어떻게 해야 할까요?
PATCH
바로 이 메서드를 사용하시면 됩니다. PATCH 입니다. PATCH는 리소스를 부분 변경합니다.
아까 PUT의 상황3을 PATCH 메서드를 사용해서 진행해보겠습니다.
상황) PATCH 메서드를 사용해서 유저 수정
1.
클라이언트에서 서버로 데이터를 보냅니다. PATCH 메서드를 사용해서 /members 의 100번째 자리로 데이터를 보낼겁니다. username 필드는 수정하지 않을거라서 수정을 하고 싶은 age 부분만 데이터를 넣어서 보냈습니다.
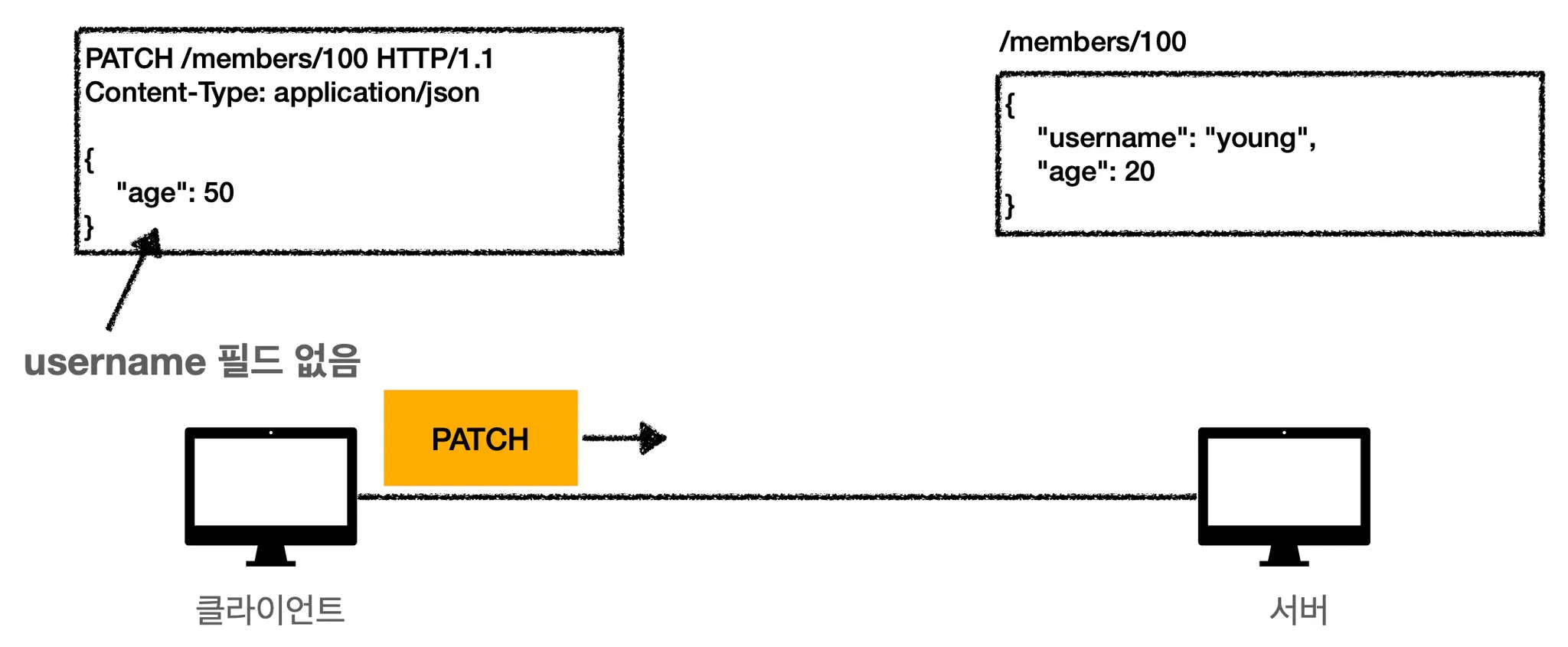
2.
수정을 원하는 age 부분만 변경되었습니다. ᐠ( ᐕ )ᐟ
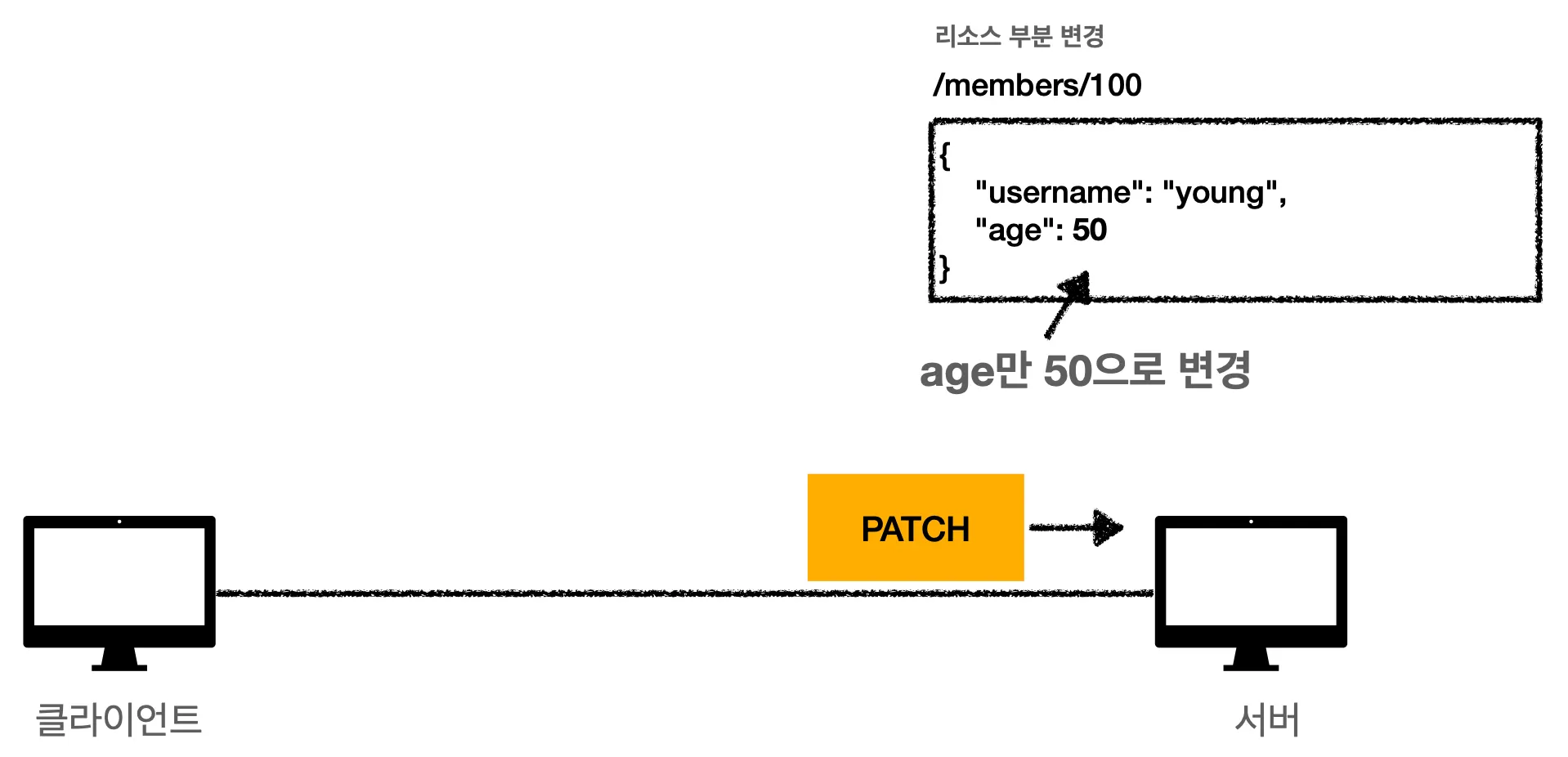
PATCH는 수정 시에 사용하면 되는데, PATCH 메서드를 지원하지 않는 서버가 있을 경우에는 HTTP에서 PATCH 자체를 받아들이지 못하는 문제가 생길 수 있습니다. 그런 경우에는 POST 메서드를 사용하면 됩니다.
DELETE
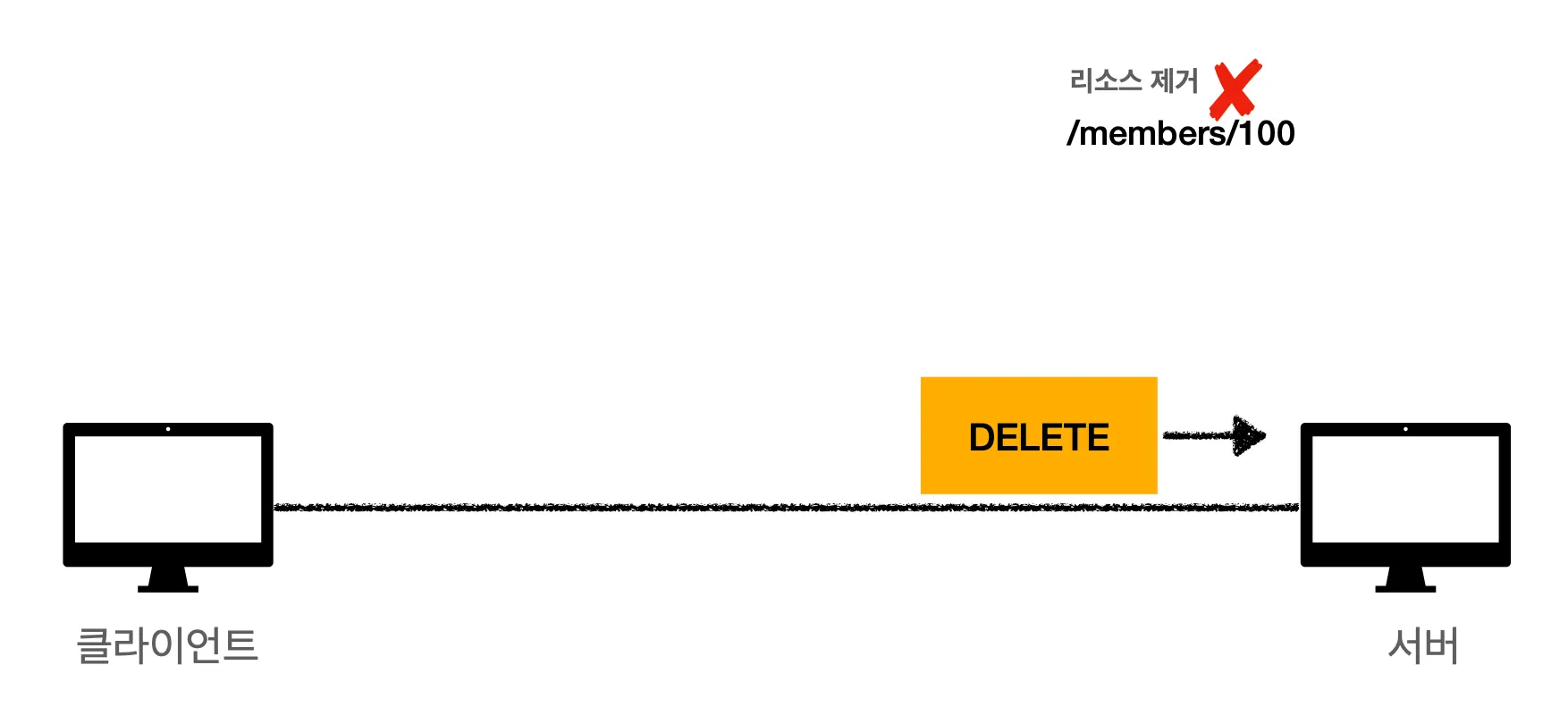
DELETE는 리소스를 제거할 때 사용합니다.
상황) DELETE 메서드를 사용해서 유저 삭제
1.
DELETE 메서드를 사용해서 /members에 100번 유저를 삭제하겠다는 요청을 보냅니다.
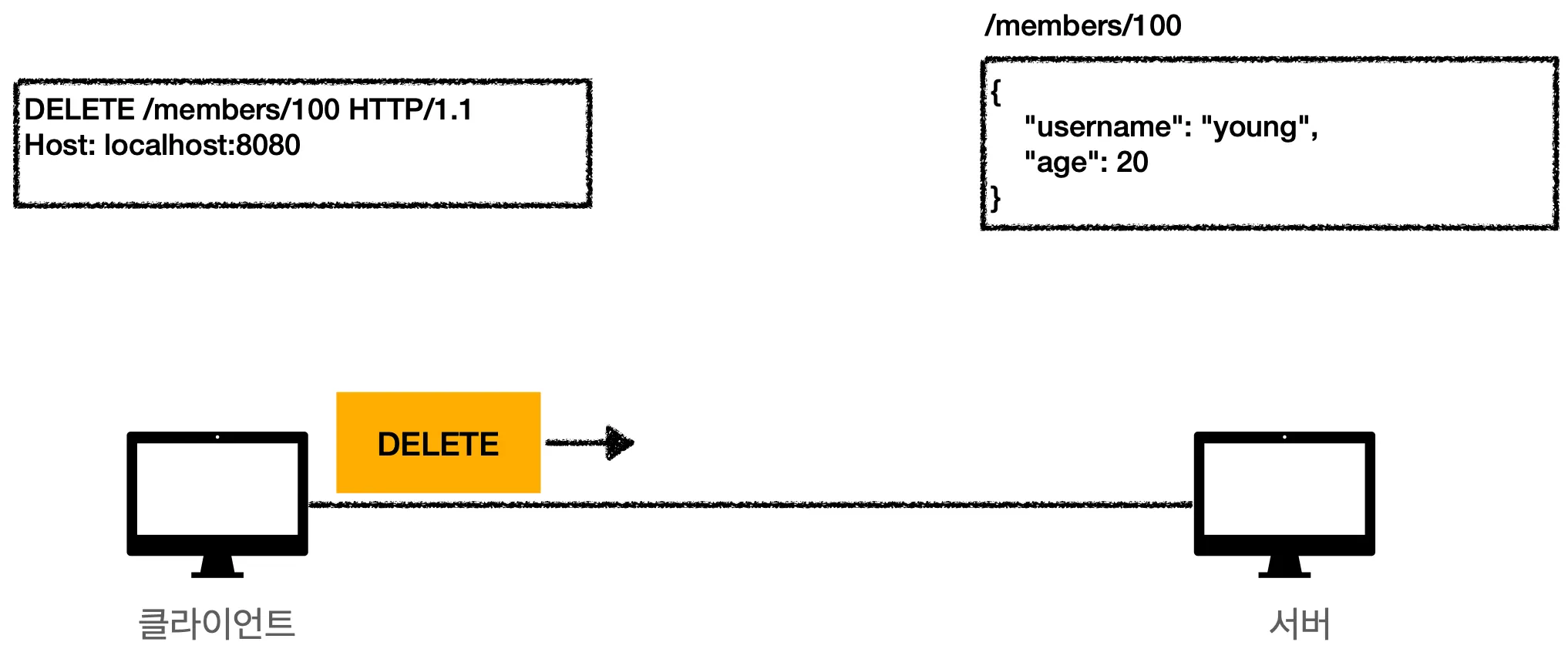
2.
요청을 받은 서버는 100번 유저를 삭제해버립니다.
HTTP 메서드의 속성
HTTP 메서드는 이러한 속성들이 있습니다.
•
안전(Safe)
•
멱등(Idempotent)
•
캐시 가능(Cacheable)
각 속성을 봤을 때 어떤 속성이겠거니 하고 생각이 되는 부분이 있으신가요? 저는 처음 속성을 봤을 때 감이 잡히는 것이 없었습니다. 특히, 멱등이라는 단어는 살면서 처음 들어봤습니다. 이번 섹션에서는 각 속성에 대한 자세한 내용을 알아보겠습니다.
HTTP 메소드가 어떠한 속성을 지녔고, 어떠한 속성을 지니지 못했는지 각 속성에 대한 설명과 함께 알아보겠습니다.
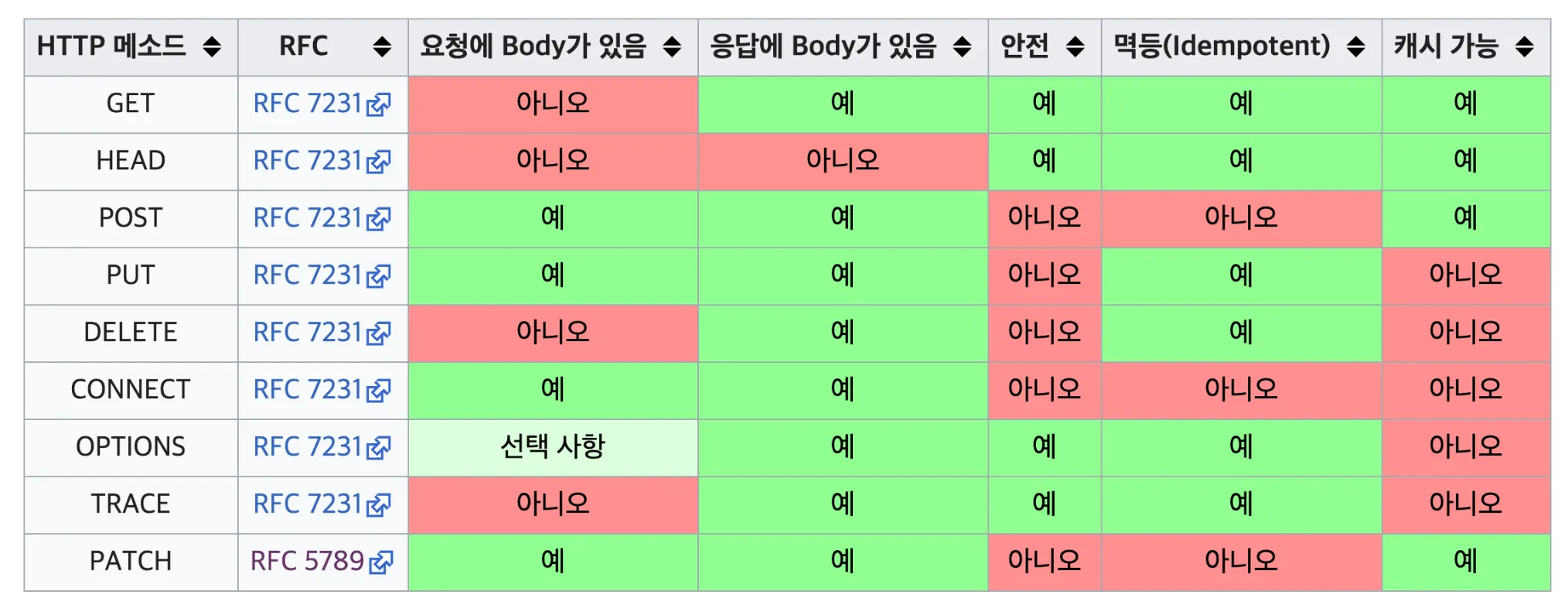
https://ko.wikipedia.org/wiki/HTTP
안전(Safe)
안전은 호출해도 리소스가 변경되지 않는다는 걸 뜻합니다.
GET 메서드를 생각해보면, 단순 조회이기 때문에 호출해도 리소스가 변경될 수 없어서 안전합니다.
그렇다면, POST, DELETE, PUT, PATCH는 어떨까요? 해당 메서드들은 안전하지 않습니다. 여러 번 호출하면 리소스에 변경이 일어나기 때문에 안전하지 않다고 볼 수 있습니다.
GET, HEAD 메서드는 안전하다고 볼 수 있는데, 단순 조회정도만 하기 때문에 리소스를 변경하지 않아서 그렇습니다.
아마 이런 질문이 들 수도 있습니다.
계속 호출을 하다보면 서버에 로그가 쌓여서 장애가 발생할 수 있는데 그렇다면 안전하지 않은거 아닌가요?
안전은 그런 부분까지 고려하진 않습니다. 그냥 해당 리소스가 변하는지, 변하지 않는지만 고려합니다. 서버에 쌓인 로그로 인한 장애까지 생각하며 정할 수 있는게 없습니다. 우리는 대상 리소스가 변하지 않는지만 보면 됩니다.
멱등(Idempotent)
멱등은 한 번 호출하든, 두 번 호출하든, 100번 호출하든 결과가 똑같아야 한다는 걸 의미합니다.
GET 메서드는 언제든지 똑같은 결과가 조회됩니다. 왜냐하면 조회만 했기 때문입니다. 결과가 바뀔 수가 없습니다.
PUT 메서드도 멱등합니다. PUT 메서드는 기존에 있는 데이터를 대체하는 메서드인데, 이게 어떻게 멱등할 수 있는지 궁금하실겁니다. 예를 들어볼게요. 파일을 업로드하는 상황이라고 가정해봅시다.
파일 A를 올리고 똑같은 파일 A를 업로드했습니다. 아마 두 번째 A를 업로드할 때는 기존 거를 날리고 두 번째 A를 위에 덮었을 겁니다. 그러면 아마도 같은 결과가 나올겁니다. 결국 덮어쓴 파일 A도 이전에 있던 파일 A와 같은 내용을 가진 같은 파일이니깐요. 여러번 똑같은 파일 A를 업로드해도 결과가 같을겁니다. 즉, 최종 결과물이 동일합니다.
DELETE 메서드도 멱등합니다. DELETE는 특정 리소스를 삭제합니다. 여러번 DELETE를 해도 삭제된 상태로 존재합니다. 최종적으로는 모두 삭제된 상태입니다.
하지만, POST는 멱등하지 않습니다.
만약, 사용자가 결제 버튼을 눌렀는데, 결제 버튼이 중복 눌려서 POST가 두번 실행되면 중복 결제가 발생할 겁니다. 즉, 한 번 호출하면 정상적으로 결제가 되지만, 두 번 호출하게 되면 정상 결제가 아닌 중복 결제가 발생하니 문제가 생기는 겁니다. POST는 몇 번을 하느냐에 따라서 결과가 동일하게 발생하지 않습니다.
그럼 멱등은 언제 사용하는걸까요? 왜 필요한 개념일까요?
자동 복구 매커니즘을 생각해봅시다.
⓵ DELETE 호출을 했습니다.
⓶ 서버에서 응답이 오지 않았습니다.
⓷ 잘 됐는지, 안 됐는지 알 수 없어서 자동으로 DELETE를 재시도했습니다.
⓸ 이렇게 해도 괜찮나요..?
그래도 괜찮습니다. 왜냐하면 멱등하기 때문입니다. 멱등하기 때문에 같은 요청을 두 번해도 괜찮습니다. 그렇기 때문에 자동으로 재시도를 시켜주는, 즉 같은 요청을 두 번, 세 번 호출해주는 자동 복구 매커니즘을 사용해도 됩니다. 이런 매커니즘이 있는 곳에서는 멱등한 메서드들은 사용해도 괜찮습니다.
하지만, POST 같은 메서드는 자동 복구 매커니즘을 사용할 수 없겠죠. 자동 복구를 하려고 두 번, 세 번 호출을 하게 되면 문제가 생길 수도 있으니깐요.
그렇다면 이런 상황에서도 GET 메서드가 멱등하다고 볼 수 있을까요?
만약, 재요청 중간에 다른 곳에서 리소스를 변경한다고 합시다.
⓵ GET 메서드를 사용해서 조회 → 계속 조회(동일한 결과)
⓶ PUT 메서드를 사용해서 데이터 변경
⓷ GET 메서드를 사용해서 조회 → 아까와 다른 결과 조회됨
이러면 멱등이 아니지 않나요? 아닙니다. 멱등은 외부 요인으로 중간에 리소스가 변경되는 것까지 고려하지 않습니다. 내가 동일한 요청을 똑같이 했을 때 똑같은지, 아닌지만을 고려합니다.
위의 예시에서는 중간에 외부 요인(PUT)이 생겨서 리소스가 변경되었습니다. 따라서 멱등이 아닙니다. ⓷에서 다른 결과가 조회되는 것이 오히려 맞습니다.
캐시가능(Cacheable)
캐시 가능은 응답 결과를 캐시해서 사용할 수 있는지에 대한 속성입니다.
만약, 웹 브라우저에서 큰 이미지를 요청했다고 칩시다. 사용자가 해당 이미지를 응답으로 받고 또 같은 리소스를 다시 요청한다고 했을 때 다시 이미지를 받아오려고 하면 시간이 오래 걸릴겁니다. 그럴 때 해당 이미지를 로컬 PC의 웹 브라우저가 저장하고 있는게 캐시입니다. 물론 중간 캐시 서버가 있을 수도 있지만 간단하게 웹 브라우저에서 내부에 이미지를 저장할 수 있느냐, 없느냐 만을 보도록 하겠습니다.
스펙 상으로는 GET, HEAD, POST, PATCH는 캐시 가능합니다. 하지만, 실제로는 GET, HEAD정도만 캐시로 사용 가능합니다.
왜냐하면, 캐시를 하기 위해서는 키가 맞아야 하는데, GET, HEAD는 URI만 키로 잡고 캐시하면 되기 때문에 단순하게 캐시를 할 수 있습니다. 하지만 POST, PATCH는 바디 안에 데이터까지 고려해야 하기 때문에 복잡합니다. 본문 내용까지 캐시 키로 고려해야하기 때문에 거의 캐시를 사용하지 않습니다.